Add denylist mechanism to distributed queries#7675
Add denylist mechanism to distributed queries#7675mike-myers-tob merged 4 commits intoosquery:masterfrom
Conversation
 directionless
left a comment
directionless
left a comment
There was a problem hiding this comment.
I'm a little confused by the logic in this PR. Working through it, I think, what it's doing is:
- When I query starts running, time stamp it
- When osquery stops, remove it
- Before a query runs, check that we don't have a record of the query running in the last hour. (This works because we remove queries on completion)
So a different way of saying that, is that this does nothing to limit resource usage (that's either the watchdog or the OS's responsibility), and this will ensure that a query either exists cleanly, or does not get to run again within DURATION.
That might be a reasonable choice. Might be worth documenting on https://osquery.readthedocs.io/en/latest/deployment/performance-safety/
The implementation feels like it only works because distributed queries are single threaded. Which makes me a little nervous, but might be a reasonable, simple choice today.
osquery/distributed/distributed.cpp
Outdated
| FLAG(uint64, | ||
| distributed_denylist_duration, | ||
| 3600, | ||
| "Seconds to denylist distributed queries (default 1 hour)"); |
There was a problem hiding this comment.
It's a bit of a nit, but I kinda want to quibble over this. I don't know that I feel strongly, but some questions...
- How do we handle the scheduled queries? I don't quickly see them in the
--helpoutput Should this be prefaced withwatchdog_?- I'd probably default to a 86,400 second block
There was a problem hiding this comment.
Indeed. Probably a good idea to match schedule queries deny-listing duration.
osquery/osquery/config/config.cpp
Line 329 in ed1a31a
There was a problem hiding this comment.
Changed default to 86400 seconds. 8a72448.
osquery/distributed/distributed.cpp
Outdated
| for (const auto& query : queries) { | ||
| auto request = popRequest(query); | ||
|
|
||
| if (request.query.size() < max_query_size) { |
There was a problem hiding this comment.
Feels weird. What happens if it's larger than max_query_size? Should we truncate? Hash?
There was a problem hiding this comment.
Speaking of hashes, does it make more sense to use one instead?
It solves the oddness around max-query size, and I suspect is somewhat smoother for it. Downside, is that one cannot see the query in question. Not totally sure what makes sense
There was a problem hiding this comment.
Indeed. I thought of using the hash too, but ended up using the actual query as key for better UX for troubleshooting/debugging.
I added this check as a safety-check. If the query is for some reason > 8 MB, then this new "distributed deny-listing" feature is just not used (to not mess up the storage basically).
There was a problem hiding this comment.
I can be persuaded, but it feels like a weird place. I dunno, maybe I'm old skool. Keys should be small. 😆
UX wise, I think the only place people will see this is in the logs, which can log with the full query anyhow, right?
There was a problem hiding this comment.
Agree. Changed to using SHA256 of the queries as key: 8a72448.
| const std::string kCarves = "carves"; | ||
| const std::string kLogs = "logs"; | ||
| const std::string kDistributedQueries = "distributed"; | ||
| const std::string kDistributedRunningQueries = "distributed_running"; |
There was a problem hiding this comment.
Is there a reason why we're creating another column family for this when we already have the distributed one?
As far as we've used them, I see them as high level categories. I know that RocksDB has also some specific behavior around how it handles their SST and some implications on performance, but what I'm also partially worried about is that this also creates again a non-backward compatible database.
The alternative is to simply provide a prefix to the keys to differentiate them from the others.
There was a problem hiding this comment.
Is there a reason why we're creating another column family for this when we already have the distributed one?
I wanted to implement this as an additional+simplest feature/code and not modify existing working code.
If we wanted to reuse "distributed" domain, then I would need to modify the following for example:
osquery/osquery/distributed/distributed.cpp
Lines 88 to 92 in ed1a31a
(I would need to differentiate "queryName -> query" from "query -> timestamp" key/values.)
but what I'm also partially worried about is that this also creates again a non-backward compatible database.
Why is adding new domains a non-backwards compatible change?
There was a problem hiding this comment.
I see what you mean; it would require changing the prefix of the keys and then write a migration step, as we have done in the past, to fixup the key names, and it would unfortunately be non-backward compatible anyway.
I should've created a prefix for those keys when I moved it to the new domain ^^'
Anyway, adding column families (the domain) is non-backward compatible because older versions of osquery won't attempt to open that new column family and RocksDB will error out, due to the fact that not all column families have been opened.
Something like this:
Rocksdb open failed (4:0) Invalid argument: You have to open all column families. Column families not opened: distributed
There was a problem hiding this comment.
Oh... I see, that makes sense, thanks for the clarification.
- Curious what the plan forward is:
- Is supporting rollback of osquery version important for users? (am guessing that there were issues when e.g. carves were introduced to osquery, which introduced a new column family)
- Should osquery document adding new domains for new features is not supported or discouraged unless necessary?
