Para aprender a realizar scraping no se me ocurre mejor idea que primero plantear un problema y luego a partir de allí ir realizando pequeñas iteraciones sobre como podemos mejorar nuestra solución e incorporar mas funcionalidad.
Una integrante del equipo de Prometeo (no daré nombres 😂) nos plantea un problema interesante:
– Sabes que estaria bueno, poder conseguir el mejor precio por unidad de pañales de Montevideo.
– ¿Pañales?¿WTF?
– Si Pañales! No sabes la cantidad de plata que los padres gastan en pañales. Pero ojo! Quiero saber el precio por unidad no por paquete, es decir que se deberia obtener el precio total y dividirlo por la cantidad de pañales que vienen en el paquete. Y tambien... quiero poder filtrar solo por el tamaño que usan mis hijos, y... ya que estamos diferenciar por marca también.
– Para, para! Vamos por partes jaja
Ahora que tenemos nuestro problema, vamos a interiorizarnos en la mundo pañalero y definiremos los requerimientos que deberá tener nuestro scraper.
Para los desconocedores del rubro (me incluyo), los pañales suelen venir en paquetes con diferentes cantidades segun el tamaño (¿Sorprendente no? 😂)

Por ejemplo, el precio por unidad de Pampers Confort XG es 17.29 UYU (1002.99/58)
- Obtener el precio por unidad de pañal de los mejores sitios de venta de pañales de Montevideo (Ver lista).
Vamos a empezar de a poco e ir mejorando la solucion en las siguientes iteraciones:
- v1. Instalación & presentación de Scrapy.
- v2. Agregamos scrapers apuntando a los sitios selecionados.
- v3. Enriquecemos los datos.
- v4. Almacenemos mas datos!!! 🙊
- v5. Armemos una API
v1 - Instalación & presentación de Scrapy.
Como dijimos vamos a comenzar armando la base de nuestros scrapers. Para ello utilizaremos Scrapy y los comandos que brinda para inicializar un proyecto.
Primero comezaremos haciendo el setup del entorno virtual de python. Perdonen haters, pero no voy a utilizar virtualenv, yo soy fan de conda. Creamos un entorno de python 3.8 con conda de la siguiente manera:
conda create -n scraping-abc python=3.8Una vez instalado, activamos el entorno virtual. Que de paso vale la pena aclarar, el entorno virtual lo debemos activar cada vez que cerremos la terminal donde estemos trabajando!
conda activate scraping-abcLuego instalamos scrapy
pip install ScrapyAhora que instalamos todo, comencemos creando un proyecto de cero. Para ello utilizaremos los comandos que brinda scrapy (similares a los que tiene Django).
Primero inicializamos un proyecto con:
scrapy startproject DPaaS_v1
Una vez inicializado creamos un crawler bien básico.
cd DPaaS_v1
touch DPaaS_v1/spiders/example.pyY agregamos el siguiente contenido en DPaaS_v1/spiders/example.py. El cual es un scraper que realiza una petición GET a http://example.com/ y extrae el titulo y el primer parrafo de la página utilizando Xpath.
import scrapy
class ExampleSpider(scrapy.Spider):
name = 'example'
start_urls = ['http://example.com/']
def parse(self, response):
return {
"title": response.xpath("//h1/text()").get(),
"description": response.xpath("//p[1]/text()").get(),
}No entiendo una *!@#*! ¿Qué es XPATH? XPath es un selector de HTML/XML similar a los selectores de css. Aca te dejo una cheatsheet de Xpath para tener a mano.
Correr el scraper es fácil, sobre la carpeta del proyecto que creamos (DPaaS_v1) pegamos el siguiente comando, el cual ejecutará el scraper y guardará el contenido en data.json:
scrapy crawl example -O data.json
Ahora vemos el contenido, para chequear que corrió bien:
$ cat data.json | jq
[
{
"title": "Example Domain",
"description": "This domain is for use in illustrative examples in documents. You may use this\n domain in literature without prior coordination or asking for permission."
}
]Primero inicializamos un proyecto nuevo para tener un comienzo mas ordenado:
scrapy startproject DPaaS_v2Analizamos el sitio y buscamos donde estan los datos importantes utilizando las dev tools del navegador:
Ahora que sabemos donde buscar utilizamos el comando scrapy shell <URL>, el cual dispara una request hacia la URL seleccionada y nos permite interactuar con la respuesta.
scrapy shell 'https://panaleraencasa.com/?s=pa%C3%B1al&post_type=product&product_cat=0'...
2022-04-08 21:16:08 [scrapy.core.engine] DEBUG: Crawled (200) <GET https://panaleraencasa.com/?s=pa%C3%B1al&post_type=product&product_cat=0> (referer: None)
