log :: 2025‐10
- I had to introduce a "simulation" feature for the
pure-stagecrate since the simulation now requires therandcrate to randomly select the next runnable to execute. Unfortunately therandcreate cannot be used when compiling towasm. - I am now displaying the external effects as they occur on each stage.
- The hard part was the "sync" external effects, like store effects, which are not polled but executed right away.
This means that they were not included in the
TraceBuffer. In order to fix this I introduced aSyncEffectBoxwhere aStageEffect::ExternalSynceffect just containing the effect typetag_name to be able to visualize it later. This feels like a hack at this stage and probably @rkuhn will want to find a better way to pass this information around.
- I improved the display of the execution of stages during a simulation.
- While working on the simulation I realized that some headers were arriving twice at the
forward_headerstage. - I debugged this and this happens on a pretty specific case of a rollback (with 3 peers and a tree of headers of depth 10) that should not produce a fork.
- The correctness was still ok in that case (the best chain stays the best downstream) but this is not desirable and potentially marks the current node as adversarial.
- I added a check in our tests, in both the property test for the chain selection and in the simulation to make sure that we don't send. duplicate information downstream.
- One interesting this is:
- I tried to reproduce this issue with the property test for the chain selection (in
headers_tree.rs) and even with 1M tests I was not able to trigger it. - On the other hand it was easy to reproduce with the simulation.
- I guess that the simulation, by running some random execution of stages introduces more random interleaving for the
processing of events arriving at the
select_chainstage.
- I tried to reproduce this issue with the property test for the chain selection (in
- I also restructured the outputs of the simulation:
- Files are produced by default in
target/teststo avoid polluting the source directory. - There is one directory for simulation run, timestamped.
- This one contains the simulation trace (in CBOR + JSON format)
- The JSON traces can be animated with the
simulation/amaru-sim/tests/animations/traces.htmlpage.
- Then one directory per test, inside the simulation run, timestamped.
- This one contains the generated entries (messages sent by peers) and "actions" (executable directly by the
HeadersTree). - The generated entries traces can be animated with the
simulation/amaru-sim/tests/animations/entries.htmlpage. - The actions can be copy-pasted directly to a unit test in
headers_tree.rsto replay a chain selection bug.
- This one contains the generated entries (messages sent by peers) and "actions" (executable directly by the
- Files are produced by default in
- I still need to add a few elements of visualization, in particular external effects, before submitting a full PR.
From Amaru discord channel:
I am not sure there any public documents related to this.
An eclipse attack happens when an attacker control all the upstream peers of a node. This makes it possible to carry out for example double spend attacks on that operator by feeding an alternative chain.
The cardano-node's big ledger peers is the main protection against eclipse attacks. They are picked randomly weighted by stake from the top 90% of stake pools. With the honest stake assumption it is likely that any big ledger peer picked is honest. Since the pick is made from the ledger it is not something that the attacker can influence.
While it is possible any node to become eclipse, it is very unlikely to remain eclipse for a long time (hours).
A single honest peer (this doesn't have to be a big ledger peer) is enough to break the eclipse attack.
When the node is on tip it keeps connections to 5 big ledger peers. 0.5^5=0.03, so less then 3% chance of having picked all big ledger peers controlled by the attacker. When the node is behind the tip genesis-mode kicks in and the node talks only to 30 big ledger peers which turns the probability of having picked no honest peer to less than 1 in a billion.
As an added bonus because the decision on which peers to replace is made by tracking which peers provided the node with new headers and blocks first a would be attacker would have to start by being a very helpful peer. That is be serving headers and blocks for the main chain as quickly as possible.
An attacker would only peershare about his own nodes so peersharing doesn't really help.
