GCNet: Global-local Temporal Modeling Enhanced 2DCNN with Category-supervised Contrastive Learning for Action Recognition
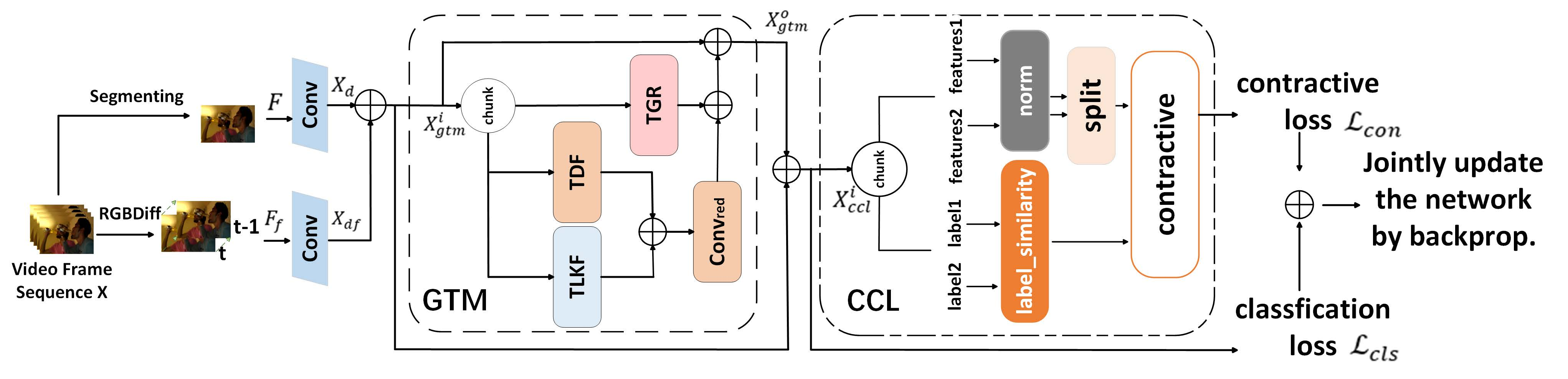
This PyTorch-implemented GCNet, a lightweight video action recognition framework, enhances 2DCNNs with two novel modules—Global-local Temporal Modeling (GTM) for unified global-local temporal feature extraction and Category-supervised Contrastive Learning (CCL) for discriminative feature learning—to achieve state-of-the-art accuracy without expensive 3D convolutions.
The environment is fully compatible with TDN and standard video understanding pipelines:c
-
Python ≥ 3.6
-
PyTorch ≥ 1.4
-
torchvision
-
tensorboardX
-
tqdm
-
scikit-learn
-
ffmpeg
-
decord
-
torchmetrics (for CCL loss)
-
wandb (optional, for visualization)
Install all dependencies:
pip install -r requirements.txtLarge weight files are excluded from GitHub due to size limits. Please download and place them as follows:
GCNet/
├─ resnet50-19c8e357.pth (torchvision official)
└─ kd_pretrained_models/
├─ clip-vit-base-patch32/
│ └─ pytorch_model.bin
└─ vit_base_patch16_224/
├─ pytorch_model.bin
└─ model.safetensorsGCNet is evaluated on three standard benchmarks:
-
UCF-101: 101 action classes, 13,320 videos
-
HMDB-51: 51 action classes, 6,849 videos
-
Something-Something-V1: 174 fine-grained interactive actions, 108,499 videos
Data preparation follows the TDN protocol:
-
Extract frames or use raw video files
-
Generate annotation files:
path num_frames label -
Update dataset paths in
ops/dataset_configs.py
| Model | Frames | Top-1 |
|---|---|---|
| GCNet-ResNet50 | 8 | 88.6% |
| GCNet-ResNet50 | 16 | 89.5% |
| Model | Frames | Top-1 |
|---|---|---|
| GCNet-ResNet50 | 8 | 59.9% |
| GCNet-ResNet50 | 16 | 59.2% |
| Model | Frames | Top-1 |
|---|---|---|
| GCNet-ResNet50 | 8 | 52.7% |
| GCNet-ResNet50 | 16 | 54.2% |
GCNet is developed based on the TDN codebase but with significantly improved performance via Global-local Temporal Modeling (GTM) and Category-supervised Contrastive Learning (CCL). Under the same backbone (ResNet-50), pretrain (ImageNet), and training settings, we compare GCNet with TDN as below:
| Method | Frames | Top-1 Accuracy | Improvement |
|---|---|---|---|
| TDN | 8 | 57.0% | — |
| GCNet (Ours) | 8 | 59.9% | +2.9% |
| TDN | 16 | 57.4% | — |
| GCNet (Ours) | 16 | 59.2% | +1.8% |
| Method | Frames | Top-1 Accuracy | Improvement |
|---|---|---|---|
| TDN | 8 | 87.0% | — |
| GCNet (Ours) | 8 | 88.6% | +1.6% |
| TDN | 16 | 88.3% | — |