[s] Available Scrapy objects:
[s] scrapy scrapy module (contains scrapy.Request, scrapy.Selector, etc)
[s] crawler <scrapy.crawler.Crawler object at 0x7fb1409231f0>
[s] item {}
[s] request <GET https://panaleraencasa.com/?s=pa%C3%B1al&post_type=product&product_cat=0>
[s] response <200 https://panaleraencasa.com/?s=pa%C3%B1al&post_type=product&product_cat=0>
[s] settings <scrapy.settings.Settings object at 0x7fb1409232e0>
[s] spider <DefaultSpider 'default' at 0x7fb1514bd4c0>
[s] Useful shortcuts:
[s] fetch(url[, redirect=True]) Fetch URL and update local objects (by default, redirects are followed)
[s] fetch(req) Fetch a scrapy.Request and update local objects
[s] shelp() Shell help (print this help)
[s] view(response) View response in a browser
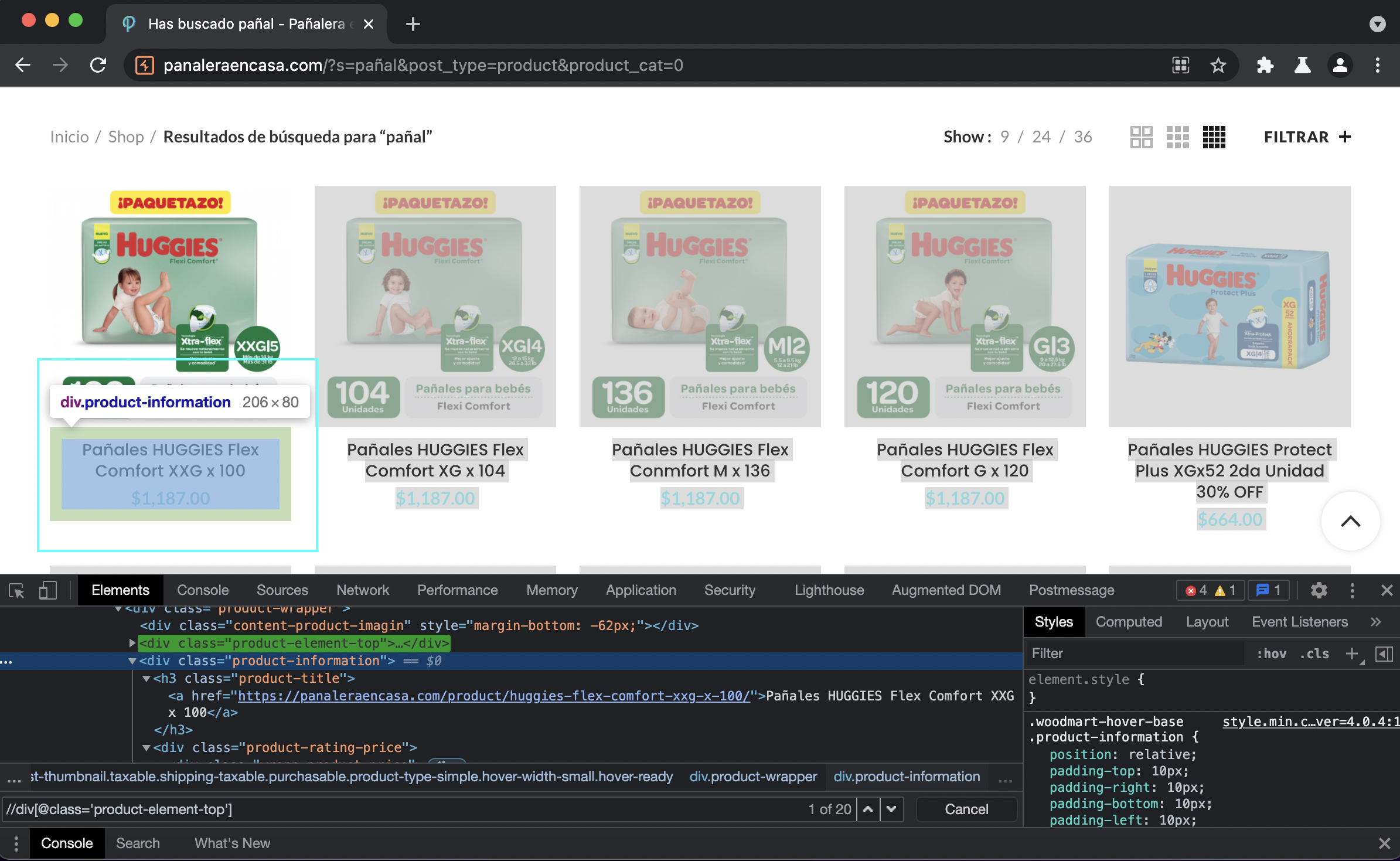
Una vez adentro de la shell de scrapy (similar a una sesion de python interactiva), armamos las expresiones de xpath para obtener los datos. Primero obtenemos los contenedores de cada item dentro de la lista de resultados:
>>> response.xpath("//div[@class='product-information']")[0].get()
'<div class="product-information">\n\t\t<h3 class="product-title"><a href="https://panaleraencasa.com/product/huggies-flex-comfort-xxg-x-100/">Pañales HUGGIES Flex Comfort XXG x 100</a></h3>\t\t\t\t<div class="product-rating-price">\n\t\t\t<div class="wrapp-product-price">\n\t\t\t\t\n\t<span class="price"><span class="woocommerce-Price-amount amount"><span class="woocommerce-Price-currencySymbol">$</span>1,187.00</span></span>\n\t\t\t</div>\n\t\t</div>\n\t\t<div class="fade-in-block">\n\t\t\t<div class="hover-content woodmart-more-desc">\n\t\t\t\t<div class="hover-content-inner woodmart-more-desc-inner">\n\t\t\t\t\t\t\t\t\t</div>\n\t\t\t</div>\n\t\t\t<div class="woodmart-buttons">\n\t\t\t\t<div class="wrap-wishlist-button">\t\t\t<div class="woodmart-wishlist-btn ">\n\t\t\t\t<a href="https://panaleraencasa.com/product/huggies-flex-comfort-xxg-x-100/" data-key="4be7af5d21" data-product-id="460173" data-added-text="Browse Wishlist">Agregar a la lista de deseos</a>\n\t\t\t</div>\n\t\t</div>\n\t\t\t\t<div class="woodmart-add-btn"><a href="?add-to-cart=460173" data-quantity="1" class="button product_type_simple add_to_cart_button ajax_add_to_cart add-to-cart-loop" data-product_id="460173" data-product_sku="127220" aria-label="Agregá “Pañales HUGGIES Flex Comfort XXG x 100” a tu carrito" rel="nofollow"><span>Añadir al Carrito</span></a></div>\n\t\t\t\t<div class="wrap-quickview-button">\t\t\t<div class="quick-view">\n\t\t\t\t<a href="https://panaleraencasa.com/product/huggies-flex-comfort-xxg-x-100/" class="open-quick-view" data-id="460173">Vista rápida</a>\n\t\t\t</div>\n\t\t</div>\n\t\t\t</div>\n\t\t\t\t\t\t\n\t\t\t\t\t</div>\n\t</div>'
>>> item1 = response.xpath("//div[@class='product-information']")[0]Luego de prueba y error obtenemos las dos expresiones para la descripción y para el precio:
>>> item1.xpath(".//a[1]/text()").get()
'Pañales HUGGIES Flex Comfort XXG x 100'
>>> item1.xpath(".//span[@class='price']/span/text()").get()
'1,187.00'Ahora armemos el scraper de panalera_en_casa
scrapy genspider panalera_en_casa 'https://panaleraencasa.com'Incorporamos los Xpath que armamos previamente, y un casteo para el precio del item.
import scrapy
class PanaleraEnCasaSpider(scrapy.Spider):
name = 'panalera_en_casa'
allowed_domains = ['panaleraencasa.com']
start_urls = ['https://panaleraencasa.com/?s=pa%C3%B1al&post_type=product&product_cat=0']
def parse(self, response):
for item in response.xpath("//div[@class='product-information']"):
price = item.xpath(".//span[@class='price']/span/text()").get()
yield {
"description": item.xpath(".//a[1]/text()").get(),
"price": float(price.replace(",",""))
}Ahora vemos el contenido, para chequear que corrió bien:
$ cat data.json | jq
[
{
"description": "Pañales HUGGIES Flex Comfort XXG x 100",
"price": 1187.0
},
{
"description": "Pañales HUGGIES Flex Comfort XG x 104",
"price": 1187.0
},
{
"description": "Pañales HUGGIES Flex Conmfort M x 136",
"price": 1187.0
},
...
]Eso es todo? Nop! Nos falta revisar el paginado, para ello volvemos a las dev tools del navegador.
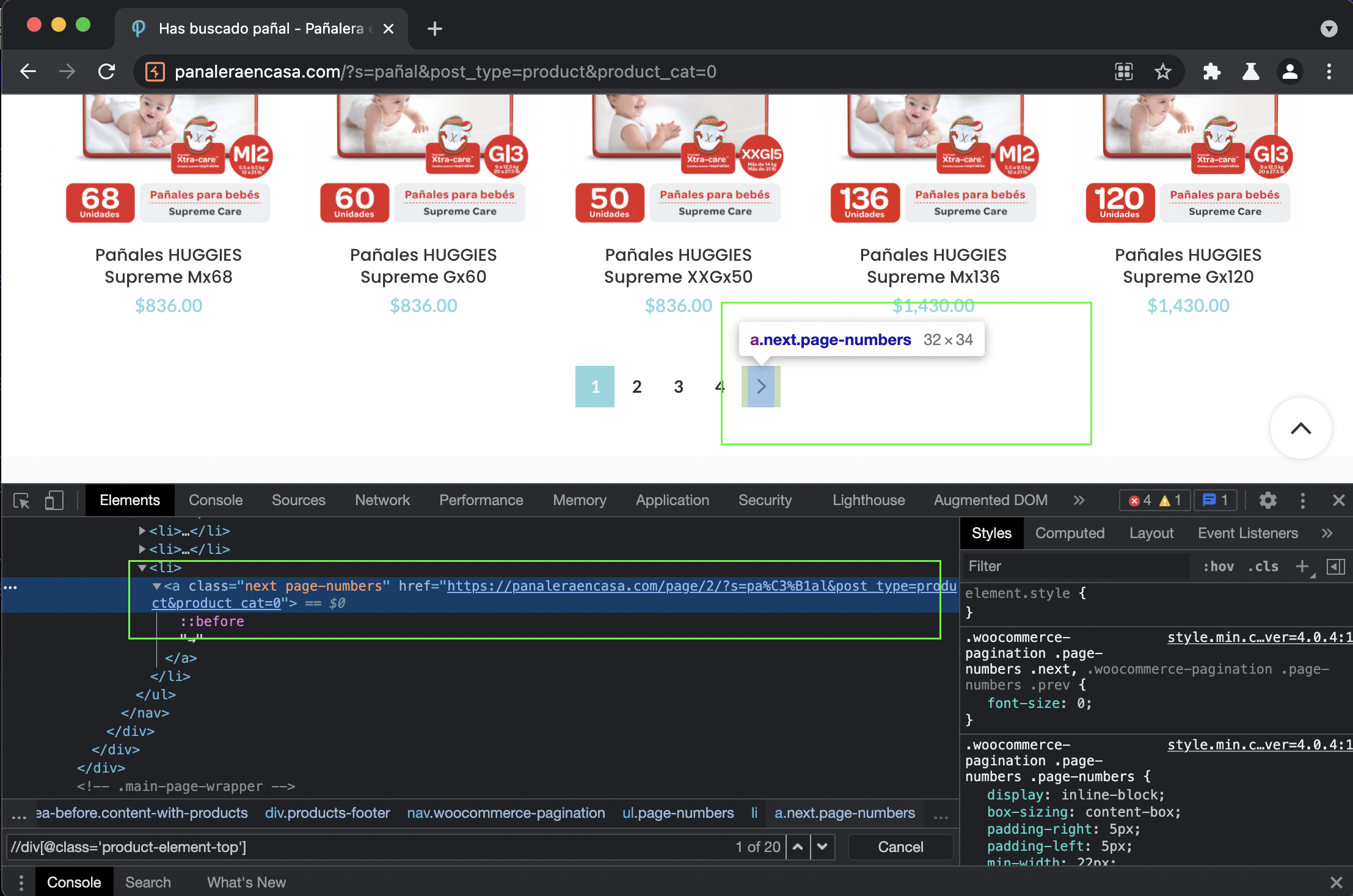
Agregamos el link de la página al final de la método parse(self, response)
def parse(self, response):
...