The (Haskell) node operates in 2 modes: Praos or Genesis, where the latter is active iff the node is more than 20 minutes behind the best known chain. It maintains different lists of potential peers:
- big ledger peers are relays from registered stake pools representing 90% of the stake
- normal ledger peers are all the registered stake pools' relays
- trusted roots are pre-defined peers from local configuration
- untrusted root are pre-defined from local configuration
- peer sharing relays propagated through eponymous protocol
It has 2 relevant configuration parameters:
-
$k$ is the target number of peers -
$l$ is the target number of local roots peers
In Praos mode:
- 5 peers are randomly selected from big ledger peers set based on linear stake distribution
-
$k - l$ peers are selected at random from the peer sharing and normal ledger peers set using the square root of stake as probability distribution -
$l$ connections to local roots
In Genesis mode:
- 30 peers are randomly selected from big ledger peers set based on linear stake distribution
- all trusted roots are selected.
Discussing short term and some medium terms goals for Amaru we would like to work on:
-
Testing: Goal for EOY is to demonstrate Amaru is a proper relay by running simulation and AT tests with the following topology:
- 2 amaru nodes Amaru1 and Amaru2 are connected to each other
- each is used as relay by 3 cardano-node BPs
- network still converge correctly
-
Mempool: This is needed for proper transaction propagation which is mandatory for implementing properly a relay node. This can come in 2 versions:
- Basic: build enough mempool capabilities to pull and propagate transactions:
- manage a tx buffer, check tx against current ledger state, remove txs as we adopt them in blocks fetched
- implement tx client pulling txs from downstream peers
- implement tx server serving txs to upstream peers
- Leios ready: for next year
- Basic: build enough mempool capabilities to pull and propagate transactions:
- Key management: build some solution to manage block producers keys "properly". Talk with people with SPO experience on what this solution should look like and implement first version. We already have CLI capabilities for managing VRF and KES keys, but it's unclear what solution would suit best SPOs: do we need some kind of signing agent? is a CLI enough? How would Amaru handle key changes?
- Block forging: requires mempool logic, for later
-
Observability (metrics, traces, logs): we need to unify and better document what we currently do
- ensure structured logging everywhere
- proper classification of log
- cleaner traces (maybe provide distributed tracing capability, eg. using header hash as trace id uniformly across nodes)
- update documentation
-
Ledger:
- Phase 2 validation: integration of plutus VM, implement all Plutus versions
- Complete ledger rules: cover existing gaps
- Epoch boundary offset: current implementation might lead to discrepancies in ledger state because we compute epoch boundary state in effect
$k$ blocks after the boundary is crossed
-
Networking:
- overhaul network stack to be covered by pure-stage and simulation
- (later) implement p2p
- Bootstrapping: some work in progress, we plan to join forces with people from HAL team to streamline snapshot extraction process from cardano-node DB and mithril snapshot
- Hard fork: this is a known unknown as it's unclear how much work we'll need to do for the next hard fork which is due in Feb/March
- I have started a small HTML page to visualize the execution of messages across all stages during the simulation.
- Once issue I first faced was how to export the trace data as JSON. This is not entirely trivial since part of this data
is dynamic (
dyn SendData):- I had to add a function to recover the underlying data as
SendDataValueand: 1. provide a display instance to be able to output more compact logs when necessary (otherwiseSendDatauses aDebuginstance which is not very nice in logs.) - I also added some
to_jsonfunctions to outputTraceEntrys as JSON. At some stage, part of that data end-up beingSendDatawhich I can only display as a string, which implicitly used a string representation of CBOR. Concretely this means that something like aPoint::Specificvariant, that is deeply nested in the trace data, ends up showing a header hash as aVec<u8>. That doesn't not make it easy to follow. - Eventually, I managed to export something as JSON and extract some useful data. That allows me to make some progress but that's not great.
- I had to add a function to recover the underlying data as
- Then I ran the visualization and realized that,... even we now randomly execute effects in a random order in a node, we feed the node the messages one by one. We should instead feed a message, make a bit of progress, feed another message, make a bit of progress, etc... => So my next step will be to see how I can "run the world" (in simulation parlance) more granularly.
- Those tests have been failing sometimes on CI. Hopefully this is fixed now with this commit.
- One aspect of simulating the amaru node consists in controlling the interleaving of the threads of execution.
- I've added some support for randomly executing a given interleaving, controlled by the simulation seed.
- I've also added a
Displayinstance toTraceEntryto be able to log a trace in a more compact format than the one usingDebuginstances for theSendData. - Now the more interesting questions are:
- What kind of useful coverage information / statistics can we produce for the random interleavings?
