

![]()
A bulletproof way to generate verifiably cited text from language models.
![Side-by-side: baseline HF generation happily emits [7] and [8] when only 6 sources are in scope; citeformer's grammar mask makes [7]/[8] token-impossible to sample](https://raw.githubusercontent.com/random-walks/citeformer/main/benchmarks/findings/figures/cover-annotated.png)
Language models hallucinate citations. Ask GPT-4, Claude, or an open-source model to cite "source [7]" when you only gave it six sources and a solid chunk of the time it will invent [7], [8], sometimes [42]. citeformer makes that physically impossible. Before the model picks its next token, we compile a tiny grammar that only admits citation markers pointing at sources you actually supplied, and we hand that grammar to the decoder. Fabricated citations don't get generated less often — they cannot be generated at all. Bibliographies are rendered deterministically by the library in six academic styles (APA, MLA, Chicago, IEEE, Nature, Vancouver), and every emitted claim can be NLI-verified against its cited source after the fact. Try the live demo or pip install citeformer.
If you've read the jsonformer source or thought about logit-layer structured output, skip to Backends.
- Logit-masked GBNF. The
cite-idterminal is compiled per call to"[" ("1" | "2" | ... | "N") "]"and handed to XGrammar (default) or llguidance. Out-of-scope tokens get masked to zero probability before sampling — the sampler never sees them. This is structural, not rejection-sampled. - Ten backends, two enforcement loci, one
GenerationResult. HF + vLLM + llama.cpp enforce in-process via XGrammar / llguidance / GBNF. Fireworks drops citeformer's GBNF in unchanged via its nativetype: grammarmode — the samecite-idrule that masks logits inHFBackendruns inside the Fireworks runtime. OpenAI + Mistral + Gemini + OpenRouter + Together enforce inside the provider runtime via strict structured outputs (which became real token-level constrained sampling in late 2025 — see architecture.md). Anthropic is adapted from its native Citations API. All collapse to the same typed output for downstream verify / render / streaming. - The model never touches the bibliography. Six hand-written CSL formatters (~1 kLOC, no citeproc-py dependency — see ADR-004) render references deterministically. 300 locked snapshots pin the formatter outputs.
- Verify is real, not a hit rate.
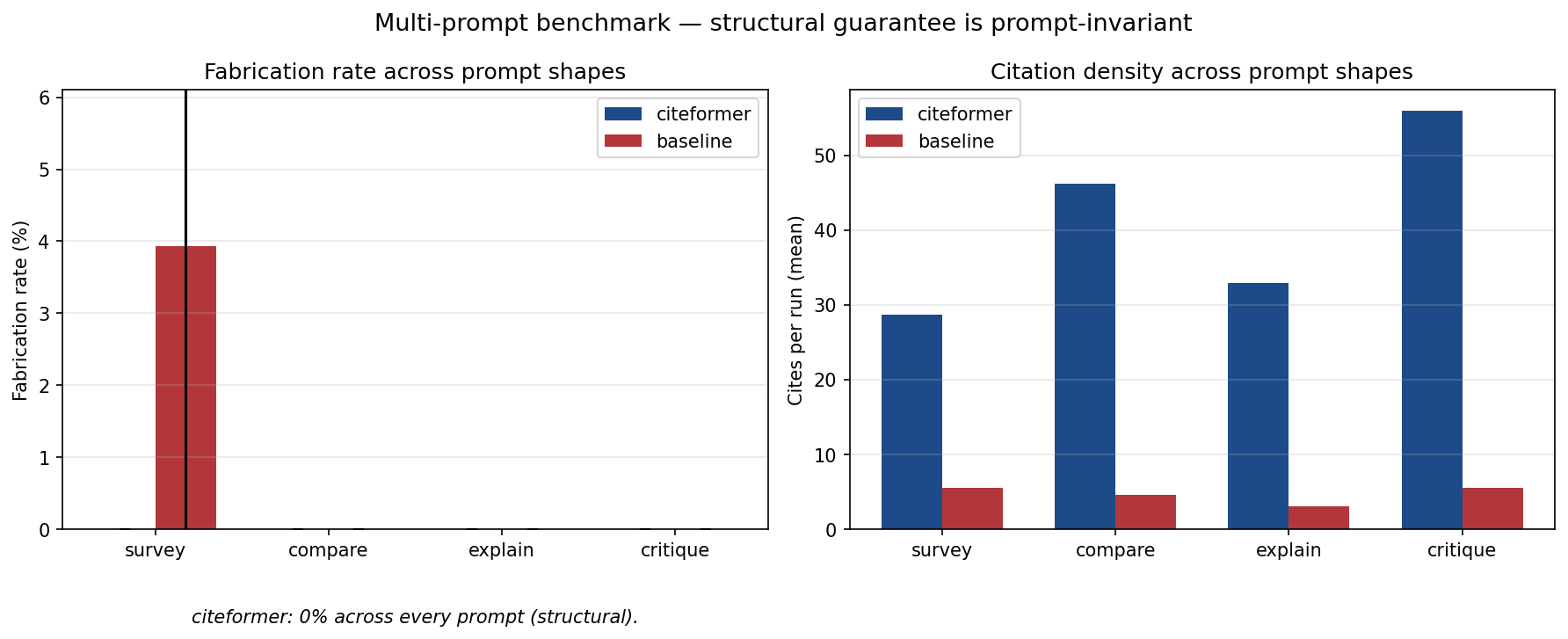
