Fix loss scaling when running ORTTrainer with BERT under mixed-precision mode#6932
Merged
Fix loss scaling when running ORTTrainer with BERT under mixed-precision mode#6932
Conversation
SherlockNoMad
approved these changes
Mar 8, 2021
Contributor
Author
|
This PR replaces #6929. |
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
2 participants
Add this suggestion to a batch that can be applied as a single commit.This suggestion is invalid because no changes were made to the code.Suggestions cannot be applied while the pull request is closed.Suggestions cannot be applied while viewing a subset of changes.Only one suggestion per line can be applied in a batch.Add this suggestion to a batch that can be applied as a single commit.Applying suggestions on deleted lines is not supported.You must change the existing code in this line in order to create a valid suggestion.Outdated suggestions cannot be applied.This suggestion has been applied or marked resolved.Suggestions cannot be applied from pending reviews.Suggestions cannot be applied on multi-line comments.Suggestions cannot be applied while the pull request is queued to merge.Suggestion cannot be applied right now. Please check back later.
Recent experiments reveal a divergence problem introduced by pipeline parallel PR. As shown in the following figure, the green line (with PP) differs from gray (without PP) lines. With this PR, gray line becomes orange curve and overlaps with the correct green line.
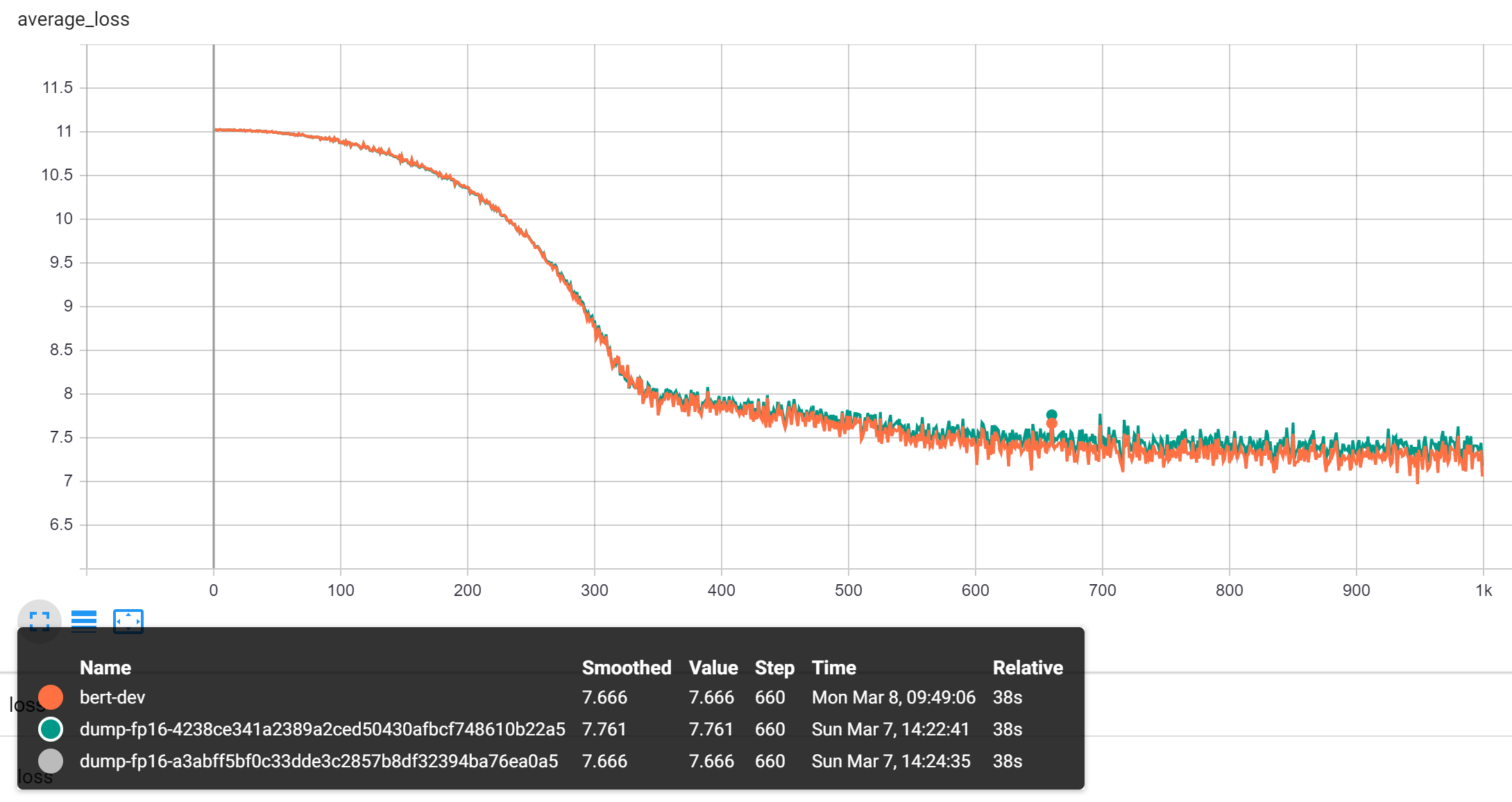
The used script is from ORT's BERT example (based on NV-bert). To speed up the experiment, we use very small model but that model is enough for detecting mixed-precision problem within 1 min. Here is the configuration we use
and