next_page = response.xpath("//a[contains(@class, 'next')]/@href").get()
if next_page is not None:
yield response.follow(next_page, self.parse)Ahora si! Scraper completo:
import scrapy
class PanaleraEnCasaSpider(scrapy.Spider):
name = 'panalera_en_casa'
allowed_domains = ['panaleraencasa.com']
start_urls = ['https://panaleraencasa.com/?s=pa%C3%B1al&post_type=product&product_cat=0']
def parse(self, response):
for item in response.xpath("//div[@class='product-information']"):
price = item.xpath(".//span[@class='price']/span/text()").get()
yield {
"description": item.xpath(".//a[1]/text()").get(),
"price": float(price.replace(",",""))
}
next_page = response.xpath("//a[contains(@class, 'next')]/@href").get()
if next_page is not None:
yield response.follow(next_page, self.parse)Repetimos el mismo proceso pero con pigalle.com.uy, tratando de identificar como vienen los datos revisando el sitio y utilizando las dev tools del navegador. Para esta etapa también podemos utilizar un proxy tipo MITM (recomiendo Burp, pero también hay buenas alternativas como ZAP o Charles)
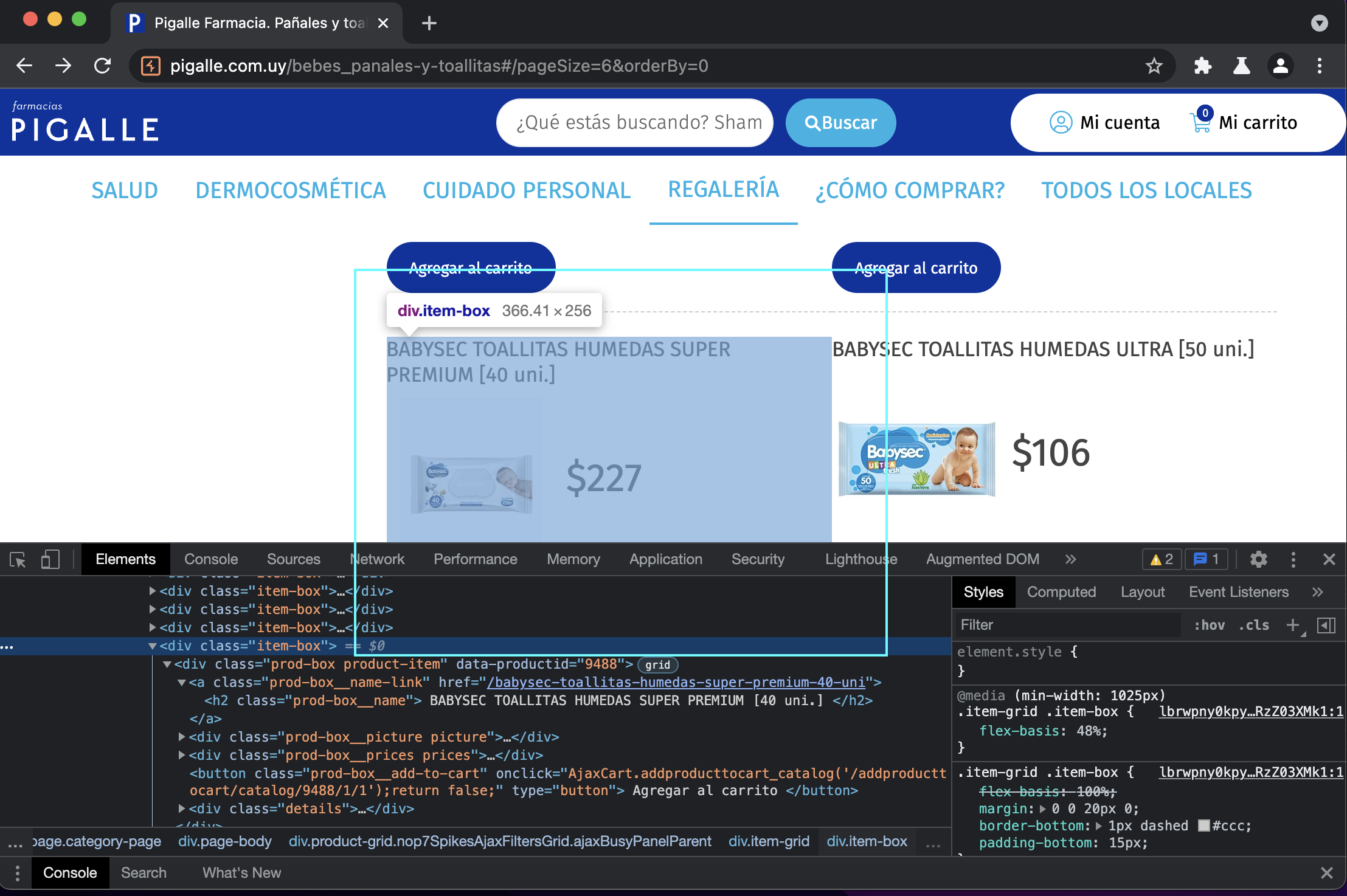
Ahora interactuamos utilizando el comando scrapy shell https://www.pigalle.com.uy/bebes_panales-y-toallitas:
>>> item = response.xpath("//div[contains(@class, 'item-box')]")[0]
>>> item.xpath(".//h2/text()").get()
'\r\n\t\t\tBABYSEC PACK BIENVENIDA PAÑAL RN + PAÑAL P + TOALLITAS HUMEDAS 3 uni. [40+40+80 uni.]\r\n\t\t'
>>> item.xpath(".//div[contains(@class, 'prod-box__current-price')]/text()").get()
'\r\n\t\t\t$1.569\r\n\t\t'Genial! Ya tenemos los datos ahora falta averiguar el tema del paginado. Volvemos a la web a buscar como se cargan mas elementos.
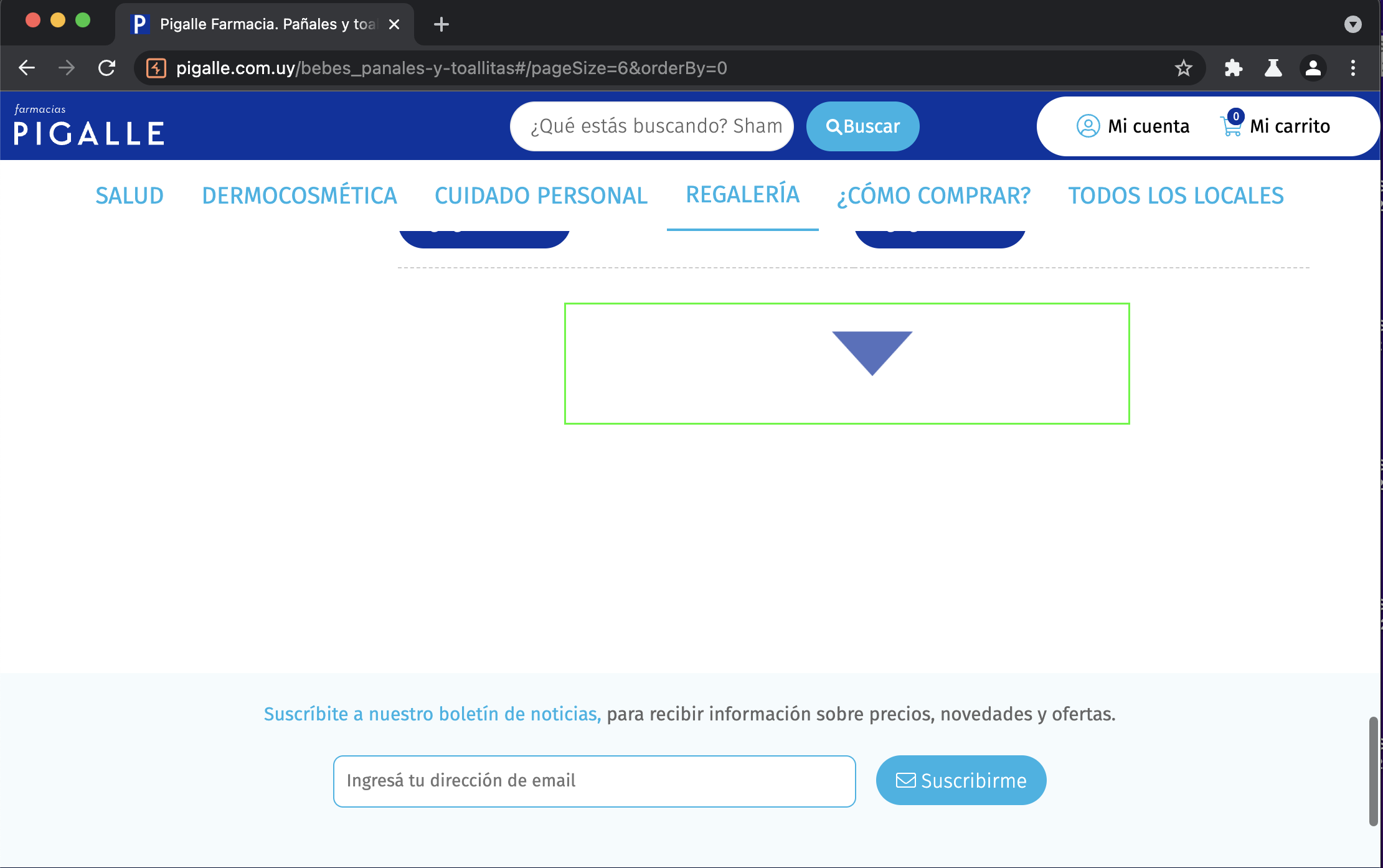
Vemos que no tenemos botón de siguiente sino que cuando se scrollea para abajo se cargan mas movimientos. Vamos a abrir el proxy, y encontrar como se disparan los eventos.
