The objective of this project is to compute the trendiness scores of specific words and phrases (two consecutive words) appearing in Twitter.
What is a "Trend"?
Spikes in the likelihood of seeing a word/phrase relative to its usual likelihood.
“Trendiness Score” Formula:
The trendiness of a word/phrase p at time t is computed as follows:
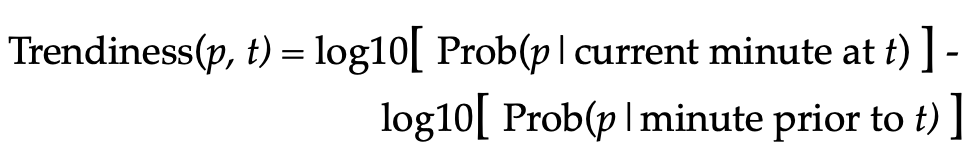
Here,
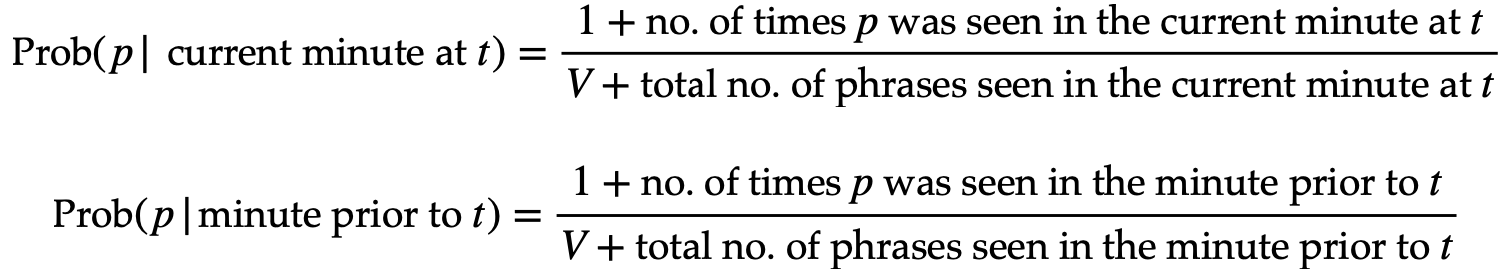
Tweets are obtained from the Twitter API.
Each individual tweet along with its timestamp is transformed according to our needs and pushed to a Kakfa Queue.
At the consumer end, the tweets are consumed and loaded onto a Tweets table in a PostgreSQL Database.
Now, when a user wants to find out the trendiness score of a word/phrase at any specific time, the user runs the trendiness_kafka.py script with the word/phrase as input.
The trendiness score of the word/phrase is computed using the formula shown above and displayed.
This process is executed every minute until the code is force stopped.
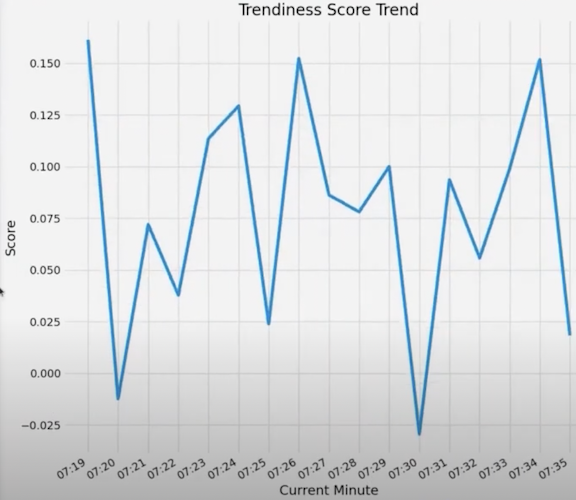
Finally, trendiness scores are plotted across each minute.
The same is shown below: