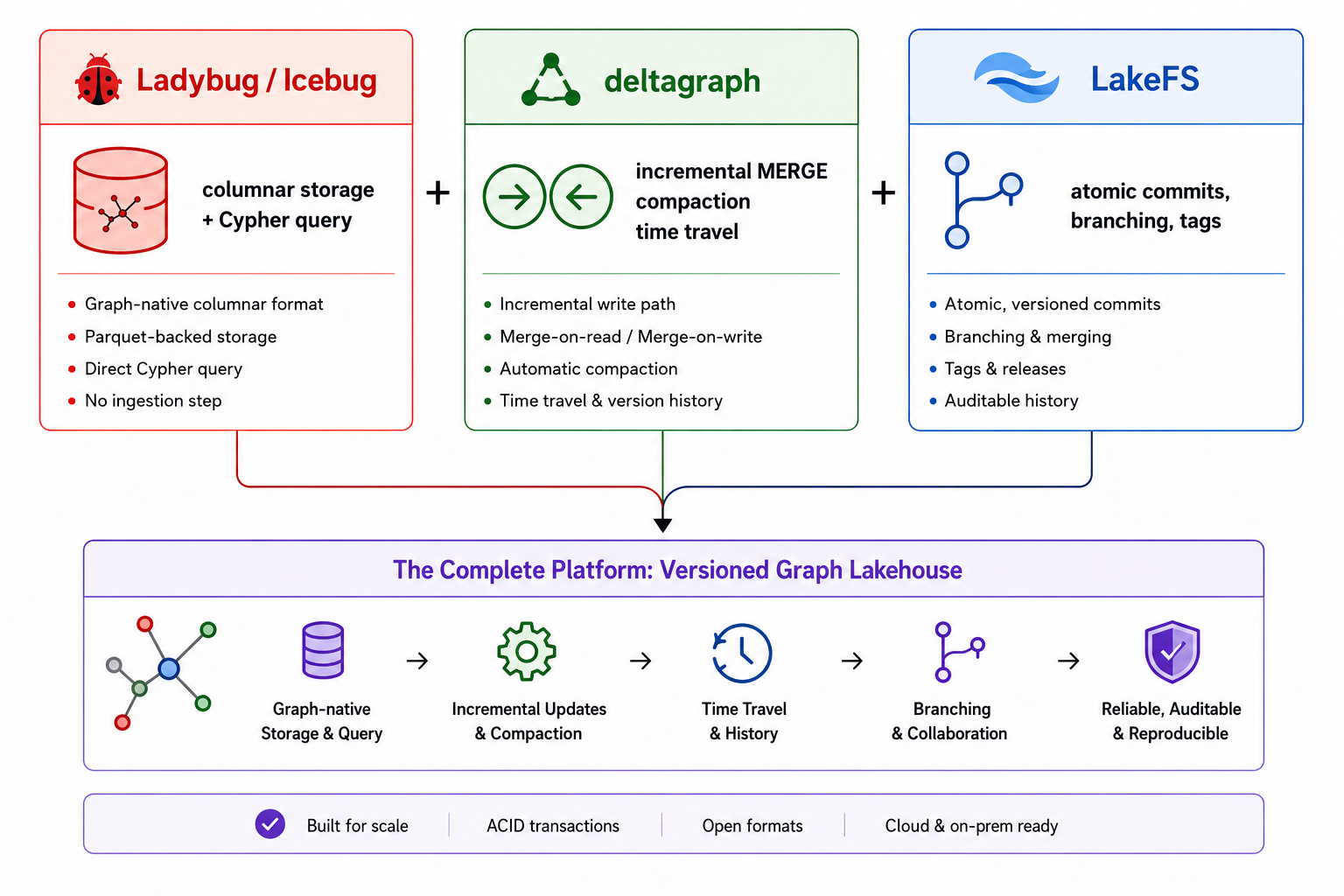
Delta-Lake-style versioning, incremental MERGE, and time travel for graph-native columnar formats.
![]()
Storage and Cypher query come from LadybugDB and its Icebug format — a graph-native, columnar, Parquet-backed layout with direct Cypher query, no ingestion step. deltagraph adds the layer they don't have: an incremental write path, merge-on-read upsert/delete, compaction, and versioned snapshots with time travel (via LakeFS).
