BlazeRules evaluates YAML rules over high-volume event batches. Use it from Python, embed it in C++, or run the local agent to read logs and event streams from HTTP, stdin, file tails, Kafka, Arrow, Avro, Protobuf, S3, or local files.
Repository: github.com/purijs/blazerules · Documentation: blazerules.readme.io
License: source-available under FSL-1.1-ALv2; commercial/OEM licensing is
available for managed-service, competing SaaS, and enterprise use.
The engine is batch-first internally. Ingestion adapters collect events into microbatches, infer or bind a schema, evaluate rules, and emit compact decisions or dead-letter records.
pip install blazerulesThe Python package exposes blazerules and blazerules_io. It includes the
core rule engine, IO helpers, ONNX scoring, the local ingest agent, and the local
dashboard. numpy and pyarrow are installed as Python dependencies.
python -c "import blazerules, blazerules_io; print(blazerules.__version__, blazerules.simd_backend())"| Input | How to use it | Typical use |
|---|---|---|
| JSON / NDJSON bytes | RuleEngine.evaluate_ndjson(...) |
API payloads, application events, log lines already formatted as JSON. |
| Python lists of JSON strings | RuleEngine.evaluate_messages(...) |
Small integrations and local scripts. |
| PyArrow / Arrow batches | RuleEngine.evaluate_batch(...) |
Typed pipelines, Parquet/Arrow data, high-throughput paths. |
| Kafka | blazerules_io.KafkaConsumer or run_stream(...) |
Microbatch consume → evaluate → produce decisions. |
| HTTP logs/events | blazerules_agent --input http or instances[].input.type: http |
Apps POST NDJSON to /v1/logs. |
| stdin | blazerules_agent --input stdin |
Pipe terminal output or process logs into BlazeRules. |
| File tail | blazerules_agent --input file_tail --path app.log |
Pod logs, stdout/stderr files, node-local log files. |
| Plain text logs | wrap each line as JSON first | Unstructured terminal/stdout/stderr text. |
| Kubernetes logs | Helm chart / DaemonSet file-tail mode | Tail /var/log/containers/... and write decisions/DLQ. |
| Debezium CDC | blazerules_io.unwrap_debezium(...) |
Evaluate database change events. |
| Arrow IPC | blazerules_io.ArrowIpcDecoder |
Binary columnar frames. |
| Avro | blazerules_io.AvroDecoder |
Schema-based binary events. |
| Protobuf | blazerules_io.ProtobufDecoder |
Descriptor-backed binary events. |
| S3 / local files | read_ndjson_bytes(...), read_record_batches(...) |
Offline jobs, backtests, lookup/model/rule loading. |
All paths converge on the same batch evaluation engine. The adapters differ in how they collect and decode records; rule execution stays the same.
import blazerules
engine = blazerules.RuleEngine()
engine.load_rules("rules.yaml")
payload = b"""
{"event_id":"e1","card_token":"card_1","amount":2500.0,"device_type":"emulator","country_code":"US"}
{"event_id":"e2","card_token":"card_2","amount":50.0,"device_type":"ios","country_code":"GB"}
"""
result = engine.evaluate_ndjson(payload)
print(result.n_records, result.n_matched)
print(result.decisions)
print(result.match_counts)Rules can be loaded before a schema exists. The first evaluated batch samples rule-referenced fields and binds the inferred schema. You can still pass an explicit schema when you need strict control.
Run an HTTP ingest endpoint:
blazerules_agent \
--rules rules.yaml \
--input http \
--host 127.0.0.1 \
--port 9480 \
--batch-size 4096 \
--flush-ms 50 \
--output ndjson \
--output-path decisions.ndjson
curl -X POST http://127.0.0.1:9480/v1/logs \
--data-binary $'{"event_id":"e1","message":"payment error","amount":99.5}\n'Pipe stdin:
journalctl -u checkout -f -o json | \
blazerules_agent --rules rules.yaml --input stdin --output stdoutTail a file:
blazerules_agent \
--rules rules.yaml \
--input file_tail \
--path /var/log/containers/checkout.log \
--output ndjson \
--output-path decisions.ndjsonEach agent input batches records by batch_size or flush_ms, evaluates the
batch, and writes compact decision events. Bad records can be counted, skipped,
or written to a dead-letter NDJSON file depending on ingest settings.
BlazeRules returns per-record decisions directly in Python/C++. The agent can also write an NDJSON decision log for downstream routing:
{"ts_ms":1782150000000,"batch_row":0,"decision":"REVIEW","score":72.0,"risk_band":"HIGH","winning_rule_id":"high_risk_payment"}Dead-letter records keep malformed or type-bad input out of the hot path while preserving enough context to debug the producer. The dashboard reads decision logs, dead-letter logs, metrics, benchmark output, and rule summaries.