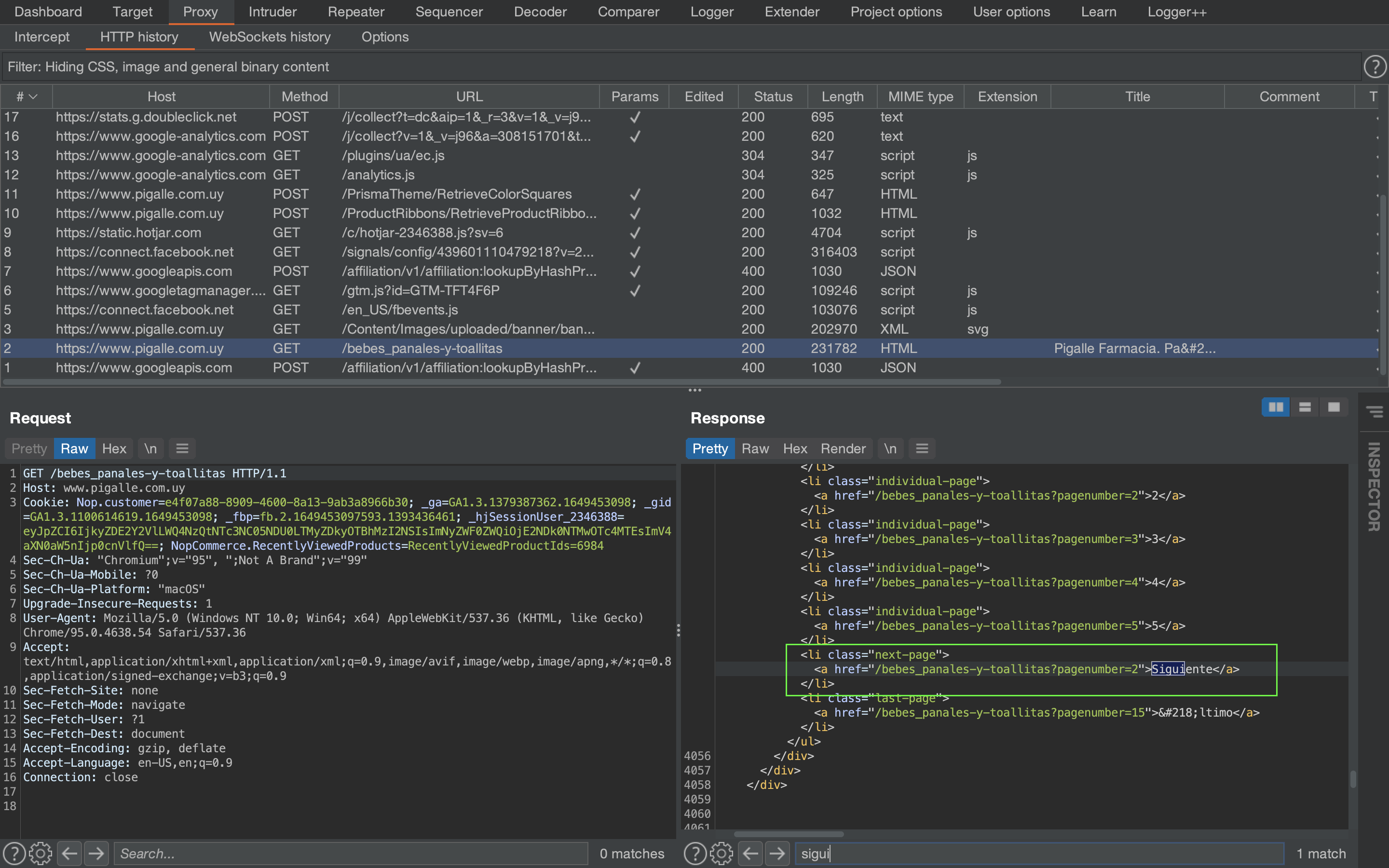
Encontramos que en realidad si hay un botón de siguiente pero se encuentra oculto, por lo tanto podemos probar el mismo método que utilizamos en panalera_en_casa. Funcionó de diez! A continuación podemos ver el scraper completo para este caso:
import scrapy
class PigalleSpider(scrapy.Spider):
name = 'pigalle'
allowed_domains = ['www.pigalle.com.uy']
start_urls = ['https://www.pigalle.com.uy/bebes_panales-y-toallitas']
def parse(self, response):
for item in response.xpath("//div[contains(@class, 'item-box')]"):
price = item.xpath(".//div[contains(@class, 'prod-box__current-price')]/text()").get()
yield {
"description": item.xpath(".//h2/text()").get().strip(),
"price": float(price.strip().replace(".", "").replace("$",""))
}
next_page = response.xpath("//li[@class='next-page']/a/@href").get()
if next_page is not None:
yield response.follow(next_page, self.parse)Corremos el scraper con scrapy crawl pigalle -O pigalle.json. Luego revisamos si los datos se almacenaron correctamente:
$ cat pigalle.json | jq
[
{
"description": "BABYSEC PACK BIENVENIDA PAÑAL RN + PAÑAL P + TOALLITAS HUMEDAS 3 uni. [40+40+80 uni.]",
"price": 1569
},
{
"description": "BABYSEC PACK BIENVENIDA PAÑAL RN [80 uni.]",
"price": 1001
},
{
"description": "BABYSEC PACK BIENVENIDA PAÑAL P [80 uni.]",
"price": 1201
},
...
]Realizamos el mismo proceso nuevamente con este sitio. Buscamos los contenedores de cada uno de los items para extraer la información.
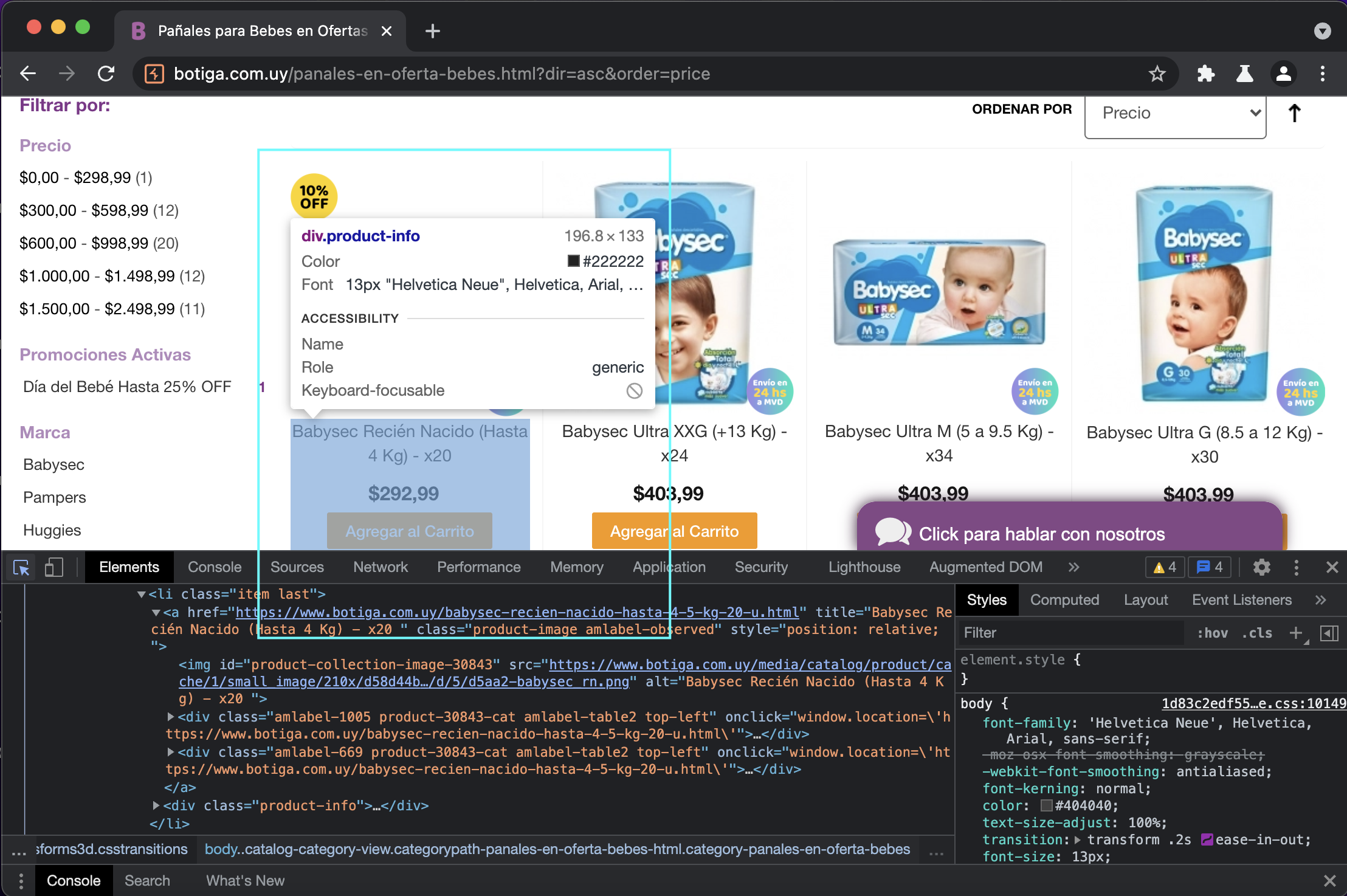
Ahora interactuamos directamente con scrapy shell para obtener la data que necesitamos.