The mutation layer runs entirely on Arrow node/relationship tables before any Icebug encoding happens, so it isn't tied to Icebug specifically — the same code applies to any CSR-in-Parquet graph format.
Graph-native columnar formats are read-oriented: fast Cypher queries directly over Parquet, but no concept of a snapshot, no way to ask "what did this graph look like last Tuesday," and no cheap way to apply a stream of upserts without re-encoding the whole graph. Meanwhile, general lakehouse versioning (Delta Lake, Iceberg, LakeFS) is graph-blind — it versions files, not node/edge identities, so it can't tell you a node's incident edges vanished when the node was deleted.
deltagraph sits in between: MERGE semantics (latest-wins upsert, tombstone
delete, node-delete cascades to edges) at the identity level — node primary
keys, (src, dst) edge pairs — layered on top of whatever columnar graph
format and versioning backend you already have. Concretely, that buys you:
- Time travel over a live graph.
query(cypher, ref=<commit>)runs against the exact graph as of that commit, no separate snapshot export step. - Cheap incremental writes. Upserts land in a small delta region; you
don't re-encode the whole graph on every write.
compact()folds the delta into the base on your own schedule. - A change feed for downstream consumers.
changes(from_ref, to_ref)tells you exactly which nodes/edges were added, removed, or updated between two versions — useful for incremental re-indexing (e.g. re-embedding only the nodes that changed for a GraphRAG pipeline) instead of a full rebuild. - Reproducible snapshots. Pin a Cypher query to a tagged commit and get the same answer every time, even after later writes and compactions — handy for audits, regression tests, or citing "the graph as it was" in a paper.
Early (v0.1), core + extended features implemented against LocalBackend:
- Core: create, upsert (row and bulk CSV/Parquet), delete with node-delete cascade, compaction, Cypher query with time travel, tagging. Covered by a hypothesis-based correctness property that checks any interleaving of upsert/delete/compact against an independent reference model.
- Extended: a graph change feed (
changes),restore, and retention (expire) are all implemented and tested. - Not yet built: graph-aware branch merge (
merge_branch, the stretch milestone — needs real multi-branch backend support first),snapshots(),branch(), and theLakeFSBackend(production backend; onlyLocalBackendis wired up today).
# users
pip install deltagraph
# or
uv add deltagraph
# contributors
uv sync
pre-commit install
docker compose up -d # only if exercising the optional LakeFS backendLocalBackend needs no server and no Docker — it's a plain versioned directory,
and it's what the whole test suite runs against.
from deltagraph import GraphStore
from deltagraph.versioning import LocalBackend
store = GraphStore.create(LocalBackend("./demo"), schema_cypher="""
CREATE NODE TABLE Drug(name STRING PRIMARY KEY, dose INT64);
CREATE NODE TABLE Condition(name STRING PRIMARY KEY);
CREATE REL TABLE TREATS(FROM Drug TO Condition);
""")
store.upsert_nodes("Drug", [{"name": "Aspirin", "dose": 100}])
store.upsert_nodes("Condition", [{"name": "Pain"}, {"name": "Fever"}])
v1 = store.upsert_edges("TREATS", [
{"src": "Aspirin", "dst": "Pain"},
{"src": "Aspirin", "dst": "Fever"},
])
store.query("MATCH (d:Drug)-[:TREATS]->(c) RETURN d.name, c.name") # head
store.query("MATCH (d:Drug)-[:TREATS]->(c) RETURN d.name, c.name", ref=v1) # time travel
store.upsert_nodes("Drug", [{"name": "Aspirin", "dose": 250}]) # idempotent, latest-wins
store.delete_nodes("Drug", ["Aspirin"]) # cascades to incident edges
store.compact() # folds delta into baseA full runnable walkthrough with real output is in
examples/quickstart.py — see Examples below.
