Artists like Claude Monet are recognized for the unique styles of their works, such as the unique colour scheme and brush strokes. These are hard to be imitated by normal people, and even for professional painters, it will not be easy to produce a painting whose style is Monet-esque. However, thanks to the invention of Generative Adversarial Networks (GANs) and their many variations, Data Scientists and Machine Learning Engineers can build and train deep learning models to bring an artist's peculiar style to your photos.

- Objectives
-
Setup
- Installing Required Libraries
- Importing Required Libraries
- Defining Helper Functions
- What is Image Style Transfer in Deep Learning?
- CycleGANs
- A quick recap on vanilla GANs
- What's novel about CycleGANs?
- Data Loading
- Building the Generator
- Defining the Downsampling Block
- Defining the Upsampling Block
- Assembling the Generator
- Building the Discriminator
- Building the CycleGAN Model
- Defining Loss Functions
- Model Training
- Training the CycleGAN
- Visualize our Monet-esque photos
- Loading the Pre-trained Weights
- Visualizing Style Transfer Output
In this project I am going to:
- Describe the novelty about CycleGANs
- Define Cycle Consistency Loss
- Describe the complicated architecture of a CycleGAN
- Practice the training deep learning models
- Implement a pre-trained CycleGAN for image style transfer
For this project, we will be using the following libraries:
numpyfor mathematical operations.Pillowfor image processing functions.tensorflowfor machine learning and neural network related functions.matplotlibfor additional plotting tools.
Image Style Transfer can be viewed as an image-to-image translation, where we "translate" image A into a new image by combining the content of image A with the style of another image B (which could be a famous Monet painting).
GANs are a family of algorithms are use learning by comparison. A vanilla GAN has two parts, a Generator network which we denote by
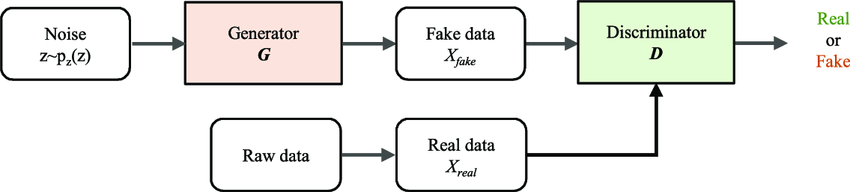
Vanilla GANs use adversarial training to optimize both
First of all, unlike other GAN models for image-to-image translation, CycleGANs do not require paired training data. For example, if we are interested in translating photographs of winter landscapes to summer landscapes, we do not require each winter landscape to have its corresponding summer view exist in the dataset. This allows the development of image translation models for tasks where paired training datasets are not available.
Besides, CycleGAN uses the additional Cycle Consistency Loss to enforce the forward-backward consistency of the Generators.
What is forward-backward consistency?
As a simple example, if we translate a sentence from English to French, and then translate it back from French to Engligh, we should expect to get back the original english sentence.
Why we need forward-backward consistency?
With one
Hence, to ensure that the mapping
The loss that incurred during the image translation cycle, i.e., the discrepancy between
The unpaired dataset comes from a Kaggle competition called I'm Something of a Painter Myself. The original dataset contains around 400MB of images, but for this project we will only use 300 Monet paintings and 300 photos for training the CycleGAN. The followinig cell downloads the zipped dataset.
The CycleGAN Generator model takes an input image and generates an output image. To achieve this, the model architecture begins with a sequence of downsampling convolutional blocks (reduce the 2D dimensions, width and height of an image by the stride) to encode the input image.
To define a downsampling block, we will use the instance normalization method instead of batch normalization as our batch size is very small. InstanceNorm transforms each training sample independently over multiple channels, whereas BatchNorm does that to the whole batch of samples over each channel. The intent is to remove image-specific contrast information from the image, which simplifies the generation and results in better generated images.
Next, the Generator uses a number of Upsampling blocks to generate the output image.
Upsampling does the opposite of downsampling and increases the dimensions of the image. Hence, we use the Conv2DTranspose API from keras to create TransposeConvolution-InstanceNorm-ReLU layers to build the block.
The Generator uses a sequence of downsampling convolutional blocks to encode the input image, a number of residual network (ResNet) convolutional blocks to transform the image, and a number of upsampling convolutional blocks to generate the output image.
The ResNet blocks essentially skip connections to help bypass the vanishing gradient problem through concatenating the output of downsampling layers directly to the output of upsampling layers. You will see that we concatenate them in a symmetrical fashion in the following code cell.
The discriminator model takes a
This can be implemented directly by borrowing the architecture of a somewhat standard deep convolutional discriminator model. Thus, it can be built by mainly using the Convolution-InstanceNorm-LeakyReLU layers.
Although the InstanceNorm method was designed for generator models, it can also prove effective in discriminator models.
Our Discriminator model will be built using 4 Convolution-InstanceNorm-LeakyReLU layers with 64, 128, 256, and 512 sized 4 filters, respectively. After the last layer, we apply a convolution to produce a 1-dimensional output.
In order to ensure that the mapping between images from two domains is meaningful and desirable, we enforce forward-backward consistency by involving two mappings:
This means, our CycleGAN model needs two generators. One for transforming photos to Monet-esque paintings and one for transforming Monet paintings to be more like photos.
Since we have two generators, we would naturally need two discriminators to "discriminate" the work of each of them. This leads to our definition of monet_generator, photo_generator, monet_discriminator, and photo_discriminator in the next cell.
A perfect discriminator shoud output all 1s for a real image and all 0s for a fake image. Hence, the discriminator_loss compares the discriminator's prediction for a real image to a matrix of 1s and the prediction for a fake image to a matrix of 0s. The differences are quantified using Binary Cross Entropy.
The CycleGAN paper suggests dividing the loss for the discriminator by half during training, in an effort to slow down updates to the discriminator relative to the generator.
In this section, we will compile and train a CycleGAN. Since our networks have too many parameters (one generator alone has 54M and a discriminator has 2M) and Skills Network Labs currently doesn't have any GPUs available, it will take hours to train a sufficient number of epochs with a CPU such that the model can do a decent job in transfering image styles.
Therefore, we will train the model for one epoch in this lab, which includes 300 iterations.
This is a screenshot of the CycleGAN's training history. Even though only the monet generator is needed for the style transfer task, but we can see that the losses of all 4 networks: monet generator, monet discriminator, photo generator, and photo discriminated, were being optimized.

{kind=link}
Finally! We will visualize the style transfer output produced by monet_generator_model. We take 5 sample images that are photos of beautiful landscapes in the original dataset and feed them to the model.