- Would it be useful to visualize various interleavings? What would that look like?
- Can we find bugs, or at least introduce a bug and see if we can find it when running the simulation?
- There was indeed a bug in the chain selection algorithm introduced by the recent changes in how we access the data backing-up the headers tree (see the notes on PR #521).
- It is a bit frustrating to realize that our tests didn't catch the regression at the time. I suppose that is because the data generation was not good enough.
- I also had to rework a bit the oracle used in the property test for that algorithm in order to work ok when we have rollbacks beyond the best chain anchor.
- There is now a single-page HTML that shows:
- The tree of generated headers.
- The arrival of messages with their time for different peers as labels on the tree nodes as time passes. This means that we see rollbacks as labels going back up the tree.
- A highlighted node representing the tip of the current best chain
- The data is generated from one of the test.
- That has already proved helpful for tweaking the generation of data and inspecting the results.
- The PR is still not up for review because the chain_selection property test is now broken:
- I think that this is due to the max_length of the headers tree and the fact that we generate trees of headers with a greater depth.
- I don't know yet if the fix should be in the generation or maybe just the oracle (For now I don't think there's a bug in the algorithm)
- Having a hard time finding the right angle to this problem as the current code does not lend itself well to the design I am thinking of
- I have drafted a new
ChainFollower::newimplementation that takes into account the anchor and the intersection point, leveraging a dedicatedChainStorefunction to lookup the most recent intersection on the chain given the list of points a client sent- This does not yet include the iterator for the immutable part up to the anchor
- While working on those changes I noticed some diagnostic functions were not needed in the
ReadOnlyChainStoreinterface and moved them out to simplify alsoEffectsand in memory implementation - The next major step is to actually store the chain indexed by slots in order to be able to easily iterate over those headers. I looked at the
headers_treecode where the store is updated with the new best chain but it would be tricky to change as in most places we only use theHeaderHashand not thePoint, therefore we don't have the slot information we need- We could push that logic in the
update_best_chainorset_best_chain_hashfunctions, eg. given a hash retrieve the corresponding header and then update the best chain but this would annoyingly put some "business logic" (knowing when to roll forward and rollback) into the store itself
- We could push that logic in the
- I am now considering implementing this in an additional stage, after the
select_chainstage, that would use theDecodedChainSyncEventto update the stored best chain:- on a
Forward, add the given header's slot to the chain with the hash as value - on a
Rollback, just rollback the stored chain at a slot before the rollback - This would have the benefit of isolating this logic and not requiring significant changes to the existing stages or store interface
- on a
- The arrival times of messages on a simulated node are now properly correlated with the header slots so that the first messages arriving at the node have slots 1, 2, 3, ... and arrival times around 1s, 2s, 3s, etc
- The arrival times are generated with a small jitters that varies from (upstream) peer to peer and which is occasionally negative.
- I've started to vibe code an animation to show the arrival of messages on the node in order to show for example that the same FWD header can arrive at 2 different times from different peers. But during the night (yes...) I had a better idea for showing what's happening in the simulation: show the whole generated tree of headers and when each header arrives at the node for a given peer. Let's see if this can be nicely vibe-coded :-).
- Working on making chain sync for downstream clients less of a memory hog
- Started with encapsulating more
ClientStatewhich ahs been renamedChainFollower: It's now more an opaque structure with proper methods, and thenewfunction ensures the state is primed correctly based on the intersection points provided by the client, it replaces the previousfind_headersfunction- We are still filling the internal queue with all headers from intersection point to current tip
- But at least we have the store available to extract an iterator
- and tests are expressed through the interface of the
ChainFollower, eg. thenext_op()function
- Tricky part will be to update the tests and the test infrastructure as we now have more cases depending on whether or not the intersection point is in the immutable or mutable part of the chain DB
- While understanding the
find_headersfunction I realised the implementation of chain sync protocol was wrong as we were not sending systematically aRollbackright after the intersection point which should actually be the case (it's prescribed in the network design spec) - I put up a small PR to fix that and now trying to test it IRL
- We are now generating data in a simpler way but with a bit more edge cases:
- The number of forks have been reduced to 2 main forks at 1/3rd and 2/3rd of the main spine (but this is recursive for subtrees).
- So the main parameters controlling the generated data now are the number of upstream peers and the length of the best chain.
- In the generated data there is always at least one peer that behaves exactly like another peer (which is the common case).
- There is a unit test for the generated data to make sure that we don't regress on what we expect to generate.
- The size of the "maximum fragment" (2160 in production) is adjusted to be less than the generated best chain length to be in a situation where the anchor of the best chain has to be updated.
- Some data structures have been introduced to keep track of additional information when generating data:
-
GeneratedTreeabout the tree of headers that is used to generate upstream messages. -
GeneratedActionsabout the actions (roll forward and rollback) generated for each peer.
-
- This data is presented at the end of each test run for inspection.
- The
ChainStateis created when the peer connects to us and we compute the intersection. The chain state's main purpose is to hold aDequeueofChainSyncMessagesthat are received from the pipeline (eg. chain selection. There's oneChainStateper connected peer, and every time we receive a new chain selection event we duplicate the message to all connected peers - Currently, when the
ChainStateis created we front-load theDequeuewith the full list ofRollForwardoperations between the intersection point and the tip at the time of creation, which takes a lot of time (>50s on preprod) and consumes a lot of memory.- Memory footprint has been significantly reduced by only storing hashes and not the full headers but it's still not quite right: with 100 lagging peers connected, we would need about 20GB of RAM just to store that data
- The interaction between the various actors/stages is somewhat tricky and I did not want to have to modify it too much, as we will certainly revisit it again once we support P2P, so I have been looking for a solution that's minimally invasive
- The idea would be to extend the
ChainStatestructure to store an iterator over theReadOnlyChainStorebetween the intersection point and the anchor, and to only fill theDequeuewith forward operations between the anchor and the tip which caps the amount of data to 2160 x 32B (header hash size) = 64kB / peer - The
ChainState'snext_opmethod would then:- either serve a
Forwardop constructed from thenext()method of the iterator until it's empty - or dequeue elements the queue from once the iterator is empty
- either serve a
- of course, if the intersection point is between the anchor and tip the iterator part is skipped and we serve operations directly from the queue