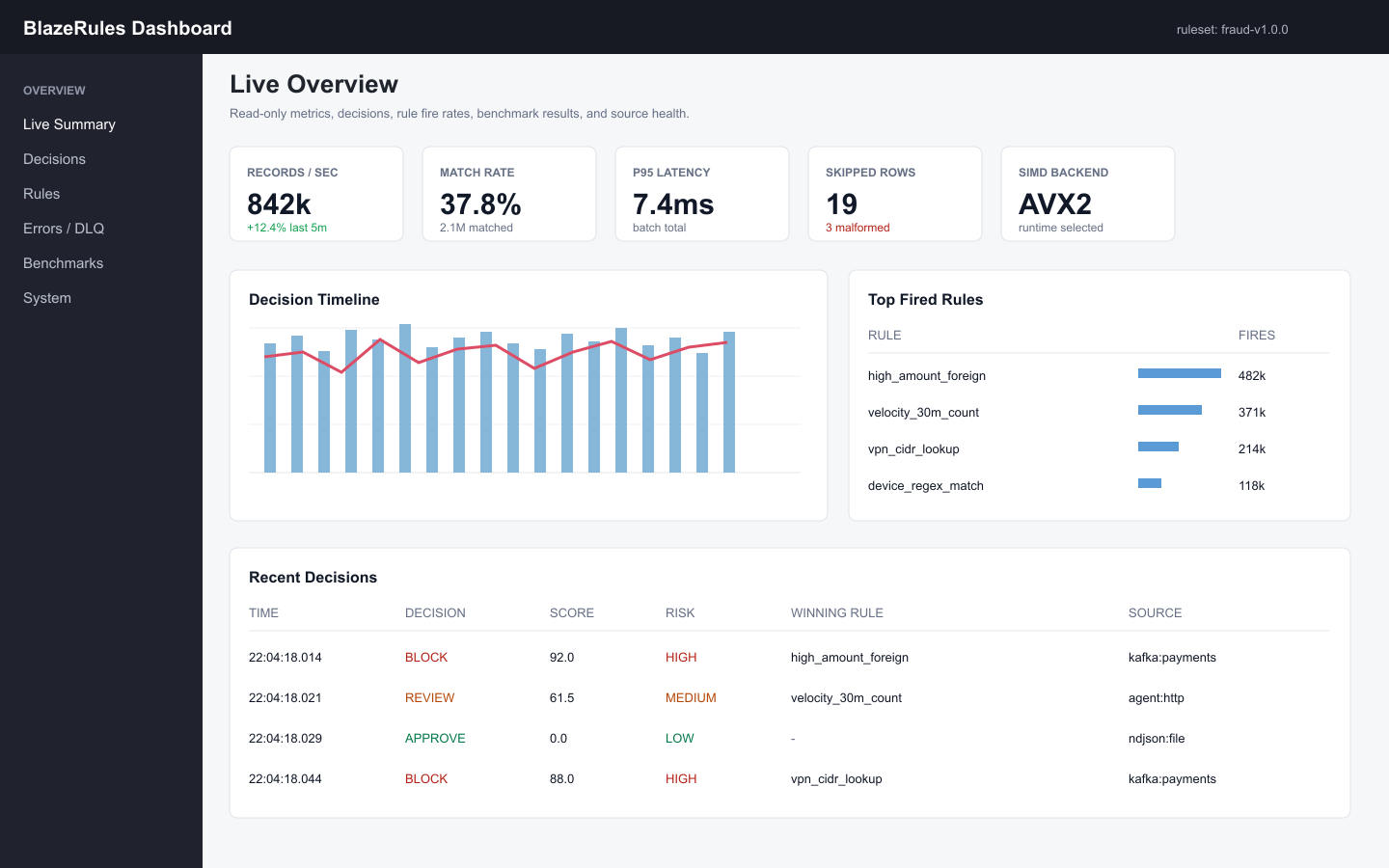
Start here:
- Quickstart
- Ingestion Overview
- HTTP Logs Recipe
- stdin Recipe
- File Tail Recipe
- Plain Text Logs Recipe
- Kubernetes Logs Recipe
- DLQ Recipe
- Python API
- API and CLI Values Reference
- Production YAML Guide
- Licensing
- Build, C++ And Platforms
Most users start with pip install blazerules. Build from source when you need
to change native flags, embed the C++ library directly, or produce your own
platform image.
cmake --preset linux-x86_64-release-dispatch
cmake --build --preset linux-x86_64-release-dispatch -jBuild details, CMake options, C++ embedding, and architecture-specific notes are kept together in the documentation instead of spread through the getting-started path.
