A semantic query workbench for structured data.
Reckoner lets you query any dataset by meaning — not by column name, table structure, or JOIN logic. Drop in a CSV or connect a database. Ask questions in plain semantic terms. Get results in milliseconds with a full execution trace showing exactly how the answer was found.
Built on SNF (Semantic Normalized Form) and the Portolan planner.
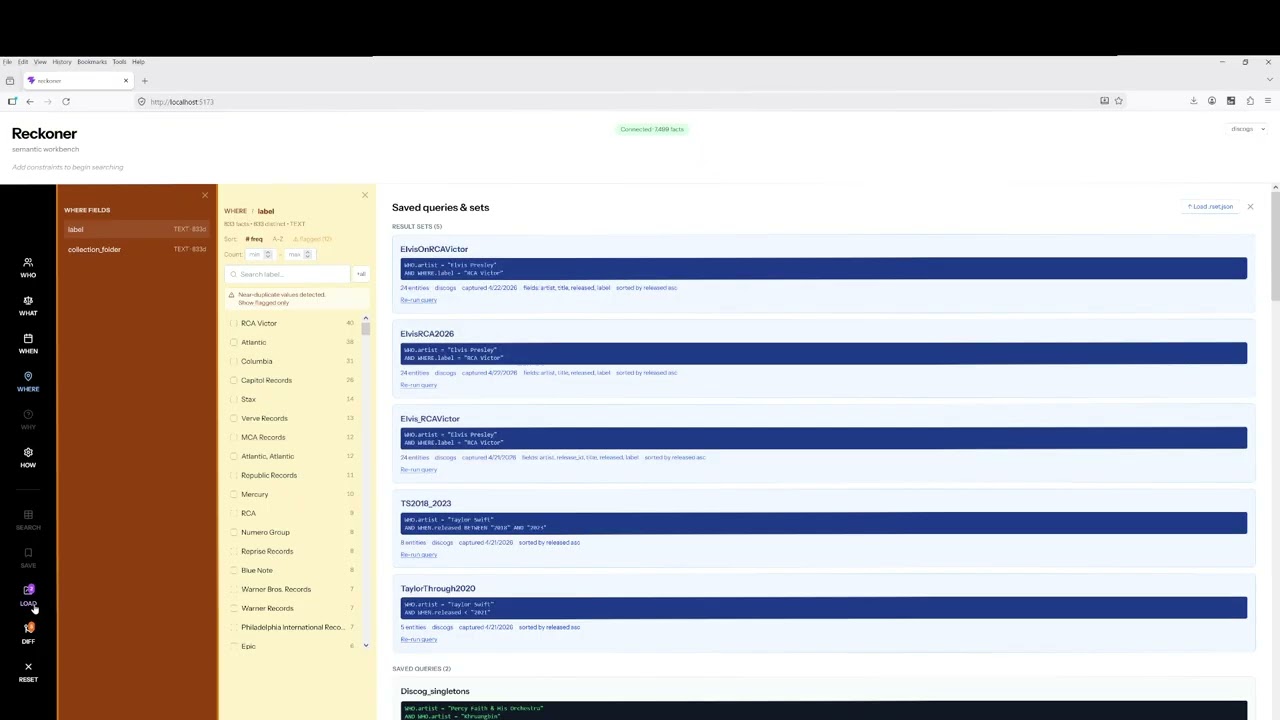
A record collection, a data quality catch, a diff between two named sets, and a substrate switch. 5 minutes. No setup required to watch.
You have a record collection. You want everything by Miles Davis released between 1955 and 1965 on Blue Note. In Reckoner:
WHO artist = "Miles Davis"
WHEN released BETWEEN "1955" AND "1965"
WHERE label = "Blue Note"
Results appear in ~5ms. The trace shows:
PROBE 1.2ms EXEC 3.8ms TOTAL 5.0ms
WHO artist "Miles Davis" → anchor 52
WHEN released 1955–1965 → 14
WHERE label "Blue Note" → 6
6 of 52 entities matched 88% skipped
The same workbench works on a law firm's matter database, a library catalog, a film archive, court opinions, or any structured dataset you can describe in terms of who, what, when, where, why, and how.
- Python 3.10+
- Node.js 18+
- pip, npm
Optional (for live Postgres sources):
- PostgreSQL 14+
This gets you running with the three demo substrates that ship in this repo. You can explore everything Reckoner does without loading your own data first.
git clone https://github.com/peirce-lang/reckoner
cd reckoner
pip install -r requirements.txt
npm installpython reckoner_api.pyYou should see:
============================================================
Reckoner API — Python backend
Model Builder endpoints: /api/mb/*
============================================================
[registry] Loaded discogsv1: 833 entities ...
[registry] Loaded disney: 659 entities ...
[api] Model Builder endpoints loaded at /api/mb
Open a second terminal:
cd reckoner
npm run devYou should see:
VITE v5.x.x ready
Local: http://localhost:5173/
http://localhost:5173
1. In the top-right dropdown, select discogsv1
2. Click WHO in the left sidebar → click artist → type Miles Davis → click his name
3. Click WHEN → click released → set range 1955 to 1965
You should see a small set of results with a trace like:
PROBE 1.2ms EXEC 3.8ms TOTAL 5.0ms
WHO artist "Miles Davis" → anchor 52
WHEN released 1955–1965 → 6
6 of 52 entities matched 88% skipped
Now remove the WHEN constraint (click the × on the chip).