| GCNet (Ours) | 16 | 89.5% | +1.2% |
| Method | Frames | Top-1 Accuracy | Improvement |
|---|---|---|---|
| TDN | 8 | 52.3% | — |
| GCNet (Ours) | 8 | 52.7% | +0.4% |
| TDN | 16 | 53.9% | — |
| GCNet (Ours) | 16 | 54.2% | +0.3% |
CUDA_VISIBLE_DEVICES=0 python test_models_center_crop.py ucf101 \
--archs resnet50 --weights YOUR_WEIGHTS.pth \
--test_segments 8 --test_crops 1 --batch_size 16CUDA_VISIBLE_DEVICES=0 python test_models_three_crops.py ucf101 \
--archs resnet50 --weights YOUR_WEIGHTS.pth \
--test_segments 8 --test_crops 3 --clip_index 0~9Aggregate results:
python pkl_to_results.py --num_clips 10 --test_crops 3python -m torch.distributed.launch --nproc_per_node=8 \
main.py ucf101 RGB \
--arch resnet50 --num_segments 8 \
--lr 0.0015 --lr_steps 25 35 --epochs 50 \
--batch-size 4 --wd 5e-4 \
--dropout 0.8 \
--no_partialbn \
--contrastive_loss True \
--category_supervised Truepython -m torch.distributed.launch --nproc_per_node=8 \
main.py hmdb51 RGB \
--arch resnet50 --num_segments 8 \
--lr 0.0015 --lr_steps 25 35 --epochs 50 \
--batch-size 4 --wd 5e-4 \
--dropout 0.8 \
--no_partialbn \
--contrastive_loss True \
--category_supervised Truepython -m torch.distributed.launch --nproc_per_node=8 \
main.py something RGB \
--arch resnet50 --num_segments 8 \
--lr 0.0025 --lr_steps 30 45 55 --epochs 60 \
--batch-size 8 --wd 5e-4 \
--dropout 0.8 \
--no_partialbn \
--contrastive_loss True \
--category_supervised True-
--contrastive_loss True: Enable CCL module -
--contrastive_temperature 0.1: Temperature for contrastive loss -
--category_supervised True: Use label-guided contrastive learning -
--num_segments 8: Sparse 8-frame sampling (best speed–accuracy tradeoff)
| GTM | CCL | HMDB-51 | UCF-101 |
|---|---|---|---|
| ✗ | ✗ | 57.0% | 87.0% |
| ✓ | ✗ | 59.3% | 88.0% |
| ✗ | ✓ | 58.0% | 87.6% |
| ✓ | ✓ | 59.9% | 88.6% |
Our code is built on:
@inproceedings{wang2021tdn,
title={Tdn: Temporal difference networks for efficient action recognition},
author={Wang, Limin and Tong, Zhan and Ji, Bin and Wu, Gangshan},
booktitle={Proceedings of the IEEE/CVF conference on computer vision and pattern recognition},
pages={1895--1904},
year={2021}
}
@article{wang2018temporal,
title={Temporal segment networks for action recognition in videos},
author={Wang, Limin and Xiong, Yuanjun and Wang, Zhe and Qiao, Yu and Lin, Dahua and Tang, Xiaoou and Van Gool, Luc},
journal={IEEE transactions on pattern analysis and machine intelligence},
volume={41},
number={11},
pages={2740--2755},
year={2018},
publisher={IEEE}
}