>>> item = response.xpath("//div[contains(@class, 'product-info')]")[0]
>>> item.xpath("//h3[contains(@class, 'product-name')]//text()").get()
'Babysec Recién Nacido (Hasta 4 Kg) - x20 '
>>> item.xpath("//span[contains(@class, 'price')]//text()").get()
'$0,00'
Que raro los precios estan en cero! Hay que revisar de nuevo los datos en el proxy.
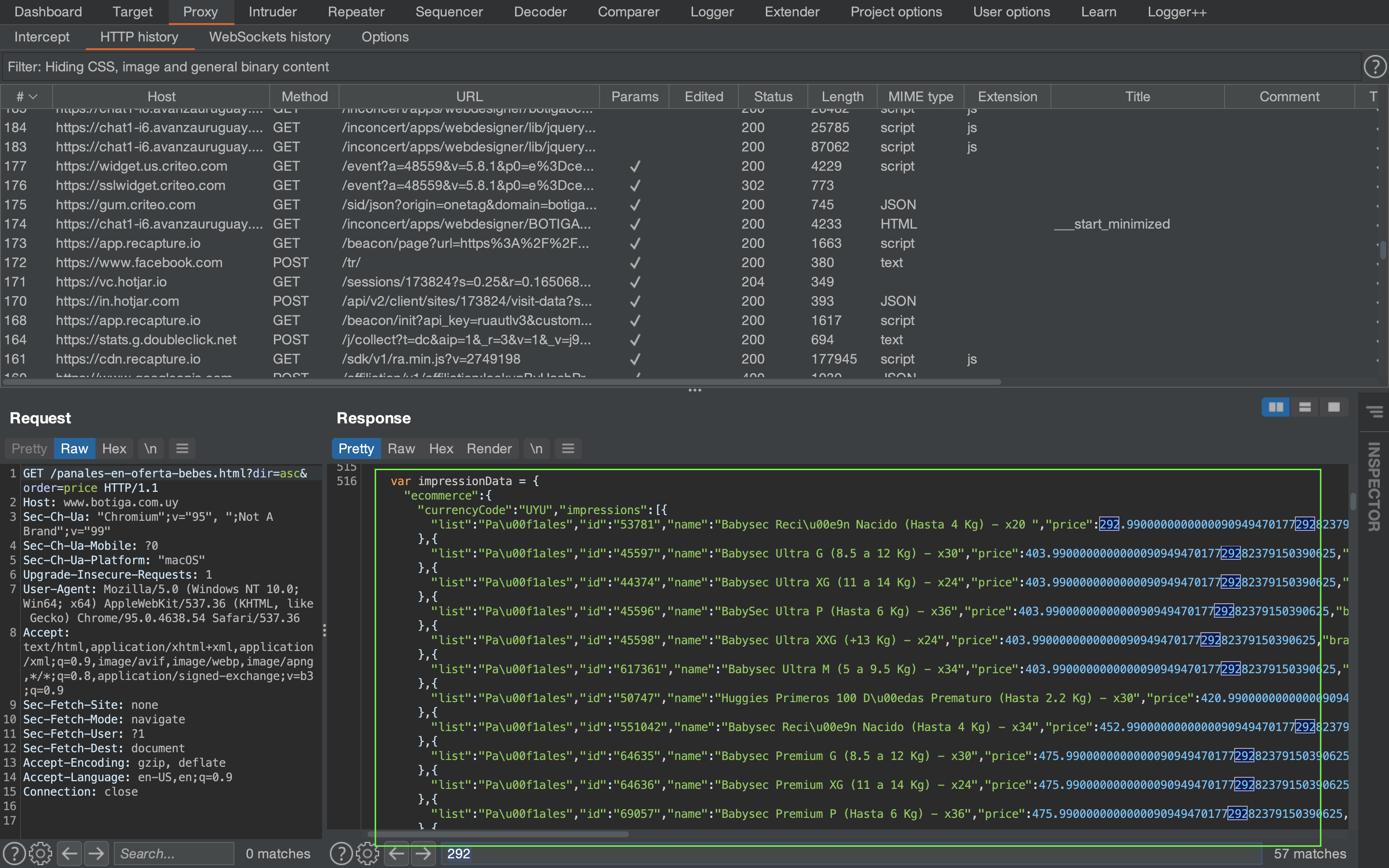
Los precios se cargan via JS, vienen dentro de la respuesta pero estan en un diccionario de javascript. Para extrear esta data vamos a tener que utilizar otra herramienta de nuestra caja: Expresiones Regulares (o en inglés, RegEx, de regular expresions).
>>> import re
>>> re.search("var impressionData = \{(.*)\}", response.text)
<re.Match object; span=(14236, 28647), match='var impressionData = {"ecommerce":{"currencyCode">
Ahora que segmentamos donde estan los datos, vamos a armar las expresiones regulares que busquen las descripciones y los precios.
>>> data = re.search("var impressionData = \{(.*)\}", response.text).group(1)
>>> re.findall("\"price\":([0-9\.]+)", data)
['292.990000000000009094947017729282379150390625', '403.990000000000009094947017729282379150390625', '403.990000000000009094947017729282379150390625', '403.990000000000009094947017729282379150390625', ...]
>>> re.findall("\"name\":\"([^,]+)\"", data)
['Babysec Reci\\u00e9n Nacido (Hasta 4 Kg) - x20 ', 'Babysec Ultra G (8.5 a 12 Kg) - x30', 'Babysec Ultra XG (11 a 14 Kg) - x24', 'BabySec Ultra P (Hasta 6 Kg) - x36', 'Babysec Ultra XXG (+13 Kg) - x24', 'Babysec Ultra M (5 a 9.5 Kg) - x34', 'Huggies Primeros 100 D\\u00edas Prematuro (Hasta 2.2 Kg) - x30', 'Babysec Reci\\u00e9n Nacido (Hasta 4 Kg) - x34', 'Babysec Premium XXG (+13 Kg) - x24', ...]
Ahora corremos el scraper con scrapy crawl
scrapy crawl botiga -O botiga.json...
2022-04-09 18:28:03 [scrapy.downloadermiddlewares.robotstxt] DEBUG: Forbidden by robots.txt: <GET https://www.botiga.com.uy/panales-en-oferta-bebes.html?dir=asc&order=price>
Ups! Encontramos un error. No podemos ejecutar el scraper porque la URL tiene contenido que esta prohibido crawlear. Para eso debemos ignorar el robots.txt. En settings.py agregamos lo siguiente:
ROBOTSTXT_OBEY = FalseNuestro scraper completo luce algo asi:
import re
import scrapy
class BotigaSpider(scrapy.Spider):
name = 'botiga'
start_urls = ['https://www.botiga.com.uy/panales-en-oferta-bebes.html?dir=asc&order=price']
def parse(self, response):
data = re.search("var impressionData = \{(.*)\}", response.text).group(1)
descriptions = re.findall("\"name\":\"([^,]+)\"", data)
prices = re.findall("\"price\":([0-9\.]+)", data)
for description, price in zip(descriptions, prices):
yield {
"description": description.strip(),
"price": float(price)
}Ahora que tenemos listo nuestro codigo, probamos listar esos pañales...
scrapy crawl botiga -O botiga.json$ cat botiga.json | jq
[
{
"description": "Babysec Reci\\u00e9n Nacido (Hasta 4 Kg) - x20",
"price": 292.99
},
{
"description": "BabySec Ultra P (Hasta 6 Kg) - x36",
"price": 403.99
},
{
"description": "Babysec Ultra XXG (+13 Kg) - x24",
"price": 403.99
},
...
