kaggle BBC news classify task
Text documents are one of the richest sources of data for businesses.
We’ll use a public dataset from the BBC comprised of 2225 articles, each labeled under one of 5 categories: business, entertainment, politics, sport or tech.
The dataset is broken into 1490 records for training and 735 for testing. The goal will be to build a system that can accurately classify previously unseen news articles into the right category. link to the kaggle BBC news classify competition -- https://www.kaggle.com/c/learn-ai-bbc/overview
This data was analysed ,processed ,converted to vector form using DOC2VEC gensim model. Then we trained it on different classification model like MLP,randomforest,logistic regression,etc. for different vector sizes 50,100,200,300 and noted that MUltilayer perceptron performed well in every case.So we saved the MLP model in .pickle file and used it in endproject (deployment time).
This was my accuracy score (pic from kaggle page) =>

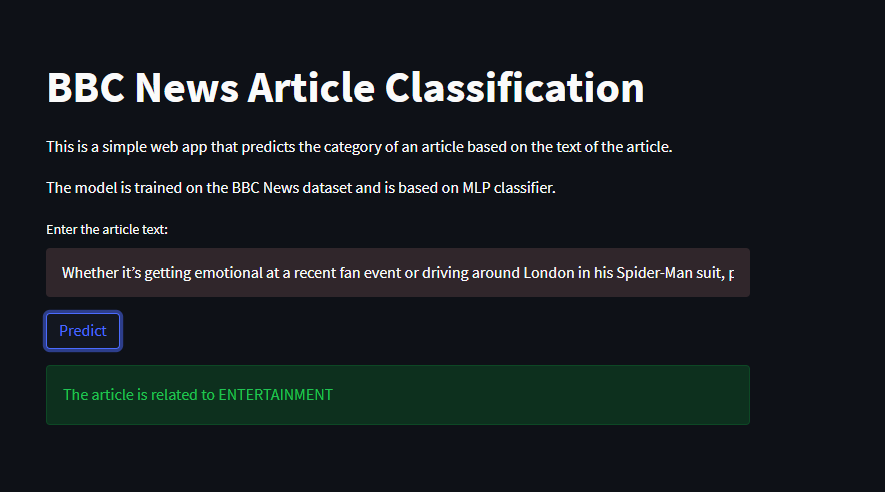
to check how this model works on new article ,proceed as per following steps:
---> 1) run the app.py using streamlit run app.py" command (if it fails then for windows use py -m streamlit run app.py)
---> 2) pick up some article from google, paste it in text input section and press prdict button
You will get result like this one......
**update:--------->>>>>>>>
This web app is now live(deployed with the heroku)
go to https://newtag123.herokuapp.com/