Algoritmos de classificação são utilizados para mapear elementos semelhantes em categorias específicas. Neste trabalho, serão abordados os seguintes algoritmos: kNN , Random Forest , Naive Bayes , Decision Tree e Perceptron , cujos testes foram feitos na plataforma Jupyter Notebook e a classificação individual de cada classificador fora feita baseada na sua acurácia.
A base de dados escolhida para os experimentos é a Pima Indians Diabetes, que é composta por informações referentes a mulheres com pelo menos 21 anos de idade, cuja origem é indígena dos povos Pima. Nela, estão inseridas 768 instâncias (número de linhas) com 9 atributos cada, sendo que o último, informa se a pessoa possui a doença ou não. Todos os atributos são preenchidos com valor numérico e correspondem a:
Classificação é um método que aprende uma função, em termos matemáticos, com valores de atributos em seu domínio e valores de classe em sua imagem. Em outras palavras, dado um conjunto de valores de atributos, tal função determina um valor de classe para esse conjunto. Essa função é também conhecida como modelo de classificação (SILVA, 2007).
Essa classificação é feita através de algoritmos de aprendizagem. Esses algoritmos conseguem “criar conhecimento” sobre o domínio tratado através de dados de entrada. Quando esses dados de entrada já possuem suas classes atribuídas dizemos que essa é uma aprendizagem supervisionada. Dessa forma, o algoritmo consegue criar uma relação entre as características de cada entrada com a sua classe final, gerando um “conhecimento” para fazer previsões sobre entradas que ainda não possuem uma classe definida. Esses dados de entrada já classificados são chamados de base de treino enquanto que os documentos que serão classificados posteriormente ao treino são denominados como a base de teste (SANTOS, 2013).
Quando a base de treino não possui uma classificação pré-definida são utilizados algoritmos de aprendizagem não-supervisionada. Nesse caso, os algoritmos tentam agrupar entradas com características semelhantes e classificá-los por grupos. Esse tipo de classificação é chamada de clusterização (SANTOS, 2013).
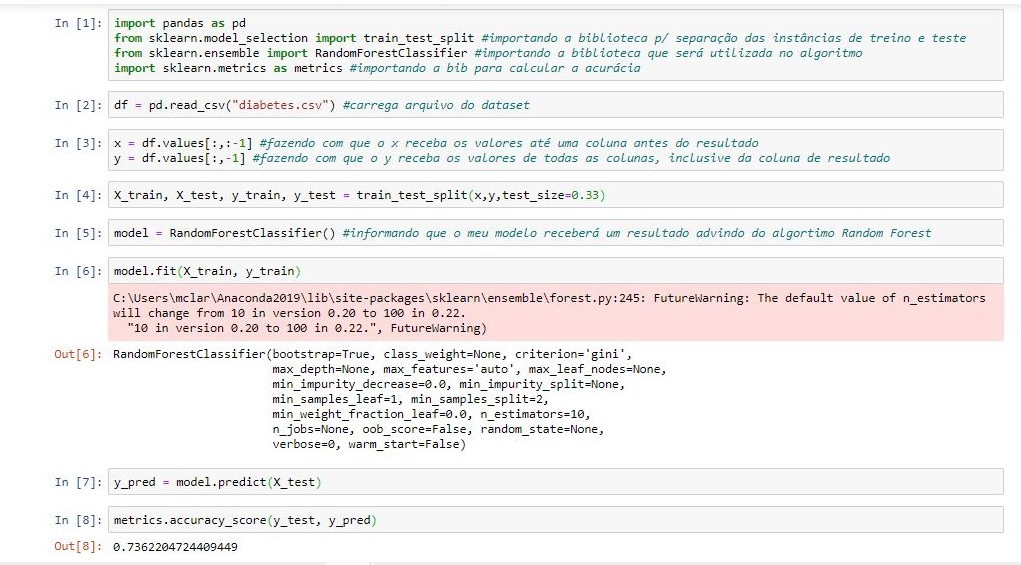
O algoritmo Random Forest trata-se de um classificador que faz uso do método de árvores de decisão criada por Breiman (2001) possibilitando a mineração dos dados. Esta técnica possui uma ideia um pouco diferente dos algoritmos de árvores de decisão, enquanto uma árvore possui o objetivo de construção total de uma estrutura a partir de uma base de dados, o Random Forest tem o objetivo de efetuar a criação de várias árvores de decisão usando um subconjunto de atributos selecionados aleatoriamente a partir do conjunto original, contendo todos os atributos e que estes possuem um tipo de amostragem chamado de bootstrap, a qual é do tipo com reposição, possibilitando assim melhor análise dos dados. (NETO, 2014).Figura 1 - Uso do algoritmo Random Forest
