Object Detection
by 서울대학교 김건희 교수님
- Specify Object Model
- statistical template: pixel값 gradient의 통계? 분포?로 판별

- articulated parts model: 물체는 detectable한 part로 이루어졌다는 전제 하에 판별

- hybrid template/parts model: 전체적인 gradient, part 각각의 gradient 등을 모두 참고하여 판별

- 3D-ish model: 물체는 3D planar patches의 collection이라는 전제 하에 판별
- Generating Hypotheses
- sliding windows: 작은 window들로 나누어서 각각을 판별
- voting from patches/keypoints
- region-based proposal: 다양한 size의 region을 찾는 방법(contour, pattern 등으로 판별)
- Score Hypotheses SVM과 같은 classifier를 이용하여 각 패치마다 object별 점수를 매김
- Resolve Detections
- Non-max suppression: 스코어가 max가 아닌 object는 skip

- Context/reasoning: 주변 문맥(object와 지평선의 위치 관계 등)을 고려하여 판단
참고
object edge에서의 밝기 변화가 일어나는 것을 feature로 사용
- Extract fixed-sized window at each position and scale
- Compute Gradient
- Compute HOG(Histogram of gradient) features
- Score the window with a linear SVM classifier
※ R-CNN도 비슷한 구조
Define object by collection of parts modeled by
appearance / spatial configuration(star-shaped model, tree-shaped model)
object는 부분 요소요소들의 정형화된 구조로 이루어짐, 이 구조를 feature로 사용
아래 세 가지를 모두 고려하여 scoring
- Root filter: model coarse whole-object appearance
- Part filter: model finer-scale appearance of smaller patches
- Spatial cost
HOG feature가 아닌 DeepLearning feature를 사용
 region proposal별로 다 cnn을 돌려야 해 속도가 느림
region proposal별로 다 cnn을 돌려야 해 속도가 느림
cropping/warping으로 인해 image resolution can be lost
R-CNN은 fixed size image만 처리할 수 있기 때문에 cropping/warping 필요(이미지 왜곡됨)
arbitrary sized input and multi-resolution images를 다루기 위해 SPP 도입
■ Spatial Pyramid
Bag of features를 구성하여 feature count histogram을 계산(위치정보는 고려하지 않고, 빈도수만 다루게 됨)
위치 정보를 고려하기 위해 spatial bin별로 hitogram 계산

CNN에서 마지막 pooling layer를 SPP layer로 대체
ROI(Region of Interest)별로 4-level SP를 적용하여 ROI당 50개의 output이 나오게 됨


SPP Pooling이 separate pipeline으로 되어 있기 때문에 training이 느림...
gradient가 SPP layer에서 block되기 때문에 이전 layer는 fine-tuning될 수 없음
※ selective search
image를 여러 size로 resize하고, 다양하게 resize된 이미지들 중에서 ROI가 224x224에 가깝게 된 ROI image를 사용

2 outputs: Softmax probability of K+1(background) classes + bbox coordinates(r, c, h, w) for K classes

■ ROI Pooling Layer: 1-level(7x7) SPP layer -> 미분 가능하게 됨
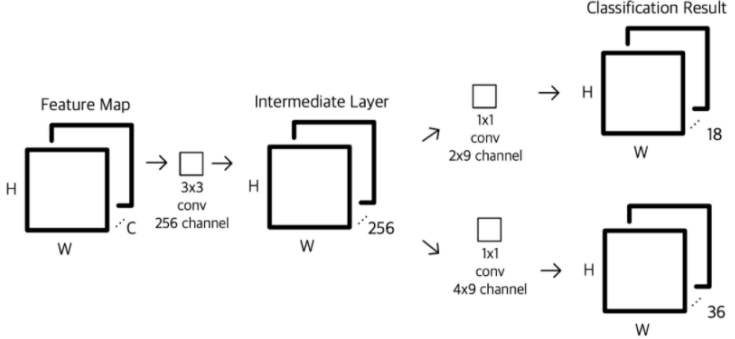
Fast R-CNN + RPN(Region Proposal Network)

Region Proposal을 input image가 아닌 feature map을 보고 뽑음

RPN: Conv feature map(WxHxp)로부터 Region Proposal(WxHxk)을 뽑아내는 작은 network
Anchors: pre-defined reference boxes(k개)
window(nxn)마다 각 anchor별로 prediction을 진행(cls + reg)
cls: object probability(anchor 내부에 객체가 존재할 확률)
reg: 4 coordinates(bounding box)
RPN은 parameter를 공유함
※ IoU(Intersection over Union): RoI와 겹치는 면적의 비율
※ mAP(Mean Average Precision): Precision-recall 그래프의 아래 면적의 class별 평균
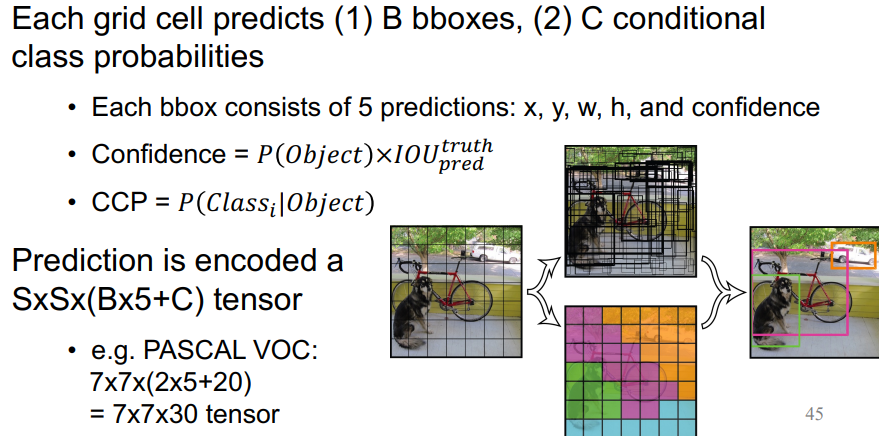
a single CNN simultaneously predicts multiple bounding boxes and class probabilities for those boxes
image를 7x7로 나누어서, object의 center가 위치한 grid가 object detection을 하도록 함
각각의 grid가 bbox와 conditional class probability를 예측
하나의 image당 7x7x30(2x5+20)의 tensor로 encoding됨
 실습
실습