Use Arrow when upstream data is already typed or when JSON parsing is not what you want to measure.
import pyarrow as pa
import blazerules
batch = pa.record_batch({
"card_token": pa.array(["card_1", "card_2"]),
"amount": pa.array([2500.0, 50.0], type=pa.float32()),
"device_type": pa.array(["emulator", "ios"]),
"country_code": pa.array(["US", "GB"]),
"account_age_days": pa.array([2, 400], type=pa.int32()),
"hour_of_day": pa.array([1.5, 12.0], type=pa.float32()),
})
engine = blazerules.RuleEngine()
engine.load_rules("rules.yaml")
result = engine.evaluate_batch(batch)Arrow batches may contain extra columns or different physical column order.
BlazeRules projects rule-referenced columns by name. Nested Arrow struct
fields use the same dotted names as JSON.
Minimal shape:
schema_version: "2.1"
fields:
card_token: {type: entity_key, nullable: false}
amount: {type: float32, nullable: false}
device_type:
type: categorical
values: [ios, android, web, emulator]
ruleset:
name: Fraud Rules
version: "1.0.0"
rules:
- id: high_amount_emulator
action: block
severity: HIGH
weight: 40
conditions:
and:
- field: amount
op: gt
value: 2000
- field: device_type
op: eq
value: emulatorTop-level fields are optional hints, not a mandatory user schema. They are
useful for entity keys, timestamps, nullability, and closed categorical values.
Without hints, BlazeRules infers referenced fields from the first batch.
Logical forms:
conditions:
and:
- field: amount
op: gt
value: 1000
- or:
- field: country_code
op: in
values: [US, GB]
- not:
field: device_type
op: eq
value: iosSQL expression form:
conditions:
sql: "amount > 1000 AND any_match(items, x -> x.price > 100)"See rules.yaml for a compact file covering every operator family supported
by the parser, plus a top-level instances section for the local agent.
Numeric:
gt lt gte lte eq neq
between_including between_excluding
gt_field lt_field gte_field lte_field eq_field neq_field
Categorical/entity:
eq neq in not_in
Null and empty:
is_null is_not_null is_empty is_not_empty
Strings and regex:
contains starts_with ends_with ci_eq
length_gt length_lt length_eq
regex not_regex
Arrays and flags:
contains_any contains_all intersects not_intersects
array_len_gt array_len_lt array_len_eq
flags_any flags_all flags_none
array_any
Network, temporal, geo:
ip_in_subnet ip_not_in_subnet
before after within_last day_of_week_in time_of_day_between
distance_gt distance_lt
Lookups, windows, derived values:
in_lookup not_in_lookup
window: count sum avg ratio min max
expr arithmetic: + - * /
vector_distance: cosine l2 dot
model_score
Nested JSON:
{"merchant":{"risk":{"score":91}}}Rule:
conditions:
field: merchant.risk.score
op: gt
value: 50Array-of-object same-element semantics:
conditions:
array_any:
path: items
where:
and:
- field: price
op: gt
value: 100
- field: category
op: eq
value: electronicsThis matches only when one item has both price > 100 and
category == electronics.
Rule files can reference CSV lookup sets:
lookups:
blocked_merchants:
type: string_set
path: lookups/blocked_merchants.csv
risky_bins:
type: int_set
path: lookups/risky_bins.csv
vpn_ranges:
type: ipv4_cidr_set
path: lookups/vpn_ranges.csvSupported lookup CSV columns:
| Type | Column |
|---|---|
string_set |
value |
int_set |
value |
ipv4_cidr_set |
cidr |
Relative lookup paths resolve relative to the rules file. Missing or invalid lookup files fail rule loading and do not replace an active hot-reloaded ruleset.
Use decision groups instead of Python loops over every row:
result = engine.evaluate_ndjson(payload)
approved = result.indices_for_decision("APPROVE")
needs_review = result.indices_for_not_decision("APPROVE")
groups = result.grouped_decision_indices()Useful result fields:
n_records
n_matched
decisions
decision_codes
scores
risk_bands
winning_rule_ids
match_counts
matched_indices
timing_ms
messages_processed
messages_skipped
error_counts
error_samples
Use OutputDetail.DECISIONS for routing and OutputDetail.BITMASKS only when
downstream code needs per-rule bitmasks.
Window rules read prior batch history, inject derived window columns, evaluate the current batch, then write the current batch for future batches. This means batch N sees state committed by earlier batches. Same-batch repeated entity rows do not see earlier rows from that same batch by default.