result.verify()runs DeBERTa-v3-large-MNLI over every (source content, cited sentence) pair and returns a typedVerificationReport— with a coverage check for uncited-but-entailed sentences. Threshold calibration + the honest bimodal-score finding live in benchmarks/README.md#finding-4. - 0.0 ± 0.0 fabrication across 40 runs. 4 prompt shapes × 2 models × 5 seeds in
benchmarks/multiprompt_sweep.py. The stds are identically zero because there's no variance to measure — the guarantee is a contract, not a mean.
Hi, I'm Blaise — how this got built
Hi — I'm Blaise Albis-Burdige (@blaiseab). I wrote citeformer on and immediately around a trip to Ramp's NYC office. On the subway ride up I was rereading jsonformer by @1rgs — partly to sharpen my intuition for how the applied-AI folks at Ramp think about structured output, partly because jsonformer is one of those projects whose core insight ("don't prompt it; constrain the token distribution") has aged extraordinarily well. By the time I got off the train I was convinced the same move applied to RAG citations, which are — empirically, in 2026 benchmarks — wrong 14–95% of the time depending on what you measure. jsonformer has been dormant since early 2024; no successor had applied the insight to citation markers. This is that successor. The heavy lifting lives in dependencies I didn't write (XGrammar, transformers, vLLM, DeBERTa, httpx, pypdf, GROBID, readability) — citeformer's contribution is the composition plus the six §10 contracts that keep the seams honest as the surface grows. Paper-shaped write-up: PREPRINT.md.
Status: v0.1.0 on PyPI. Seven backends (HF + vLLM + llama.cpp local, OpenAI + Anthropic + Gemini + Mistral API), six hand-written CSL styles, deterministic bibliography rendering, and claim-level NLI verification. Follow CHANGELOG.md for the full change log.
LLM-generated citations are wrong 14–95% of the time depending on the benchmark. RAG systems still fabricate 3–13% of cited URLs. NeurIPS 2025 accepted ~50 papers with AI-generated fake references. Prompting doesn't fix it; post-hoc verification doesn't fix it. The only real fix is structural — make the invalid output token-impossible before the model reaches the decision point.
citeformer delivers that in three independent ways:
- Citation markers can't be fabricated.
[N]whereN > len(sources)is token-impossible to sample on local backends, and (since strict structured outputs went GA across providers in late 2025) token-impossible inside the provider's runtime on the API backends too. Proven across 40 multi-prompt runs — 0% fabrication on every prompt × model × seed triple. - Bibliographies are rendered by the library, not the model. Six styles, deterministic output, 300 locked snapshots.