]Ahora si! Tenemos listo nuestro tercer scraper. Y con esto, terminamos la segunda etapa! 🎉🕺
Lo que buscamos en esta etapa es mejorar los datos que tenemos sobre nuestros items. En la etapa anterior nos enfocamos a obtener los datos mas relevantes de cada item y los guardamos de la siguiente manera:
{
"description": "Huggies Supreme Care XXG (+14 Kg) - x100",
"price": 1527.99
}En esta etapa vamos a buscar transformar esas dos claves en algo mas interesante:
{
"brand": "huggies",
"size": "xxg",
"target_kg": {
"min": 14,
"max": null,
},
"units": 100,
"unit_price": 15.27,
"description": "Huggies Supreme Care XXG (+14 Kg) - x100",
"price": 1527.99
}Primero inicializamos un proyecto nuevo para tener un comienzo mas ordenado, copiamos los spiders y cambiamos la linea ROBOTSTXT_OBEY = False en settings.py:
scrapy startproject DPaaS_v3
cp -R DPaaS_v2/DPaaS_v2/spiders DPaaS_v3/DPaaS_v3Ahora que tenemos la base del proyecto anterior, continuamos con el análisis de cada página web, para ver como podemos extraer los datos utilizando expresiones regulares. Ejecutamos todos los scrapers con el siguiente comando:
scrapy list | xargs -I {} -t scrapy crawl {} -O {}.jsonLa industria pañalera no es precisamente un ambiente de muchos jugadores, haciendo un poco de investigación encontramos las compañías predominantes. Esto que nos permite establecer una clasificación mas acotada. Además, ayuda a establer una categorización de tamaños más estandar ya que es un atributo que depende de la marca típicamente.
| Talles | Huggies | Pampers | Babysec |
|---|---|---|---|
| PR - Prematuro | Hasta 2.2 kg | - | - |
| RN - Recién nacido | Hasta 4 kg | Hasta 4.5 kg | Hasta 4.5 kg |
| RN - Recién nacido (+) | - | 3 a 6 kg | - |
| P - Pequeño | 3.5 a 6 kg | 5 a 7.5 kg | hasta 6 kg |
| M - Mediano | 5.5 a 9.5 kg | 6 a 9.5 kg | 5 a 9.5 kg |
| G - Grande | 9 a 12.5 kg | 9 a 12 kg | 8.5 a 12 kg |
| XG - Extra Grande | 12 a 15 kg | 12 a 15 kg | 11 a 14 kg |
| XXG - Extra Extra Grande | más de 14 kg | más de 14 kg | más de 13 kg |
Fuente: https://www.donmasivo.com/talles-de-panales/, solo se modifico
PrematutoagregandoPRpara seguir con la nomenclatura.
Nos evita depender de que el vendedor informe o no los kilogramos para cada item, de esta manera podemos guiarnos directamente por el talle para obtener los pesos. Además que transformar una descripción como Hasta 6kg en {'min': null, 'max': 6} no es una tarea sencilla a primera vista.
En algunos casos es necesario aplicar una normalización o limpieza sobre los datos ya que tenemos items de este estilo:
Babysec Recién Nacido (Hasta 4 Kg) - x20debería serBabysec RN (Hasta 4 Kg) - x20Babysec Prematuro (Hasta 4 Kg) - x20debería serBabysec PR (Hasta 2.2 Kg) - x30Hugies XGG x20debería serHuggies XGG x20Huggies GRANDE x20debería serHuggies G x20Huggies S-M x20debería serHuggies M x20ya que no tenemos talleS
Encontramos un patrón para detectar si se trata de un item pañal, el mismo respeta el siguiente esquema BRAND ... SIZE ... UNITS_1 o UNITS_2, si hilamos cada grupo:
BRANDdonde los valores posibles sonhuggies,pampers,babysecSIZEdonde los valores posibles sonpr,rn,p,m,g,xg,xgg(también asixg/xxg, pero en este caso se elige la ultima)UNITS_1donde tenemos las unidades de la siguiente formax100ox 100UNITS_2donde tenemos las unidades de la siguiente forma[100 uni.]
Traducimos estos posibles valores a expresiónes regulares en python:
brand = "(?P<brand>huggies|pampers|babysec)"
size = "\s(pr|rn|p|m|g|xg|xxg)*\s*(\\\/|\-)*\s*(?P<size>pr|rn|p|m|g|xg|xxg)"
units_label_1 = "x\s*(?P<units>[0-9]+)"
units_label2 = "\[(?P<units>[0-9]+)\s*uni.\]"
DIAPERS_REGEX = [
f".*{brand}.*{size}.*{units_label_1}",
f".*{brand}.*{size}.*{units_label2}",
]Estas constantes las definimos en el archivo
DPaaS_v3/DPaaS_v3/constants.py
En la siguiente sección armaremos paso a paso, el pipeline de items para extraer los datos que nos interesan para asi formar la estructura que describimos aqui
Comenzamos con una introducción a los pipelines. Un item pipeline no es mas que un filtro que se aplicará a todos los items scrapeados. Por ejemplo, a continuación mostramos un pipeline que elimina todos los elementos que no tiene el atributo price definido, y para los que si tiene definidos le agrega otro campo tax:
from itemadapter import ItemAdapter
from scrapy.exceptions import DropItem
class SomePipeline:
def process_item(self, item, spider):
adapter = ItemAdapter(item)
price = adapter.get("price")
if not price:
raise DropItem(f"Missing data in {item}")
adapter['tax'] = price * 0.07
return itemEs sencillo es armar un pipeline, el tema se complica a medida que tengamos que realizar mas modificaciones, para nuestro caso, primero definamos el pipeline y eliminemos aquellos items que no tengan price o description.
from itemadapter import ItemAdapter
from scrapy.exceptions import DropItem
class DiaperPipeline:
def process_item(self, item, spider):
adapter = ItemAdapter(item)
description = adapter.get("description")
price = adapter.get("price")
if description and price:
return item
raise DropItem(f"Missing data in {item}")Ahora enfoquemosnos en la transformación que tenemos que hacer a los datos que estudiamos en seccion normalización de datos. Para realizar ese preprocesamiento de los datos la manera mas sencilla que se me ocurrio es definir un diccionario REPLACEMENTS y recorrerlo en busqueda de los valores a reemplazar.
import re
# ...
REPLACEMENTS = {
"pr": [r"prematuro"],
"rn": [r"reci.*n nacido"],
"huggies": [r"hugies"],
"g": [r"grande"],
"m": [r"s\-m"],
}
class DiaperPipeline:
def _clean_description(self, description):
description = description.lower()
for value, expressions in REPLACEMENTS.items():
for expresion in expressions:
if re.search(expresion, description):
description = re.sub(expresion, value, description)
break
return description
# ...Utilizamos la funciones re.search para buscar que la expresion se encuentre en la descripción y si es asi reemplazamos con re.sub, luego rompemos el for con break para que deje de reemplazar esa expresion. Es decir basta con realizar un reemplazo de la lista para pasar a la siguiente expresión.
Ahora armamos la función para matchear los items utilizando las Regex definidas en análisis de descripciones.
import re
from .constants import DIAPERS_REGEX
class DiaperPipeline:
# ...
def _extract_data(self, description):
for expresion in DIAPERS_REGEX:
match = re.match(expresion, description)
if match:
return match
return NoneYa tenemos todas nuestras funciones ahora realicemos las modificaciones al método process_item:
import re
from itemadapter import ItemAdapter
from scrapy.exceptions import DropItem
from .constants import DIAPER_SIZES, DIAPERS_REGEX
REPLACEMENTS = {
"pr": ["prematuro"],
"rn": ["reci.*n nacido"],
"huggies": ["hugies"],
"g": ["grande"],
}
class DiaperPipeline:
def _clean_description(self, description):
description = description.lower()
for value, expressions in REPLACEMENTS.items():
for expresion in expressions:
if re.search(expresion, description):
description = re.sub(expresion, value, description)
break
return description
def _extract_data(self, description):
for expresion in DIAPERS_REGEX:
match = re.match(expresion, description)
if match:
return match
return None
def process_item(self, item, spider):
adapter = ItemAdapter(item)
description = adapter.get("description")
price = adapter.get("price")
if description and price:
description = self._clean_description(description)
match = self._extract_data(description)
if not match:
raise DropItem(f"Not a diaper - {item}")
brand = match.group("brand")
size = match.group("size")
units = int(match.group("units"))
adapter['description'] = description
adapter['brand'] = brand
adapter['size'] = size
adapter['target_kg'] = DIAPER_SIZES.get(brand, {}).get(size)
adapter['units'] = units
adapter['unit_price'] = price / units if units else None
return item
raise DropItem(f"Missing data in {item}")Por último en el archivo DPaaS_v3/DPaaS_v3/constants.py, donde definiremos la tabla de talles.