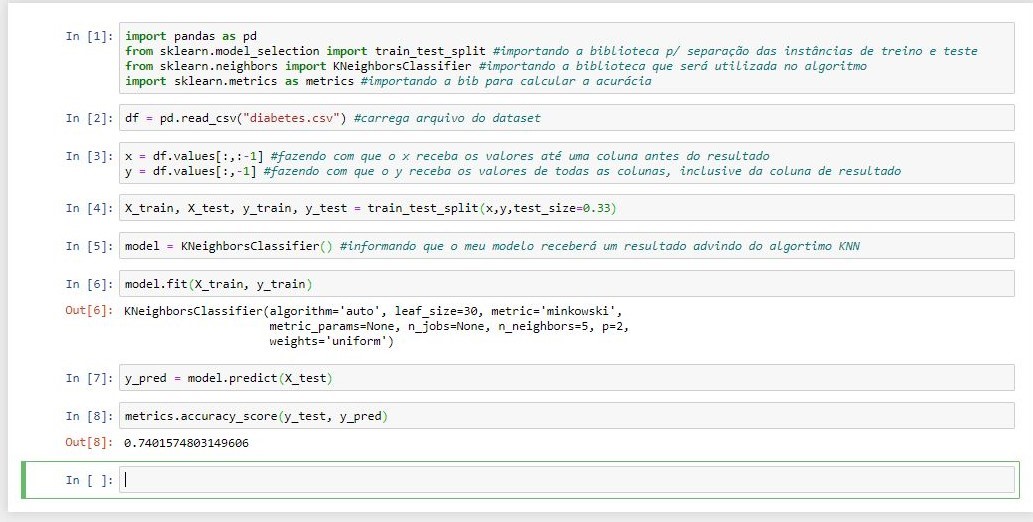
O algoritmo k-Nearest Neighbor (kNN) é um algoritmo de aprendizado supervisionado do tipo lazy. A ideia geral desse algoritmo consiste em encontrar os k exemplos rotulados mais próximos do exemplo não classificado e, com base no rótulo desses exemplos mais próximos, é tomada a decisão relativa à classe do exemplo não rotulado. Os algoritmos da família kNN requerem pouco esforço durante a etapa de treinamento. Em contrapartida, o custo computacional para rotular um novo exemplo é relativamente alto, pois, no pior dos casos, esse exemplo será comparado com todos os exemplos contidos no conjunto de treinamento (FERRERO, 2009).
Figura 2 - Uso do algoritmo kNN
O algoritmo Decision Tree ou Árvore de Decisão é uma representação simples de um classificador utilizada por diversos sistemas de aprendizado de máquina. Uma árvore de decisão é induzida a partir de um conjunto de exemplos de treinamento onde as classes são previamente conhecidas.
A estrutura da árvore é organizada de tal forma que:
a) cada nó interno (não-folha) é rotulado com o nome de um dos atributos previsores; b) os ramos (ou arestas) saindo de um nó interno são rotulados com valores do atributo naquele nó; c) cada folha é rotulada com uma classe, a qual é a classe prevista para exemplos que pertençam àquele nó folha.O processo de classificação de um exemplo ocorre fazendo aquele exemplo “caminhar” pela árvore, a partir do nó raiz, procurando percorrer os arcos que unem os nós, de acordo com as condições que estes mesmos arcos representam. Ao atingir um nó folha, a classe que rotula aquele nó folha é atribuída àquele exemplo (CARVALHO, 2005).
Figura 3 - Uso do algoritmo Decision Tree

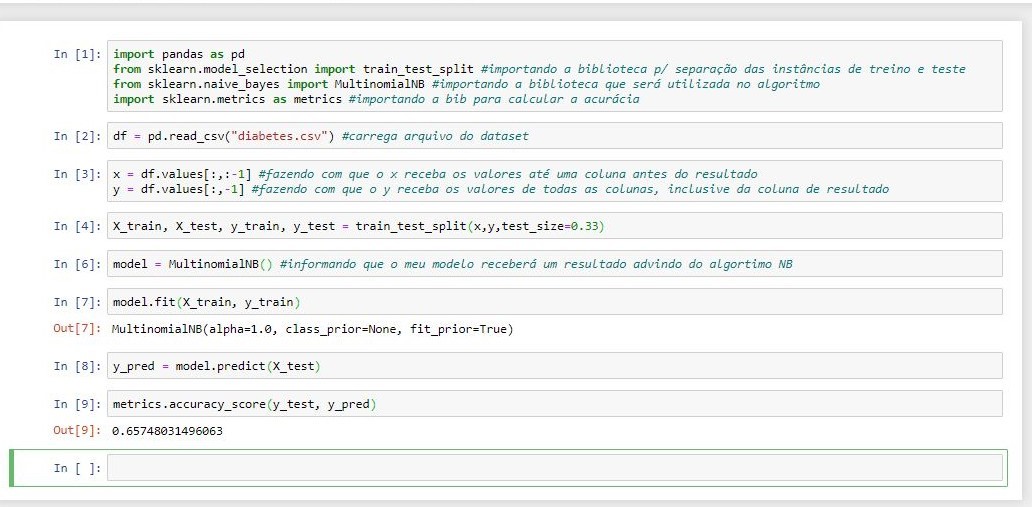
O algoritmo Naive Bayes é um classificador probabilístico simples que calcula um conjunto de probabilidades contando a frequência e as combinações de valores em um determinado conjunto de dados. O algoritmo usa o teorema de Bayes e assume que todos os atributos são independentes, dado o valor da variável de classe. Essa suposição de independência condicional raramente é verdadeira em aplicações do mundo real, daí a caracterização como ingênua, mas o algoritmo tende a ter um bom desempenho e aprender rapidamente em vários problemas de classificação supervisionada. Essa "ingenuidade" permite que o algoritmo construa facilmente classificações a partir de grandes conjuntos de dados sem recorrer a esquemas de estimativa de parâmetros iterativos complicados (DIMITOGLOU; ADAMS & JIM, 2012).