v1 = store.upsert_nodes("Drug", [{"name": "Aspirin", "dose": 100}])
store.tag("v1", v1)
store.upsert_nodes("Drug", [{"name": "Aspirin", "dose": 250}]) # update
store.upsert_nodes("Drug", [{"name": "Ibuprofen", "dose": 50}]) # add
store.changes("v1")["nodes"]["Drug"]
# {'added': [{'name': 'Ibuprofen', 'dose': 50}],
# 'removed': [],
# 'updated': [{'before': {'name': 'Aspirin', 'dose': 100},
# 'after': {'name': 'Aspirin', 'dose': 250}}]}
store.restore("v1") # new commit whose state equals v1, exactly
store.query("MATCH (d:Drug) RETURN d.name, d.dose")
# [('Aspirin', 100)] -- Ibuprofen and the dose update are gone from head;
# both are still reachable at any ref before the restore
store.expire(before=some_cutoff_timestamp) # drop changelog + old snapshotschanges() is the piece that makes incremental re-indexing practical — e.g. in
a GraphRAG pipeline, re-embed only the nodes reported as added/updated
since your last sync, instead of re-embedding the whole graph. expire()
reclaims space by dropping commit snapshots and changelog history older than a
cutoff; anything tagged before that cutoff becomes unreadable, so keep the
cutoff older than any tag you still need.
Every mutation is one versioning-backend commit; the returned ref is the graph
version you can hand back to query(ref=...) for time travel.
| Method | What it does |
|---|---|
GraphStore.create(backend, schema_cypher) |
Define node/rel tables via Cypher DDL. One commit. Returns a GraphStore. |
.upsert_nodes(table, records) |
Insert-or-update node rows, keyed by the table's declared primary key. |
.upsert_edges(table, records) |
Insert-or-update edge rows; each record carries src/dst endpoint keys. |
.upsert_nodes_from(table, path, key=None) |
Bulk-load a CSV/Parquet file straight to Arrow (no Python-dict round-trip) into the delta. Idempotent — re-ingesting the same file is a no-op beyond dedup. |
.upsert_edges_from(table, path, src=, dst=, edge_key=None) |
Same, for edge files; src/dst name the file's endpoint columns. |
.delete_nodes(table, keys) |
Tombstone nodes by primary key. Incident edges disappear on the next read, even though the edge rows themselves aren't touched. |
.delete_edges(table, keys) |
Tombstone edges by {"src":.., "dst":..} (or +key_prop for edge tables that declare one). |
.compact(tables=None) |
Fold the accumulated delta into a fresh base and clear it. Read/write results are identical before and after. |
.query(cypher, ref=None) |
Run read-only Cypher against the graph as of ref (default: head). Returns a PyArrow Table. Write clauses (CREATE/MERGE/SET/DELETE/REMOVE) are rejected — mutate through the methods above instead. |
.tag(name, ref=None) |
Name a commit (default: head) for later reference — query(ref="v1"). |
.changes(from_ref, to_ref=None) |
Net node/edge diff (added/removed/updated per table) between two commits — the change feed. Works across a compaction boundary. |
.restore(ref) |
Write a new commit whose state equals an old ref. Returns the new ref. |
.expire(before) |
Drop changelog history and superseded commit snapshots older than before. Makes any tag older than the cutoff unreadable — keep before older than any tag you still need. |
Identity, not surrogate IDs. Nodes upsert/delete on their declared primary
key. Edges have no primary key in Ladybug, so deltagraph defines edge identity as
(src, dst) by default, or (src, dst, key_prop) if the rel table declares a
key property.
Versioning backends implement one shared interface
(write_file/read_file/list/commit/tag/resolve_time), so the same
GraphStore code runs against LocalBackend (default, no server) or
LakeFSBackend (production, needs a running LakeFS server).
Extended, git-like features — a change feed, restore, and retention
(changes/restore/expire above) are implemented. A graph-aware branch
merge with identity-level conflict detection is designed (build brief 6.10)
but not yet built — it needs real multi-branch backend support first, which
doesn't exist yet either.
| File | Demonstrates |
|---|---|
examples/quickstart.py |
create → upsert → query → re-upsert (latest-wins) → delete (cascade) → time travel → compact |
scripts/ldbc_snb_tiny_loader.py |
bulk ingestion (upsert_nodes_from/upsert_edges_from) with a synthetic LDBC-SNB-shaped Person/KNOWS graph |
scripts/bench.py |
upsert throughput, compaction cost, head vs. historical query latency, and a compaction_threshold_ratio sweep — uv run python scripts/bench.py --persons 2000 --knows-per-person 10 |
bench.py can also plot results to a PNG (needs uv sync --extra bench for
matplotlib):
uv run --extra bench python scripts/bench.py --persons 2000 --knows-per-person 10 --chart docs/img/bench_results.png
Run it:
uv run python examples/quickstart.pyOutput:
-- head: all TREATS edges (Aspirin is the only Drug so far) --
d.name c.name
Aspirin Pain
Aspirin Fever
-- head after re-upsert: dose updated in place --
d.name d.dose
Aspirin 250
-- head after delete_nodes: Aspirin and its edges are gone --
(no rows)
-- ref=0000004: pre-delete, pre-update snapshot --
d.name d.dose c.name
Aspirin 100 Pain
Aspirin 100 Fever
-- ref=0000004 after compact(): time travel still works --
d.name d.dose c.name
Aspirin 100 Pain
Aspirin 100 Fever
Note the last two blocks are identical — compaction never changes what a query returns, at head or at any historical ref.