DIAPER_SIZES = {
"huggies": {
"pr": {"min": None, "max": 2.2},
"rn": {"min": None, "max": 4},
"p": {"min": 3.5, "max": 6},
"m": {"min": 5.5, "max": 9.5},
"g": {"min": 9, "max": 12.5},
"xg": {"min": 12, "max": 15},
"xxg": {"min": 14, "max": None},
},
"pampers": {
"rn": {"min": None, "max": 4.5},
"rn+": {"min": 3, "max": 6},
"p": {"min": 5, "max": 7.5},
"m": {"min": 6, "max": 9.5},
"g": {"min": 9, "max": 12},
"xg": {"min": 12, "max": 15},
"xxg": {"min": 14, "max": None},
},
"babysec": {
"rn": {"min": None, "max": 4.5},
"p": {"min": None, "max": 6},
"m": {"min": 5, "max": 9.5},
"g": {"min": 8.5, "max": 12},
"xg": {"min": 11, "max": 15},
"xxg": {"min": 13, "max": None},
},
}Ahora que tenemos todo listo, probemos los scrapers!!
scrapy list | xargs -I {} -t scrapy crawl {} -O {}.json$ cat botiga.json | jq
[
{
"description": "huggies supreme care g (9 a 12.5 kg) - x120",
"price": 1527.99,
"brand": "huggies",
"size": "g",
"target_kg": {
"min": 9,
"max": 12.5
},
"units": 120,
"unit_price": 12.73325
},
{
"description": "pampers confort sec forte bag xg (11 a 15 kg) x116",
"price": 1734.99,
"brand": "pampers",
"size": "xg",
"target_kg": {
"min": 12,
"max": 15
},
"units": 116,
"unit_price": 14.956810344827586
},
{
"description": "pampers confort sec forte bag m (6 a 10 kg) x148",
"price": 1734.99,
"brand": "pampers",
"size": "m",
"target_kg": {
"min": 6,
"max": 9.5
},
"units": 148,
"unit_price": 11.722905405405406
},
{
"description": "pampers confort sec forte bag xxg (+14 kg) x112",
"price": 1734.99,
"brand": "pampers",
"size": "xxg",
"target_kg": {
"min": 14,
"max": null
},
"units": 112,
"unit_price": 15.490982142857144
},
...
]$ cat pigalle.json | jq
[
{
"description": "pampers confort sec g g 9a13kg [60 uni.]",
"price": 799,
"brand": "pampers",
"size": "g",
"target_kg": {
"min": 9,
"max": 12
},
"units": 60,
"unit_price": 13.316666666666666
},
{
"description": "pampers confort sec medio m 6a10kg [70 uni.]",
"price": 799,
"brand": "pampers",
"size": "m",
"target_kg": {
"min": 6,
"max": 9.5
},
"units": 70,
"unit_price": 11.414285714285715
},
{
"description": "pampers confort sec pequeño p 5a8kg [72 uni.]",
"price": 1411,
"brand": "pampers",
"size": "p",
"target_kg": {
"min": 5,
"max": 7.5
},
"units": 72,
"unit_price": 19.59722222222222
},
{
"description": "pampers confort sec rn hasta 6kg [36 uni.]",
"price": 484,
"brand": "pampers",
"size": "rn",
"target_kg": {
"min": null,
"max": 4.5
},
"units": 36,
"unit_price": 13.444444444444445
},
{
"description": "pampers confort sec xg xg 11a15kg [116 uni.]",
"price": 1825,
"brand": "pampers",
"size": "xg",
"target_kg": {
"min": 12,
"max": 15
},
"units": 116,
"unit_price": 15.732758620689655
}
...
]$ cat panalera_en_casa.json | jq
[
...
{
"description": "pampers confort sec paquetazo gx128 (9-12.5kg)",
"price": 1751,
"brand": "pampers",
"size": "g",
"target_kg": {
"min": 9,
"max": 12
},
"units": 128,
"unit_price": 13.6796875
},
{
"description": "pampers confort sec paquetazo mx148 (6-9.5kg)",
"price": 1751,
"brand": "pampers",
"size": "m",
"target_kg": {
"min": 6,
"max": 9.5
},
"units": 148,
"unit_price": 11.83108108108108
},
{
"description": "pampers confort sec paquetazo xgx116 (12-15kg)",
"price": 1751,
"brand": "pampers",
"size": "xg",
"target_kg": {
"min": 12,
"max": 15
},
"units": 116,
"unit_price": 15.094827586206897
},
{
"description": "pampers confort sec paquetazo xxgx112 (+14kg)",
"price": 1751,
"brand": "pampers",
"size": "xxg",
"target_kg": {
"min": 14,
"max": null
},
"units": 112,
"unit_price": 15.633928571428571
},
{
"description": "babysec classic plus gx40",
"price": 416,
"brand": "babysec",
"size": "g",
"target_kg": {
"min": 8.5,
"max": 12
},
"units": 40,
"unit_price": 10.4
},
{
"description": "huggies primeros 100 días natural care rnx34",
"price": 477,
"brand": "huggies",
"size": "rn",
"target_kg": {
"min": null,
"max": 4
},
"units": 34,
"unit_price": 14.029411764705882
},
{
"description": "huggies primeros 100 días natural care px34",
"price": 374,
"brand": "huggies",
"size": "p",
"target_kg": {
"min": 3.5,
"max": 6
},
"units": 34,
"unit_price": 11
}
]Todo perfecto! Ahora analicemos las tasa de dropeo de items:
| Sitio | item_scraped_count | item_dropped_count | Efectividad (%) |
|---|---|---|---|
botiga.com.uy |
57 | 0 | 100% |
panaleraencasa.com |
60 | 5 | 92.3% |
pigalle.com.uy |
57 | 29 | 66.27% |
Solo a destacar en los resultados puede haber items que no esperabamos como por ejemplo pañales para adultos (
PLENITUD Protect Gx32 (100-140cm)) o toallitas para bebes, estos casos los eliminamos.
Todo muy lindo pero como se que item es de que sitio y si me interesa un item como lo busco. En esta etapa vamos a agregar los campos website, url e image. A continuación un ejemplo:
{
...
"website": "bogita.com.uy",
"url": "https://www.botiga.com.uy/babysec-recien-nacido-hasta-4-5-kg-20-u.html",
"image": "https://www.pigalle.com.uy/content/images/thumbs/0017361_babysec-pack-bienvenida-panal-rn-panal-p-toallitas-humedas-3-uni-404080-uni_280.jpeg",
}
Incorporamos los atributos cada sitio siguiendo el mismo procedimiento de siempre: primero interactuamos con la response en un browser, luego utilizamos scrapy shell para armar parte del codigo en python, por último validamos con scrapy crawl <scraper_name> -O out.json
En este caso la incorporación de image y url no es muy costosa, ya que estos datos se encuentran dentro del contenedor item o un nivel mas arriba. Este último caso vale la pena hacerle mención, ya que utilizaremos ../ en ./..//img/@src para subir un nivel en el arbol HTML.
A continuación, mostramos el resultado completo:
import scrapy
class PanaleraEnCasaSpider(scrapy.Spider):
name = 'panalera_en_casa'
allowed_domains = ['panaleraencasa.com']
start_urls = ['https://panaleraencasa.com/?s=pa%C3%B1al&post_type=product&product_cat=0']
def parse(self, response):
for item in response.xpath("//div[@class='product-information']"):
price = item.xpath(".//span[@class='price']/span/text()").get()
yield {
"description": item.xpath(".//a[1]/text()").get(),
"price": float(price.replace(",","")),
"image": item.xpath("./..//img/@src").get(),
"url": item.xpath(".//a[1]/@href").get(),
"website": self.allowed_domains[0],
}
next_page = response.xpath("//a[contains(@class, 'next')]/@href").get()
if next_page is not None:
yield response.follow(next_page, self.parse)Este caso es el mas simple, lo único que hay para destacar es que se utiliza response.urljoin ya que uno de los resultados tiene la url relativa.