Watch what happens: the result set grows, the trace updates, the skipped % drops.
That's the core of what Reckoner does — each constraint permanently narrows the candidate set. Adding and removing constraints changes the shape of the answer in real time.
(You do not need this to try Reckoner. Use the demo datasets above first.)
To load your own CSV, Excel file, or Postgres table, you'll also need snf-model-builder — the browser wizard that prepares data for Reckoner. It's a separate repo with the wizard frontend; the Python backend it talks to is already running inside reckoner_api.py (the same backend you started above).
Clone snf-model-builder next to your reckoner folder:
# from wherever you cloned reckoner — clone the wizard alongside it
cd ..
git clone https://github.com/peirce-lang/snf-model-builder
cd snf-model-builder
npm installAfter this you should have two folders side by side:
your-projects/
├── reckoner/
└── snf-model-builder/
With python reckoner_api.py already running (from the Quickstart above), open a third terminal:
cd snf-model-builder
npm run devYou should see:
VITE v5.x.x ready
Local: http://localhost:5174/
Open http://localhost:5174 — that's the Model Builder wizard.
- Drop a CSV or Excel file (or connect directly to a Postgres table)
- Map your columns to semantic dimensions (WHO / WHAT / WHEN / WHERE / WHY / HOW)
- Review pre-ingest flags — variant candidates, null coverage, singletons
- Declare a nucleus — the column (or combination) that uniquely identifies each row
- Name your dataset and pick a target (DuckDB for local use)
- Compile → download the
.duckdbfile → drop it inreckoner/substrates/→ restartreckoner_api.py
Your data is queryable in under an hour. No schema authoring. No code required.
The substrates/ folder ships with:
| Dataset | Entities | Source |
|---|---|---|
discogsv1 |
833 records | Discogs collection export |
disney |
659 films | Disney filmography |
shibuya |
103 items | Shibuya Publishing catalog |
To use the Discogs demo with your own collection:
- Export your Discogs collection as CSV (Discogs → Collection → Export)
- Open Model Builder at
http://localhost:5174 - Drop the CSV — columns are auto-mapped
- Compile and add to
substrates/
Reckoner connects to live Postgres substrates via .env:
cp .env.example .envEdit .env:
PG_HOST=localhost
PG_PORT=5432
PG_DATABASE=your_database
PG_USER=your_user
PG_PASSWORD=your_password
Postgres substrates are built by running the SNF views script produced by Model Builder against your database. See snf-model-builder for the SQL path.
Boolean routing — every constraint is a posting list intersection. No full table scans. No query planner hints required.
Portolan planner — probes live cardinalities before executing. Anchors on the most selective constraint. The shrinking board: each constraint permanently reduces the candidate set. 98% skipped is normal.
Execution trace — every query shows probe time, execution time, step-by-step cardinality reduction, and the exact constraints that matched each result.
Admissibility checking — contradictory constraints are caught before execution. You see VALID / REWRITE / REJECT with a plain English explanation, not an empty result set.
Export — CSV, XLSX, JSON, Parquet. Row-level selection before export. Query provenance travels with the data.
Set operations — Diff (A − B), Union (A ∪ B), Intersect (A ∩ B), Join (A ⋈ B).
| Dimension | Meaning | Examples |
|---|---|---|
| WHO | People, organizations, agents | artist, author, attorney, publisher |
| WHAT | Things, topics, identifiers | title, subject, ISBN, format |
| WHEN | Dates, times, periods | released, date_filed, year |
| WHERE | Places, locations, jurisdictions | label, office, city, country |
| WHY | Reasons, types, purposes | genre, matter_type, classification |
| HOW | Methods, formats, conditions | medium, condition, version |
These are not philosophical categories — they are operational coordinates. A record collection, a law firm's matters, a library catalog, and a film archive all have WHO and WHAT and WHEN. The dimensions are the common ground that makes any dataset queryable the same way.
After cloning, this repo looks like:
reckoner/
├── src/ ← React frontend
│ ├── ReckonerSNF.jsx
│ ├── TrieValuePanel.jsx
│ ├── ResultCard.jsx
│ └── main.tsx
├── substrates/ ← drop .duckdb files here
├── reckoner_api.py ← Python backend (FastAPI)
├── model_builder_api.py ← Model Builder router (mounted into reckoner_api.py)
├── postgres_adapter.py ← Postgres substrate adapter
├── duckdb_adapter.py ← DuckDB substrate adapter
├── .env.example ← copy to .env for Postgres
├── requirements.txt
├── package.json
└── vite.config.js
If you also clone snf-model-builder (for loading your own data), put it next to reckoner/ — both READMEs assume that layout:
your-projects/
├── reckoner/ ← this repo
└── snf-model-builder/ ← the wizard frontend (companion repo)
The Model Builder API contract (/api/mb/ endpoints) is stable as of v1.0. Third-party clients — native apps, CLI tools, VS Code extensions — are welcome and encouraged. Clients that talk to the local API are not subject to AGPL. See snf-model-builder for the full API spec.
AGPL-3.0. See LICENSE.
Part of the peirce-lang ecosystem.