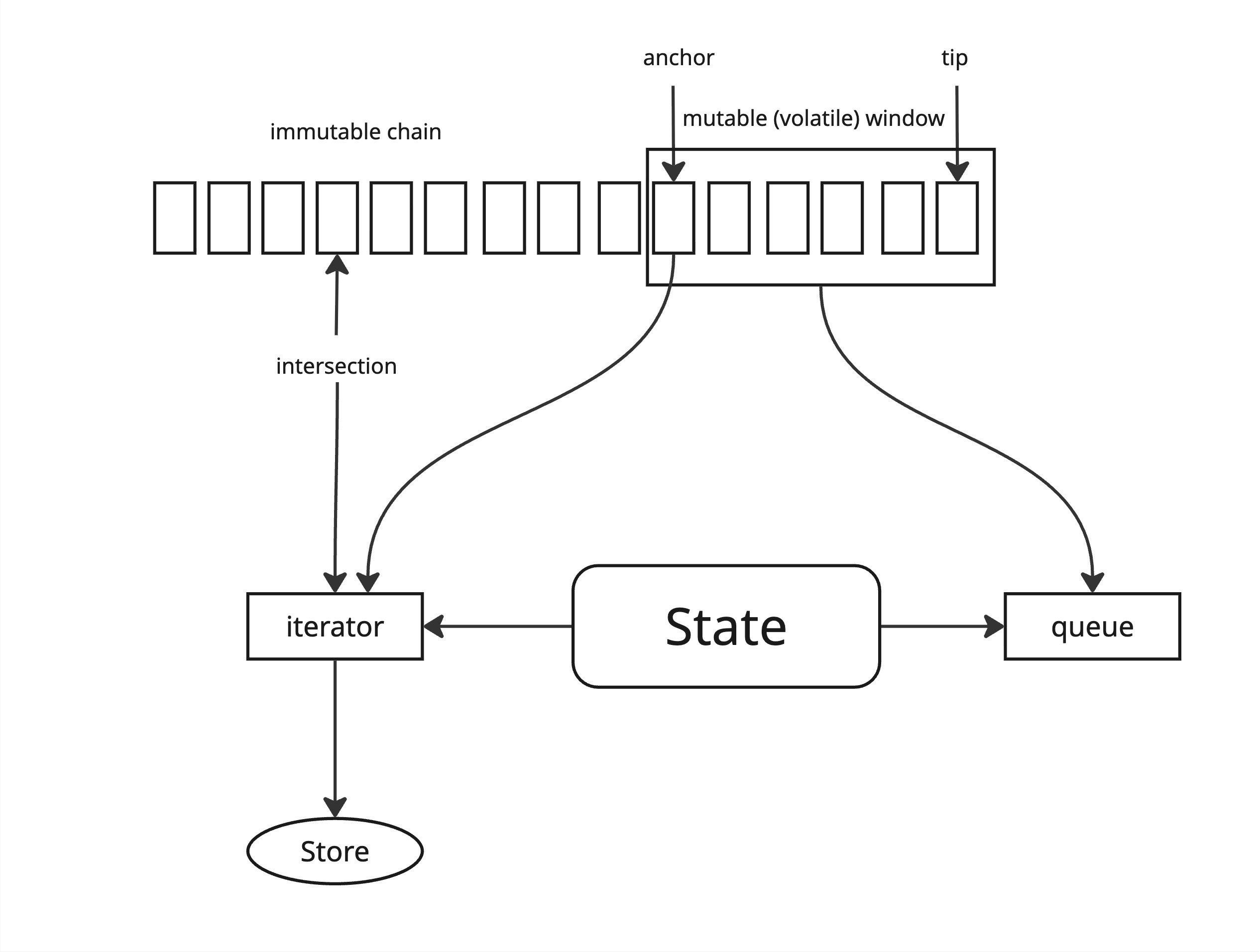
- The data generation for the simulation is now working with more complex data:
- I removed the previous hardcoded data files.
- I surfaced some data generation parameters as top-level arguments to be able to run different profiles (chain depth, rollback ratio etc...) => I'll create the PR for this tomorrow => Next step: I want to display some form of coverage data around the generation and the results: final chain length, number of forks sent downstream, etc...
- Not a lot of work done today:
- With more diverse generated data validation errors can occur -> this used to terminate the execution in
validation_errors_stage. I changed that to just log errors so that the simulation can proceed. - The next issue comes from the simulation oracle. We used to extract from the history of received messages the latest chain tip and compare it to the sample chain that was store in a file and used as the starting point for generating data. => I'm now working on fixing that oracle.
- With more diverse generated data validation errors can occur -> this used to terminate the execution in
- Revisiting #426 as it is a critical issue to solve to improve resilience of Amaru in a relay role
- Took some time to understand the code in the
chain_forwardmodule(s) as it's not been visited for a while. We felt some more details about the interactions between the various components were missing to quickly catch up, but in the end things fell in place. There's a nice diagram but it feels a bit static and some more comments in the code could help - The source of the issue is pretty clear:
- When a downstream node requests an intersection, we find the most recent intersection point from the list they send us and then...
- ... we load all headers from this point up to our current tip into a list of
ClientOp... - ... which is then fed to the client's actor delegate
- The "right thing" to do would rather be to maintain a pointer or cursor for each client which points at our latest known intersection, and send them the next header from our best chain until they reach the tip
- However, we realise we actually don't store our best chain in such a way as to be easily followed from parent to child:
- we store the
best_chainheader - we store parent -> child relationship for each header
- but a header can have multiple children in case of forks/rollbacks
- we store the
- It seems the simplest solution would be to store an additional "table" with slots as key and header hash as value representing the one and only best chain.