A continuación, mostramos el resultado completo:
import scrapy
class PigalleSpider(scrapy.Spider):
name = 'pigalle'
allowed_domains = ['www.pigalle.com.uy']
start_urls = ['https://www.pigalle.com.uy/bebes_panales-y-toallitas']
def parse(self, response):
for item in response.xpath("//div[contains(@class, 'item-box')]"):
price = item.xpath(".//div[contains(@class, 'prod-box__current-price')]/text()").get()
yield {
"description": item.xpath(".//h2/text()").get().strip(),
"price": float(price.strip().replace(".", "").replace("$","")),
"url": response.urljoin(item.xpath(".//a[1]/@href").get()),
"image": item.xpath(".//img/@src").get(),
"website": self.allowed_domains[0],
}
next_page = response.xpath("//li[@class='next-page']/a/@href").get()
if next_page is not None:
yield response.follow(next_page, self.parse)Este caso es bastante particular porque debemos obtener image y url de otra fuente ya que estos no se encuentran dentro del JSON de datos, para ello los extraemos utilizando response.xpath(...) y luego mergeamos las listas utilizando zip([1,2], ["a", "b"], ...).
A continuación, mostramos el resultado completo:
import re
import scrapy
class BotigaSpider(scrapy.Spider):
name = 'botiga'
allowed_domains = ['www.botiga.com.uy']
start_urls = ['https://www.botiga.com.uy/panales-en-oferta-bebes.html?dir=asc&order=price']
def parse(self, response):
data = re.search("var impressionData = \{(.*)\}", response.text).group(1)
descriptions = re.findall("\"name\":\"([^,]+)\"", data)
prices = re.findall("\"price\":([0-9\.]+)", data)
images = response.xpath("//li[contains(@class, 'item')]//img/@src").getall()
urls = response.xpath("//h3[@class='product-name']/a/@href").getall()
for description, price, image, url in zip(descriptions, prices, images, urls):
yield {
"description": description.strip(),
"price": float(price),
"image": image,
"url": url,
"website": self.allowed_domains[0],
}En esta sección nos excedemos un poco del target de la charla. Aún asi describimos rapidamente el stack y como levantarla.
| Aplicación | Función |
|---|---|
| MongoDB | Base de Datos no relacional donde guardaremos los items scrapeados. |
| Mongo-Express | Administrador de MongoDB, nos permite visualizar los datos alamcenados en MongoDB rapidamente |
| Backend | FastAPI - Aplicación de Backend que expondrá un endpoint /query-diapers |
| Scrapers | Scrapy - Proyecto de scrapy similar a los realizamos en secciones anteriores |
Es muy sencillo utilizamos docker-compose de la siguiente manera.
docker-compose build
docker-compose upAqui un ejemplo de que parámetros acepta la API:
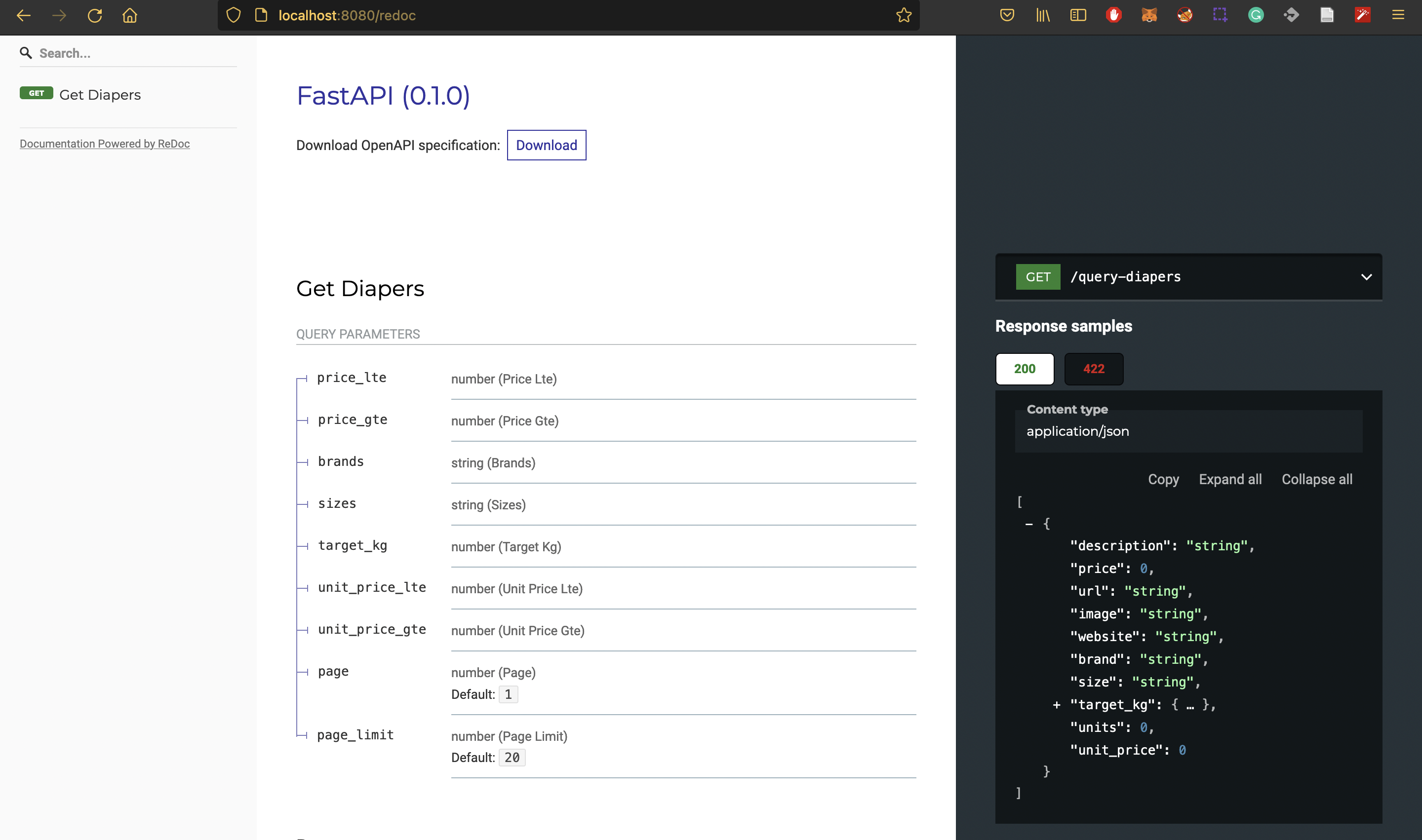
Y por aquí un ejemplo de como buscamos esos huggies G a menos de 11 UYU la unidad:
curl 'http://localhost:8080/query-diapers?sizes=g&brand=huggies&unit_price_lte=11' | jq[
{
"description": "babysec classic plus gx40",
"price": 416,
"url": "https://panaleraencasa.com/product/babysec-classic-plus-gx40/",
"image": "https://panaleraencasa.com/wp-content/uploads/2020/02/Copia-de-Copia-de-Copia-de-Copia-de-Copia-de-Copia-de-Copia-de-Copia-de-Copia-de-25-4-600x600-1-300x300.png",
"website": "panaleraencasa.com",
"brand": "babysec",
"size": "g",
"target_kg": {
"min": 8.5,
"max": 12
},
"units": 40,
"unit_price": 10.4
},
{
"description": "pañales babysec ultra gx120",
"price": 1286,
"url": "https://panaleraencasa.com/product/babysec-panal-ultra-superjumbo-packg/",
"image": "https://panaleraencasa.com/wp-content/uploads/2021/01/pan_ales_babysec-ultra-300x300.jpg",
"website": "panaleraencasa.com",
"brand": "babysec",
"size": "g",
"target_kg": {
"min": 8.5,
"max": 12
},
"units": 120,
"unit_price": 10.72
},
{
"description": "pañales huggies flex comfort g x 120",
"price": 1187,
"url": "https://panaleraencasa.com/product/127218/",
"image": "https://panaleraencasa.com/wp-content/uploads/2022/01/7736550409125-1-300x300.png",
"website": "panaleraencasa.com",
"brand": "huggies",
"size": "g",
"target_kg": {
"min": 9,
"max": 12.5
},
"units": 120,
"unit_price": 9.89
},
{
"description": "babysec ultra g (8.5 a 12 kg) - x120",
"price": 1267.99,
"url": "https://www.botiga.com.uy/babysec-ultra-g-8-5-a-12-kg-120u.html",
"image": "https://www.botiga.com.uy/media/catalog/product/cache/1/small_image/210x/d58d44b981214661663244ef00ea7e30/6/6/66019.jpg",
"website": "www.botiga.com.uy",
"brand": "babysec",
"size": "g",
"target_kg": {
"min": 8.5,
"max": 12
},
"units": 120,
"unit_price": 10.57
}
]