Supported window functions:
count sum avg ratio min max
engine.load_rules("rules.yaml")
engine.enable_hot_reload("rules.yaml", poll_interval_seconds=5)
status = engine.hot_reload_status()Reload compiles and validates the new YAML/lookups off the hot path, then swaps atomically only on success. Failed reloads keep the previous ruleset active. Batches keep the ruleset observed at batch start.
Rules and schema activation are strict. Bad YAML, unknown fields, duplicate rule IDs, invalid regex, bad lookup files, and type/operator mismatches fail before activation.
Ingest defaults are tolerant:
config.ingest_error_mode = blazerules.IngestErrorMode.SKIP_AND_COUNT
config.type_mismatch_mode = blazerules.TypeMismatchMode.NULL_ON_TYPE_ERROROther modes:
SKIP_TO_DEAD_LETTER
HARD_FAIL
COERCE
HARD_FAIL_TYPE
import blazerules
print(blazerules.simd_backend())
print(blazerules.cpu_features_summary())
cfg = blazerules.EngineConfig()
cfg.simd_backend_override = "auto"
cfg.enable_avx512 = FalseAVX-512 is disabled for auto-selection unless explicitly enabled because some server CPUs reduce frequency under wide vectors. Measure before enabling.
The full wheel and default source build include blazerules_io. If you maintain
a custom lean build, keep -DBLAZERULES_IO=ON and enable the matching decoder
flags:
BLAZERULES_IO_AVRO=ON
BLAZERULES_IO_PROTOBUF=ON
The IO module supports:
- Kafka source/sink through librdkafka.
- Debezium CDC unwrap.
- Arrow IPC frames.
- Avro binary records.
- Protobuf binary records with descriptor sets.
- Local and exact-object
s3://file reads.
Binary decoders produce Arrow RecordBatch objects and call evaluate_batch;
they do not need to convert through JSON.
Rules, lookup CSVs, ONNX models, and files can be loaded from exact-object
s3://bucket/key URIs through the AWS CLI cache path.
import blazerules
blazerules.set_aws_profile("personal")
blazerules.set_aws_region("us-east-1")
blazerules.set_aws_endpoint_url("http://127.0.0.1:9000")
engine = blazerules.RuleEngine()
engine.load_rules("s3://bucket/rules/fraud.yaml")Equivalent environment variables:
export BLAZERULES_AWS_PROFILE=personal
export BLAZERULES_AWS_REGION=us-east-1
export BLAZERULES_AWS_ENDPOINT_URL=http://127.0.0.1:9000Dashboard:
cmake --build cmake-build-release --target blazerules_dashboard -j
./cmake-build-release/blazerules_dashboard --host 127.0.0.1 --port 9470 --rules rules.yamlAgent:
cmake --build cmake-build-release --target blazerules_agent -jThe dashboard is read-only and unauthenticated. Bind to localhost unless you add your own network controls.
- Use Release builds.
- Batch records; do not call the engine per record.
- Prefer Arrow when upstream data is already typed.
- Use
evaluate_ndjson(bytes_blob)for JSON streams. - Use
evaluate_ndjson_padded(...)orevaluate_ndjson_file(...)when input is already simdjson-padded or memory-mapped. - Keep streaming batches sized for latency, commonly 2K-64K rows.
- Use larger batches for throughput benchmarks.
- Use
OutputDetail.DECISIONSunless per-rule masks are required. - Keep partition/entity affinity for window-heavy streaming workloads.
- Avoid huge unused JSON fields when chasing JSON throughput; skipped bytes are still bytes the parser must scan.
- Library version:
blazerules.__version__/blazerules.BLAZERULES_VERSION. - YAML compatibility:
blazerules.RULE_YAML_COMPATIBILITY. - Public API follows semantic versioning.
- Rule operator behavior is stable within a compatible YAML major version.
BlazeRules is source-available under the Functional Source License 1.1,
Apache 2.0 Future License (FSL-1.1-ALv2).
You may use, modify, and redistribute BlazeRules for permitted purposes under the FSL. Offering BlazeRules or substantially similar functionality as a commercial hosted service, managed service, SaaS, API, platform, or competing product requires a commercial license.
The intended product split is:
- public/source-available data plane: local engine, SDKs, local agent, local dashboard, examples, and integrations;
- commercial/SaaS control plane: hosted rule editor, approval workflows, versioning, fleet management, audit logs, registry, enterprise connectors, certified builds, support, and BYOC/BYOL management.
For commercial, OEM, managed-service, enterprise, or BYOC/BYOL licensing,
contact licensing@blazerules.dev.
See LICENSE, COMMERCIAL.md, TRADEMARKS.md, and THIRD_PARTY_NOTICES.md.