(Maybe there are docs around this and I missed them, sorry.)
A non-breaking alternative is to use the "default" column family, but would require careful use of prefixes throughout the application. It also depends on the feature; for this particular feature the key space will not grow considerably (1 entry per deny-listed query).
There was a problem hiding this comment.
I think it's fine to add the new domain for now, but I think this definitely raises the question on what we should do going forward.
I think it's mostly an annoyance because the user maybe wants to test a new version, finds a problem, but then it can't go back, and if not careful then it can lose the data (logs and events) that were stored.
I'm not sure but maybe it's possible to just list all the column families in the DB and use that list to open the DB, so that we don't have to explicitly list them and the unused ones are ignored.
Correct. Nit: step 2 is actually:
Correct. This PR/solution is mimicking the current implementation for deny-listing of scheduled queries (but for distributed queries): osquery/osquery/config/config.cpp Lines 1080 to 1089 in ed1a31a I used a totally separate "domain" to not mix distributed and schedule functionality. |
I'm not sure I follow, the schedule functionality uses the |
Let me know if #7675 (comment) makes sense. |
Thanks for going through the logic with me. I think it makes sense. I would like to request we document this, and maybe the scheduled behavior. Probably in https://osquery.readthedocs.io/en/latest/deployment/performance-safety/ somewhere? |
Added docs to |
directionless
left a comment
There was a problem hiding this comment.
I didn't test this, but I think it looks good.
|
Merging this now, with follow-up potential in #7712 and with the plan to test this in pre-release testing. |
Implements proposal #7658.
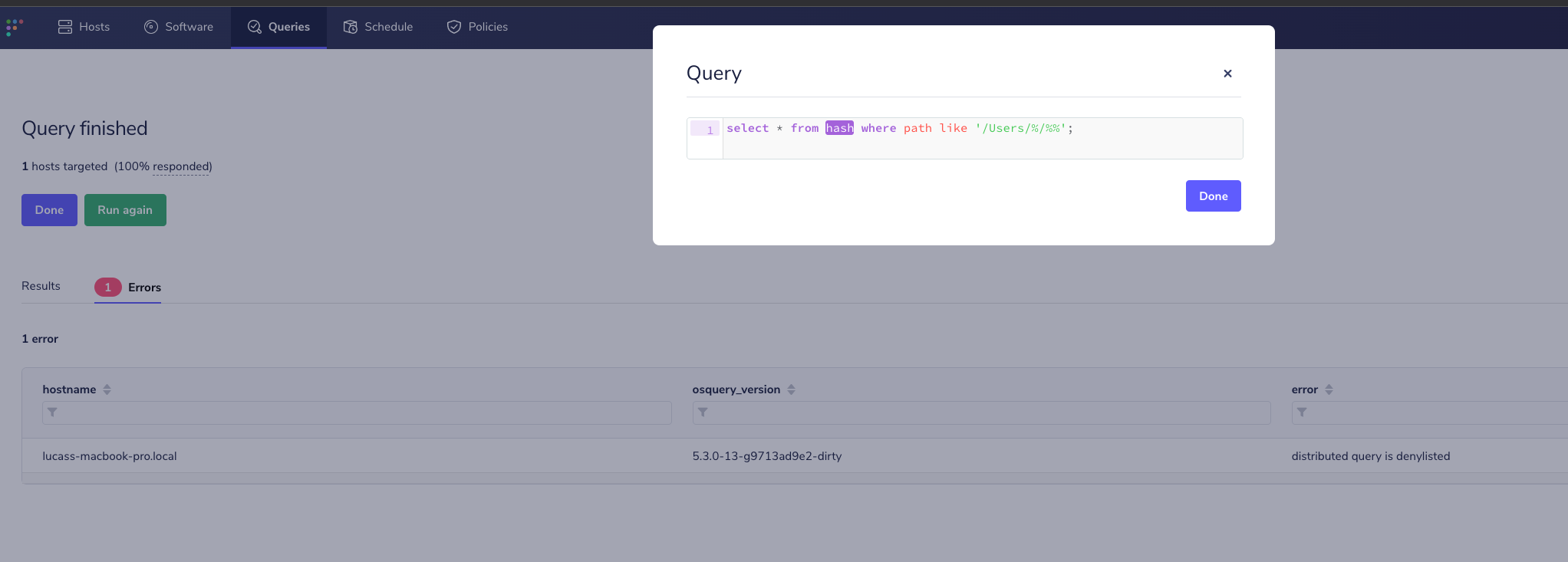
Am not sure about the default value for denylisting expiration, my guess is we could start with a default value of
1h.Apart from the added unit tests I manually tested this with Fleet, by running an expensive live query twice (first time to cause the watcher to kill the worker, second time to verify denylisting):