- Every citation is claim-verifiable.
result.verify()runs NLI entailment per cite and returns a structuredVerificationReport— not just a hit rate.
# Core only — no model backend, just the types + rendering + metadata adapters.
pip install citeformer
# Local backends — masking runs in-process via XGrammar / llguidance / GBNF.
pip install 'citeformer[hf]' # HuggingFace transformers + XGrammar
pip install 'citeformer[llamacpp]' # llama.cpp native GBNF
pip install 'citeformer[vllm]' # vLLM guided-decoding (Linux/CUDA only)
# API backends — masking runs inside the provider's runtime (strict structured
# outputs is real token-level constrained sampling on every modern provider).
pip install 'citeformer[openai]' # Structured Outputs strict=true
pip install 'citeformer[anthropic]' # Citations API adapter (with prompt-caching on)
pip install 'citeformer[openrouter]' # Multi-provider routing (anthropic/.., openai/.., google/..)
pip install 'citeformer[fireworks]' # Native GBNF — drops citeformer's grammar in unchanged
pip install 'citeformer[together]' # Strict json_schema on open-weight upstreams
pip install 'citeformer[gemini]' # response_schema constrained generation
pip install 'citeformer[mistral]' # Strict JSON schema
# NLI verification (DeBERTa-v3-MNLI).
pip install 'citeformer[verify]'
# Cross-platform kitchen sink (HF + llama.cpp + verify; excludes vLLM).
pip install 'citeformer[all]'Python 3.11+ (tested through 3.14). Apache-2.0.
Try it without installing. The HF Space demo runs the adversarial "100% → 0% fabrication" swing on CPU in your browser. The literature-review notebook walks end-to-end from arXiv fetch → grammar-constrained generation → NLI verification → APA-7 bibliography on a laptop-friendly 500 MB model.
from citeformer import Citeformer, Policy, Source
from citeformer.backends.hf import HFBackend
sources = [
Source.from_doi("10.1038/s41586-023-06221-2"),
Source.from_arxiv("2305.14627"),
Source(
metadata={
"id": "poe-raven",
"type": "book",
"title": "The Raven",
"author": [{"family": "Poe", "given": "Edgar Allan"}],
"issued": {"date-parts": [[1845]]},
},
content="Once upon a midnight dreary...",
),
]
cf = Citeformer(
backend=HFBackend(model="microsoft/Phi-3.5-mini-instruct"),
style="apa-7",
citation_policy=Policy.REQUIRED,
)
result = cf.generate(prompt="Summarize the three works.", sources=sources)
print(result.text) # "Poe's The Raven opens... [3] BERT introduced... [2]"
for ref in result.references:
print(ref.rendered) # APA-7, rendered by the formatter — not the LLM
report = result.verify() # NLI entailment per citation
print(f"{report.support_rate:.0%} of cites entailed by their source")result.text cannot contain [4]. Not "unlikely to"; cannot, by grammar construction. Try more backends, styles, or the API tier with from citeformer.backends.openai import OpenAIBackend / anthropic import AnthropicBackend.
