classification model based on MobileNet using tensorflow and keras
This dataset created by Lexset contains 27000 images of the alphabet signed in American Sign Language. Each image is 512 x 512. The data is separated into a training and testing set. Within each set, there are 27 folders, one for each letter and an extra folder of random backgrounds. Each training folder contains 900 examples while each testing folder contains 100 examples.
These images were created using Lexset's synthetic data generation platform Seahaven: https://seahaven.lexset.ai/

ASL_inference.mp4
Train and Validation Accuracy Plots :
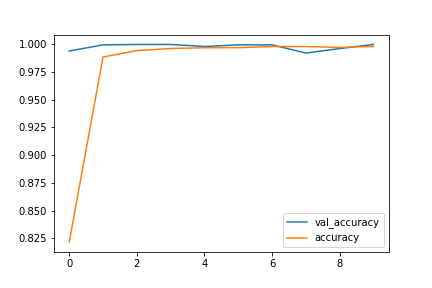
Train and Validation Loss Plots :
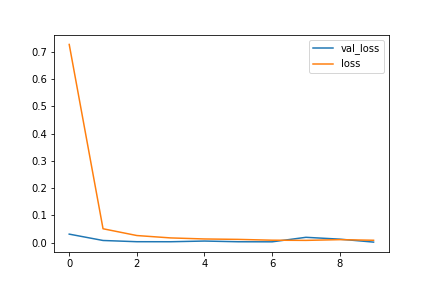
Confuse Matrix :
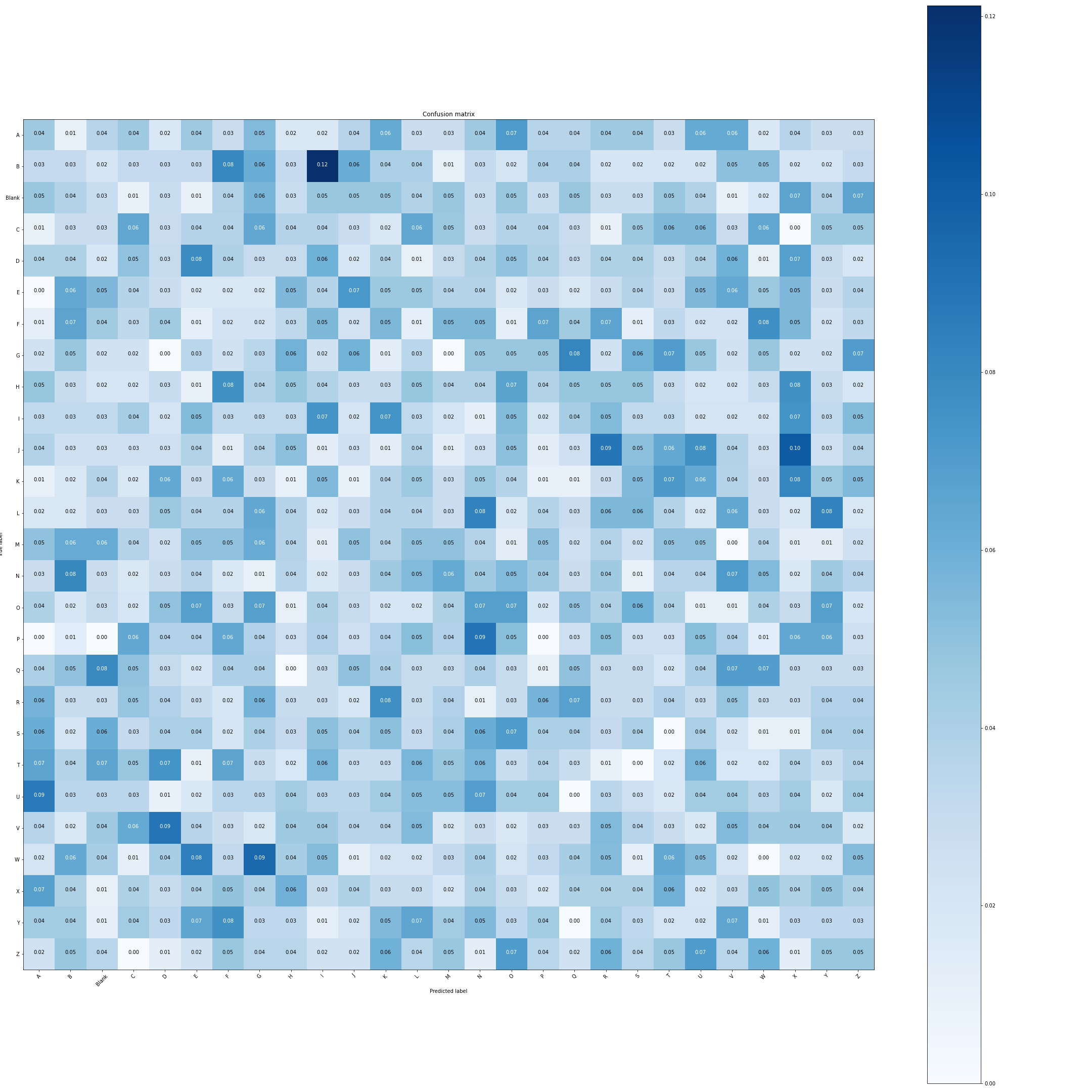
{kind=link}
{kind=link}
{kind=link}