Figura 4 - Uso do algoritmo Naive Bayes
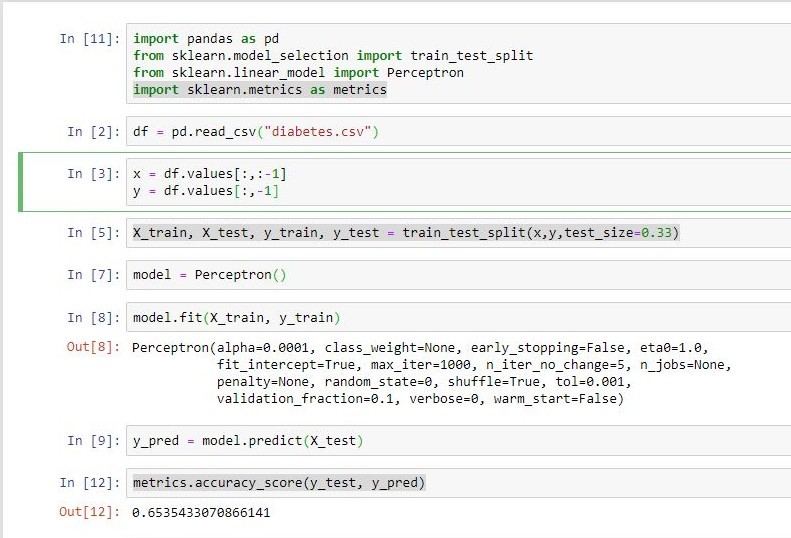
O Perceptron consiste em uma única camada de neurônios com pesos sinápticos e bias ajustáveis. Se os padrões de entrada forem linearmente separáveis, o algoritmo de treinamento do Perceptron possui convergência garantida, ou seja, é capaz de encontrar um conjunto de pesos que classifica corretamente os dados. Os pesos dos neurônios que compõem o Perceptron serão tais que as superfícies de decisão produzidas pela rede neural estarão apropriadamente posicionadas no espaço (CASTRO F. & CASTRO M., 2001).
Figura 5 - Uso do algoritmo Perceptron
Como resultado obtido, observa-se que o algoritmo knn obteve a maior acurácia, seguido pelo Random Forest.
Quadro 1- Acurácia de cada algoritmo
| Algoritmo | Acurácia |
| Naive Bayes | 0.65748031496063 |
| kNN | 0.7401574803149606 |
| Decision Tree | 0.6811023622047244 |
| Perceptron | 0.6535433070866141 |
| Random Forest | 0.7362204724409449 |
SILVA, J. Algoritmos de classificação baseados em análise formal de conceitos. Master's thesis, Universidade Federal de Minas Gerais, 2007.
SANTOS, F. L. Mineração de opinião em textos opinativos utilizando algoritmos de classificação . 2013.
CASTRO, F. C. C.; CASTRO, M. C. F. Redes neurais artificiais . DCA/FEEC/Unicamp, 2001.
FERRERO, C. A. Algoritmo kNN para previsão de dados temporais: funções de previsão e critérios de seleção de vizinhos próximos aplicados a variáveis ambientais em limnologia . 2009. Tese de Doutorado. Universidade de São Paulo.
CARVALHO, D. R. Árvore de decisão/algoritmo genético para tratar o problema de pequenos disjuntos em classificação de dados . Universidade Federal do Rio de Janeiro, Rio de Janeiro, Brazil. Doctor Thesis. 162pp, 2005.
DIMITOGLOU, G.; ADAMS, J. A.; JIM, C. M. Comparison of the C4. 5 and a Naïve Bayes classifier for the prediction of lung cancer survivability . arXiv preprint arXiv:1206.1121, 2012.
NETO, C. D. G. Potencial de técnicas de mineração de dados para o mapeamento de áreas cafeeiras . INPE, São José dos Campos, 2014.