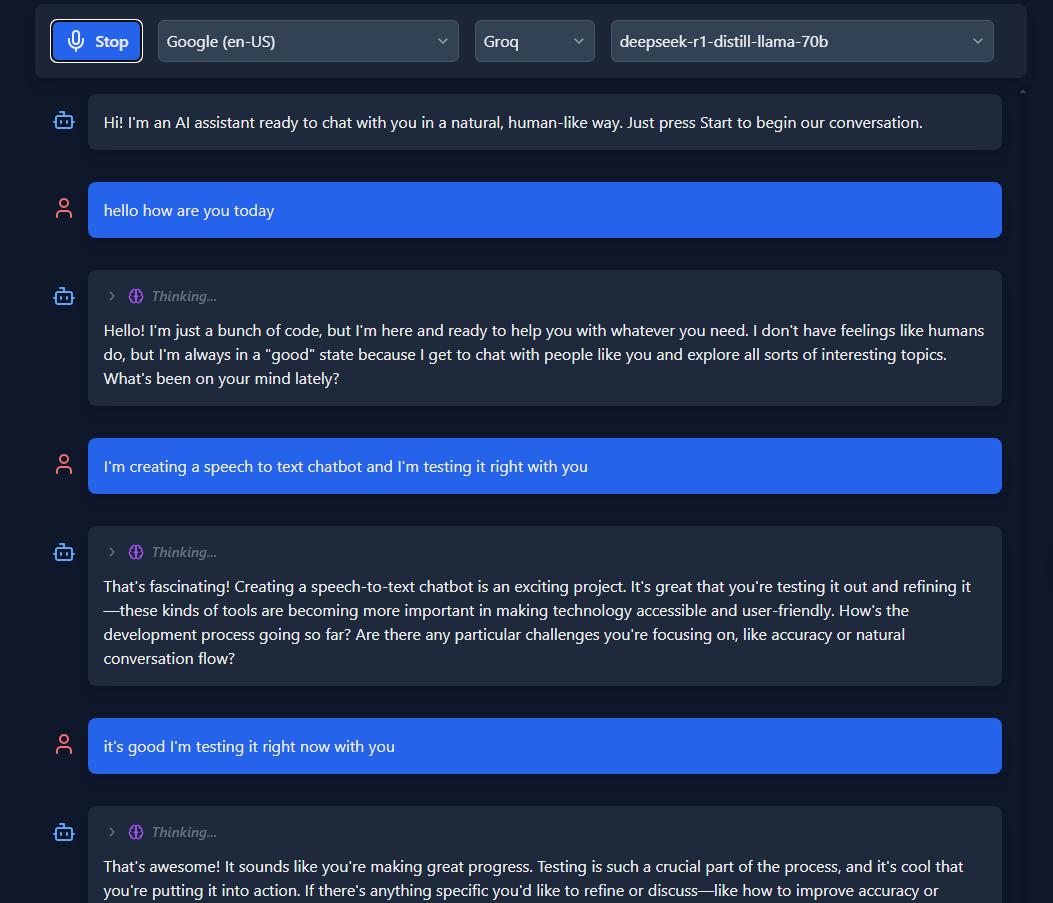
A modern React chatbot application featuring AI-powered conversations with Web Speech-to-Text (STT) and Text-to-Speech (TTS) capabilities, built with Vite and styled with Tailwind CSS.
- Voice Recognition: Web Speech API integration for speech-to-text conversion
- Text-to-Speech: Natural voice synthesis for AI responses
- AI Integration: Support for multiple AI providers (OpenAI, Anthropic, Groq, Grok)
- Visual AI: Image analysis and visual understanding capabilities
- Modern UI: Responsive design with Tailwind CSS
- Real-time Chat: Seamless conversation flow with message history
- Thinking Mode: Advanced reasoning display for complex queries
- Frontend: React 18 + Vite
- Styling: Tailwind CSS
- Speech APIs: Web Speech API (STT/TTS)
- AI Services: OpenAI, Anthropic, Groq, Grok APIs
- Build Tool: Vite with Hot Module Replacement (HMR)
- Node.js (version 16 or higher)
- npm or yarn package manager
- API keys for your preferred AI service(s)
git clone https://github.com/onigetoc/voice-chat-react.git
cd voice-chat-demonpm installImportant: Rename the .env.example file to .env:
Then edit the .env file and add your API keys:
VITE_OPENAI_API_KEY=your_openai_api_key_here
VITE_ANTHROPIC_API_KEY=your_anthropic_api_key_here
VITE_GROQ_API_KEY=your_groq_api_key_here
VITE_GROK_API_KEY=your_grok_api_key_hereNote:
- You only need to configure the API keys for the services you plan to use.
- Google Chrome offers the most natural and expressive voices available through the Web Speech API.
npm run devThe application will be available at http://localhost:5173
npm run dev- Start development server with HMRnpm run build- Build for productionnpm run preview- Preview production build locallynpm run lint- Run ESLint for code quality
- Click the microphone button to start voice recognition
- Speak clearly for best recognition accuracy
- The system automatically converts speech to text
- AI responses are automatically spoken aloud
- Toggle voice output on/off as needed
- Supports multiple voice options
- Speech synthesis restarts while already speaking
- Text rewrites in loops
- Conflicts between voice recognition and speech synthesis
// Stop all ongoing speech before starting new synthesis
const stopAllSpeech = () => {
window.speechSynthesis.cancel();
};
// Check if synthesis is currently active
const isSpeaking = () => {
return window.speechSynthesis.speaking;
};// Pause listening during speech synthesis
const pauseListeningDuringSpeech = () => {
if (recognition && recognition.continuous) {
recognition.stop();
}
};
// Resume listening after synthesis ends
speechUtterance.onend = () => {
if (recognition && isListening) {
recognition.start();
}
};const [isProcessing, setIsProcessing] = useState(false);
const handleSpeechToText = async () => {
if (isProcessing) return; // Prevent multiple calls
setIsProcessing(true);
// ... processing logic ...
setIsProcessing(false);
};import { useCallback } from 'react';
import { debounce } from 'lodash';
const debouncedProcessSpeech = useCallback(
debounce((text) => {
// Text processing logic
}, 300),
[]
);- Verify
speechSynthesis.cancel()is called before each new synthesis - Ensure voice recognition stops during speech synthesis
- Implement state system to prevent concurrent calls
- Add logging to debug event sequences
The application supports multiple AI providers. Configure your preferred service(s) in the .env file:
- OpenAI: GPT models for general conversation
- Anthropic: Claude models for advanced reasoning
- Groq: Fast inference for real-time responses
- Grok: Alternative AI provider option
- Chrome: Full support for all features
- Firefox: STT/TTS support may vary
- Safari: Limited Web Speech API support
- Edge: Good compatibility with modern versions
- Fork the repository
- Create a feature branch (
git checkout -b feature/new-feature) - Commit your changes (
git commit -am 'Add new feature') - Push to the branch (
git push origin feature/new-feature) - Create a Pull Request
This project is licensed under the MIT License - see the LICENSE file for details.
If you encounter any issues or have questions:
- Check the troubleshooting section above
- Review browser console for error messages
- Ensure API keys are correctly configured
- Verify microphone permissions are granted
- Built with React 18 and modern JavaScript features
- Uses Vite for fast development and building
- Implements best practices for voice application development
- Modular component architecture for easy maintenance
Happy coding! 🎉