Project on Unsupervised Machine Learning - KMeans and DBScan

Description de l'entreprise 📇
Uber est l'une des startups les plus célèbres au monde. Cela a commencé comme une application de covoiturage pour les personnes qui n'avaient pas les moyens d'acheter un taxi. Maintenant, Uber a étendu ses activités à la livraison de nourriture avec Uber Eats, la livraison de colis, le transport de marchandises et même le transport urbain avec Jump Bike et Lime que la société a financés.
L'objectif de l'entreprise est de révolutionner le transport à travers le monde. Il opère maintenant dans environ 70 pays et 900 villes et génère plus de 14 milliards de dollars de revenus ! 😮
L'un des principaux points douloureux que l'équipe d'Uber a trouvé est que parfois les chauffeurs ne sont pas là lorsque les utilisateurs en ont besoin. Par exemple, un utilisateur peut se trouver dans le quartier financier de San Francisco alors que les chauffeurs Uber recherchent des clients à Castro.
(Si vous n'êtes pas familier avec la région de la baie, consultez Google Maps)
Même si les deux quartiers ne sont pas si loin, les utilisateurs devraient encore attendre 10 à 15 minutes avant d'être pris en charge, ce qui est trop long. Les recherches d'Uber montrent que les utilisateurs acceptent d'attendre 5 à 7 minutes, sinon ils annuleraient leur trajet.
Par conséquent, l'équipe de données d'Uber aimerait travailler sur un projet où son application recommanderait des zones chaudes dans les grandes villes à n'importe quel moment de la journée.
Uber a déjà des données sur les ramassages dans les grandes villes. Votre objectif est de créer des algorithmes qui détermineront où se trouvent les zones chaudes dans lesquelles les conducteurs devraient se trouver. Par conséquent, vous allez :
Créer un algorithme pour trouver des zones chaudes Visualisez les résultats sur un joli tableau de bord Portée de ce projet 🖼️
Pour commencer, Uber veut essayer cette fonctionnalité à New York. Par conséquent, vous ne vous concentrerez que sur cette ville. Les données peuvent être trouvées ici :
👉👉 Données du voyage Uber 👈👈
Vous n'avez qu'à vous concentrer sur New York pour ce projet
Pour vous aider à réaliser ce projet, voici quelques conseils qui devraient vous aider :
Le regroupement est votre ami
Les techniques de regroupement sont parfaitement adaptées au travail. Pensez-y, tous les lieux de ramassage peuvent être rassemblés en différents groupes. Vous pouvez ensuite utiliser les coordonnées du cluster pour épingler les zones chaudes 😉
Créer des cartes avec plotly
Consultez la documentation Plotly, vous pouvez créer des cartes et les remplir facilement. Évidemment, il y a d'autres bibliothèques, mais celle-ci devrait faire le travail assez bien.
Commencez petit, de plus en plus
Même si Uber veut avoir des zones chaudes par heure et par jour de la semaine, vous devriez d'abord commencer petit. Choisissez un jour à une heure donnée, puis commencez à généraliser votre approche.
Pour mener à bien ce projet, votre équipe doit :
- Avoir une carte des "hot-zones" en utilisant des librairies (plotly ou autre). -library (plotly or anything else).
- Vous devriez au moins décrire les zones chaudes par jour de la semaine.
- Comparez les résultats avec au moins deux algorithmes non supervisés comme KMeans et DBScan. Vos cartes devraient ressembler à ceci :
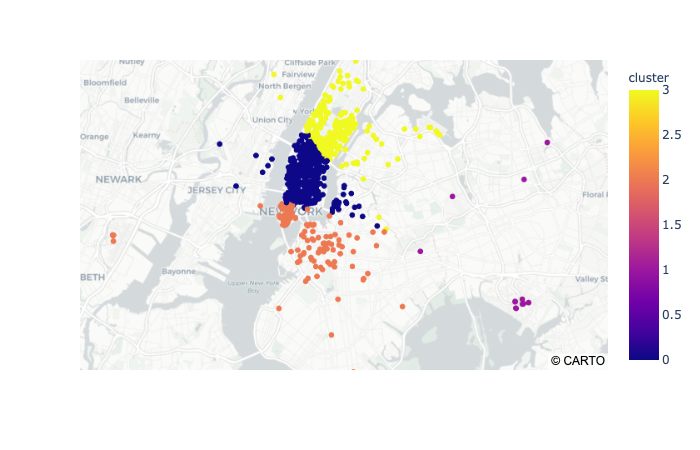
Pour lancer le projet,
-
Cloner le dépôt :
git clone hhttps://github.com/pradelf/uberpickups.git
-
Installerles différents [packages]
-
Installer les librairies python
pip3 install -r requirements.txt
Distribué sous la licence MIT, voir LICENSE.txt pour plus d'information.