Point LocalBackend at ./demo instead of a temp dir and run the same script —
each mutating call is one copy-on-commit snapshot under commits/<ref>/. Delta
parts accumulate per table until compact() folds them into base/ and clears
delta/:
demo/
├── refs.json # head pointer, tags, ordered commit log
├── staging/ # writes not yet committed (invisible to reads)
└── commits/
├── 0000001/ # create(): schema only
│ ├── schema.cypher
│ └── meta.json
├── 0000002/ # upsert_nodes("Drug", ...)
│ ├── delta/nodes/Drug/part-0000001.parquet
│ ├── schema.cypher
│ └── meta.json
├── 0000004/ # upsert_edges("TREATS", ...)
│ ├── delta/nodes/Condition/part-0000002.parquet
│ ├── delta/nodes/Drug/part-0000001.parquet
│ ├── delta/edges/TREATS/part-0000003.parquet
│ └── meta.json
├── 0000006/ # delete_nodes("Drug", ["Aspirin"])
│ ├── delta/nodes/Drug/part-0000001.parquet
│ ├── delta/nodes/Drug/part-0000004.parquet # re-upsert part
│ ├── delta/tombstones/nodes/Drug/part-0000005.parquet
│ └── ...
└── 0000007/ # compact(): delta folded into base
├── base/nodes/Drug.parquet
├── base/nodes/Condition.parquet
├── base/edges/TREATS.parquet
├── delta/ # empty -- cleared by compaction
└── meta.json
Every commit is a whole-graph snapshot, not a diff: commits/0000006/ still
carries every delta part from 0000002 onward, which is what makes
query(ref="0000004") an exact historical reconstruction regardless of what
happens later. demo/ itself is .gitignored — it's generated state, not
source.
uv sync # installs the dev group: pytest, hypothesis, ruff, mypy, pre-commit
uv run pytest # full suite, including the correctness property
uv run pytest -q # quiet
uv run ruff check . # lint
uv run ruff format . # format
uv run mypy deltagraph # type checkWhy not just use Ladybug's native MERGE on a .lbdb database? A .lbdb
file is a monolithic binary with no file-level structure — versioning it
through a backend means storing an opaque blob per commit, with no dedup and
no partial-snapshot reads. deltagraph operates on plain Parquet node/rel files
instead, so snapshots are Parquet-granular and dedup-friendly on object
storage. That granularity is the reason to implement MERGE at the file level
rather than defer to the query engine.
Does this support multigraphs (more than one edge between the same node
pair)? Not in v0.1. Edge identity defaults to (src, dst), so a second edge
between the same pair collapses into the first on upsert. Declaring a
key_prop on the rel table (see the API table's identity note) gives each
edge its own identity, but multigraph support beyond that isn't built yet —
known limitation, not a silent bug.
Can I write Cypher MERGE/CREATE/DELETE directly through query()?
No, by design. query() runs against a throwaway materialization built fresh
per call (see "What LocalBackend writes to disk" above) — a write executed
there would just vanish uncommitted. Mutate through upsert_*/delete_*
instead; query() rejects write clauses outright rather than silently
no-opping them.
Can I add tables to an existing graph? Not yet — schema.cypher is written
once by create() and there's no schema-migration method today. The build
brief scopes additive node/rel tables and additive properties as in-scope for
v0.1, but that migration path isn't implemented; treat the schema as fixed for
now.
Storage and Cypher query: LadybugDB / Icebug. Versioning: LakeFS. deltagraph is the incremental-update, merge, and time-travel layer between them — it does not reimplement CSR encoding, traversal, or Cypher.
MIT. See LICENSE.