The performance not got imporve #8636
Description
Describe the bug
A clear and concise description of what the bug is. To avoid repetition please make sure this is not one of the known issues mentioned on the respective release page.
I export the model following the guide, and i did a prediction test on the new model and orignal model
the output shows there is no improvement at all ,even a bit performance down.
here the code i used to export and test
```
import datetime
n = 1
for step, item in enumerate(test_dataloader):
begin = datetime.datetime.now()
print(f'This is loop {n} begin:', begin)
model.eval()
text1 = item[0]
text2 = item[1]
ort_inputs = {}
inputs = self.tokenizer(text1, text2, return_tensors='pt', padding='max_length',
truncation='longest_first', max_length=self.args.max_length)
print(f'This is loop {n} inputs init:', datetime.datetime.now() - begin)
inputs['input_ids'] = inputs['input_ids'].to(self.args.device)
inputs['attention_mask'] = inputs['attention_mask'].to(self.args.device)
inputs['token_type_ids'] = inputs['token_type_ids'].to(self.args.device)
ort_inputs['input_ids'] = inputs['input_ids'].cpu().numpy()
ort_inputs['input_mask'] = inputs['attention_mask'].cpu().numpy()
ort_inputs['segment_ids'] = inputs['token_type_ids'].cpu().numpy()
print(f'This is loop {n} inputs put data:', datetime.datetime.now() - begin)
#################################################################
## this is to transform model to ONNX model
output_dir = os.path.join("..", "onnx_models")
if not os.path.exists(output_dir):
os.makedirs(output_dir)
export_model_path = os.path.join(output_dir, 'bert-base-cased-squad.onnx')
device = torch.device("cpu")
model.to(device)
enable_overwrite = True
if enable_overwrite or not os.path.exists(export_model_path):
with torch.no_grad():
symbolic_names = {0: 'batch_size', 1: 'max_seq_len'}
torch.onnx.export(model, # model being run
args=tuple(inputs.values()), # model input (or a tuple for multiple inputs)
f=export_model_path,
# where to save the model (can be a file or file-like object)
opset_version=11, # the ONNX version to export the model to
do_constant_folding=True, # whether to execute constant folding for optimization
input_names=['input_ids', # the model's input names
'input_mask',
'segment_ids'],
output_names=['normalization'], # the model's output names
dynamic_axes={'input_ids': symbolic_names, # variable length axes
'input_mask': symbolic_names,
'normalization': symbolic_names})
print("Model exported at ", export_model_path)
import onnxruntime
sess_options = onnxruntime.SessionOptions()
# Optional: store the optimized graph and view it using Netron to verify that model is fully optimized.
# Note that this will increase session creation time, so it is for debugging only.
sess_options.optimized_model_filepath = os.path.join(output_dir, "optimized_model_cpu.onnx")
session = onnxruntime.InferenceSession(export_model_path, sess_options, providers=['CPUExecutionProvider'])
outputs = session.run(None, ort_inputs)
print(f'This is loop {n} timespend on onnxr predict:', datetime.datetime.now() - begin)
#################################################################
with torch.no_grad():
print(f'This is loop {n} torch.no_grad:', datetime.datetime.now() - begin)
begin = datetime.datetime.now()
# print('** inputs \n', inputs)
outputs = model(**inputs)
print(f'This is loop {n} timespend on pytorch predict:', datetime.datetime.now() - begin)
logits = outputs
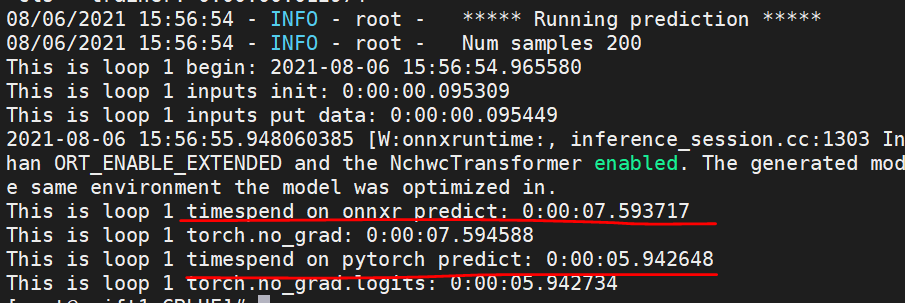
and the log shows as below
08/06/2021 15:56:54 - INFO - root - ***** Running prediction *****
08/06/2021 15:56:54 - INFO - root - Num samples 200
This is loop 1 begin: 2021-08-06 15:56:54.965580
This is loop 1 inputs init: 0:00:00.095309
This is loop 1 inputs put data: 0:00:00.095449
2021-08-06 15:56:55.948060385 [W:onnxruntime:, inference_session.cc:1303 Initialize] Serializing optimized model with Graph Optimization level greater than ORT_ENABLE_EXTENDED and the NchwcTransformer enabled. The generated model may contain hardware specific optimizations, and should only be used in the same environment the model was optimized in.
This is loop 1 timespend on onnxr predict: 0:00:07.593717
This is loop 1 torch.no_grad: 0:00:07.594588
This is loop 1 timespend on pytorch predict: 0:00:05.942648
This is loop 1 torch.no_grad.logits: 0:00:05.942734
Urgency
If there are particular important use cases blocked by this or strict project-related timelines, please share more information and dates. If there are no hard deadlines, please specify none.
System information
- OS Platform and Distribution (e.g., Linux Ubuntu 16.04): Linux version 3.10.0-862.el7.x86_64
- ONNX Runtime installed from (source or binary): source
- ONNX Runtime version: onnxruntime==1.8.1 onnx==1.9.0 onnxconverter_common==1.8.1
- Python version: 3.6
- Visual Studio version (if applicable):
- GCC/Compiler version (if compiling from source):
- CUDA/cuDNN version: NA
- GPU model and memory: NA
To Reproduce
- Describe steps/code to reproduce the behavior.
- Attach the ONNX model to the issue (where applicable) to expedite investigation.
Expected behavior
A clear and concise description of what you expected to happen.
Screenshots
If applicable, add screenshots to help explain your problem.
Additional context
Add any other context about the problem here. If the issue is about a particular model, please share the model details as well to facilitate debugging.