- when we roll forward our best chain, we update this table adding an entry for the new tip
- when we roll back, we delete the entries up to the rollback point and add them back
- indexing by slots makes it very efficient to do range queries or lookups (e.g. to find intersection)
- Before doing that, we experiment with a tactical solution: Loading the hashes of the headers instead of the whole header and read the headers when sending them back to peer
- Trying to test how this tactical solution impacts memory consumption, we try to run the new code on an existing preview DB but run into a schema layout upgrade so we need to resync fully first
- The
store_headerandstore_blockstage have been merged into thereceive_headerandfetch_blockstages respectively.
- Reusing the data generation from the HeadersTree tests for the simulation is not trivial because we use different representations for headers.
- While thinking about this I realized that the regular
Headerdata type recomputes its hash (serialize the header + computes the hash) every time we call thehash()method which is inefficient.- So I'm proposing this PR: https://github.com/pragma-org/amaru/pull/501 which allows us to:
- Compute the header hash only once (and set it on a new data type
BlockHeader). - Recalculate the hash after modifying parts of the header (and possibly make the 2 disconnected).
- Remove
FakeHeaderandTestHeaderthat were used for tests which simplifies our setup. => Some tests are not yet passing, I need to fix them before opening the PR for review.
- Compute the header hash only once (and set it on a new data type
- So I'm proposing this PR: https://github.com/pragma-org/amaru/pull/501 which allows us to:
- The
select_chainstage is now pushed to the end of the graph (right beforeforward_header). - In order to do so, a
track_peersstage, right after thereceive_headerstage has been created to register when our node has caught up to a given peer. - The next steps will be to:
- Squash the
store_headerandstore_blockstages into other stages since they just encapsulate a simple external effect. - Put the
stage.pullstage into pure stage in order to deal with peer selection and in particular peer disconnections (this crashes the node at the moment).
- Squash the
- I fixed a deadlock when running the simulation with more than 4 downstream peers
- The queue that is used to collect downstream messages was filling up too quickly.
- It is now sized proportionally to the number of downstream peers
- I started integrating the data generation done for testing the
HeadersTreeto the simulation, instead of using the current hard-coded chain:- One drawback is that we will have to bypass the code testing the validity of a header since the headers produced by the generation code are fake headers (not properly signed)
- On the other hand this allows us to generate more diverse chains sent by peers.
-
Geoff noticed that the consensus spans were not grouped inside the same traces on Jaeger anymore.
-
The main reason is that:
- Stages are asynchronous pieces of execution.
- For that reason the current parent span (created when a chain sync event is received) is transferred from stage to stage. as a field on the event that activates each stage.
- When a stage starts processing a given event, the stage main function needs to have its span as a child of the event span.
- The stage function span is created with the
#[instrument]attribute and then reparented withspan.set_parent. - Unfortunately this call cannot not succeed.
-
There used to be a work-around with previous versions of the OpenTelemetry crate but I couldn't find a way to use that work-around with the most recent version.
-
The fix consists in manually creating a span with the
span!macro and provide the span parent as a field:span!(parent: msg.span()). -
The PR comes with a way to test the structure of spans produced by a given piece of code, thanks to the new
assert_span_treesfunction in theamaru-tracing-jsoncrate.
- The PR moving the effects used in
validate_headertopure-stageis now ready for review: https://github.com/pragma-org/amaru/pull/489.- During the implementation I realized that a header validation rule is not yet implemented (the opcert sequence check) and discussed this with Arnaud I now better understand what will need to be done when we decide to implement it but will need a more detailed specification to do so.
- Before we start running the simulation I need to change the stages graph so that
select_chainis done at the end. => I started this rewiring and should be finished tomorrow.
- After some debugging and navigation around the pure-stage simulation code I eventually understood that validation errors are triggering the deadlock. We discussed this with Roland and that makes sense if the error stages never consume their messages. Roland is going to have a look at that.
- In the meantime I also fixed the issues that were generating the validation errors.
- One good thing is that I can now also implement some tests on the faulty stage (
select_chainin that case) to show that the fixes are working. => The next steps will be to:- Use an effect for the
validate_headerstage when the ledger state is read. - Prepare a PR for review (unfortunately this is going to be a large one again but hopefully I can simplify some of the code).
- Use an effect for the