Ten backends, two enforcement loci ("where the masking runs"), one Backend ABC:
| Backend | Extra | Enforcement | Where it lives | Notes |
|---|---|---|---|---|
HFBackend |
hf |
In-process (XGrammar) | citeformer.backends.hf |
Flagship. Grammar-level token masking. |
LlamaCppBackend |
llamacpp |
In-process (GBNF) | citeformer.backends.llamacpp |
Native GBNF via llama-cpp-python. CPU + Metal + CUDA. |
VLLMBackend |
vllm |
In-process (XGrammar/llguidance) | citeformer.backends.vllm |
vLLM guided decoding. Linux/CUDA only. |
FireworksBackend |
fireworks |
Provider-runtime (native GBNF) | citeformer.backends.fireworks |
Drops citeformer's cite-id grammar in unchanged via Fireworks's response_format={"type":"grammar"} mode. The cleanest "true logit-tier on a hosted API" backend. |
OpenAIBackend |
openai |
Provider-runtime (strict JSON) | citeformer.backends.openai |
OpenAI Structured Outputs — live verified. |
AnthropicBackend |
anthropic |
Provider-native (Citations API) | citeformer.backends.anthropic |
Live verified. Prompt-caching on by default; real messages.stream() streaming; cited_text + source_span preserved on every Citation. |
OpenRouterBackend |
openrouter |
Provider-runtime (per-upstream) | citeformer.backends.openrouter |
Multi-provider routing on the OpenAI wire format. provider.require_parameters: true keeps strict mode end-to-end. Reports per-call cost in OR credits. |
TogetherBackend |
together |
Provider-runtime (strict json_schema) |
citeformer.backends.together |
Strict structured outputs on Together's open-weight upstreams (Llama / Qwen / DeepSeek). |
GeminiBackend |
gemini |
Provider-runtime (response_schema) |
citeformer.backends.gemini |
Gemini's OpenAPI-subset structured output. |
MistralBackend |
mistral |
Provider-runtime (strict JSON) | citeformer.backends.mistral |
Mistral's response_format strict JSON schema. |
MockBackend |
(core) | Scripted | citeformer.backends.mock |
For tests. Honors policies + marker styles. |
All produce the same GenerationResult, so verify / render / streaming work identically across backends. OpenAI + Anthropic are live-verified against production endpoints in tests/integration/test_api_backends_live.py; Gemini + Mistral ship with fake-client coverage and the same schema contract. Full per-provider discussion: architecture.md.
Both API backends are live-tested against production endpoints — see tests/integration/test_api_backends_live.py.
from citeformer import Citeformer, Policy, Source
from citeformer.backends.openai import OpenAIBackend # pip install citeformer[openai]
# from citeformer.backends.anthropic import AnthropicBackend # pip install citeformer[anthropic]
sources = [Source(metadata={"id": "poe", "type": "book", "title": "The Raven",
"author": [{"family": "Poe"}],
"issued": {"date-parts": [[1845]]}},
content="Once upon a midnight dreary...")]
# OpenAI uses strict JSON-schema mode (gpt-4o-2024-08-06+ only).
# Reads OPENAI_API_KEY from env; pass `client=...` or `api_key=...` to override.
cf = Citeformer(backend=OpenAIBackend(model="gpt-4o-mini"),
style="apa-7", citation_policy=Policy.REQUIRED)
result = cf.generate(prompt="Describe the opening in one sentence.", sources=sources)Honest about where the masking runs: local backends mask in-process via XGrammar / llguidance / GBNF — out-of-scope citations are token-impossible to sample on your hardware. API backends (OpenAI / Mistral / OpenRouter / Gemini) hand the strict schema to the provider, which has done real token-level constrained sampling since strict structured outputs went GA in late 2025; the same guarantee, just enforced inside their runtime. Anthropic uses its own Citations API — provider-side, structurally constrained that every cite references a supplied document. All collapse to the same GenerationResult for downstream verify / render. Per-call token usage and (on OpenRouter) per-call USD cost are exposed on result.usage.
Policy controls where citations are grammatically required:
| Policy | Shape of valid output | When to use |
|---|---|---|
REQUIRED |
Every sentence ends content cite-group sent-end. Cite or can't close. |
Literature reviews, survey papers, anything where every claim needs provenance. |
QUOTES_ONLY |
Only "..." quoted spans require a trailing cite-group. |
Mixed analytical prose — narrative is uncited, direct quotations are tracked. |
AUTO |
cite-group is allowed anywhere, never required. verify() flags uncited-but-entailed sentences post-hoc. |
Open-ended generation; NLI coverage check does the policing. |
Pass via Citeformer(citation_policy=Policy.REQUIRED) or per-call cf.generate(..., policy=Policy.AUTO). See Policy.
Build Source objects from real-world inputs:
Source.from_doi("10.1038/s41586-023-06221-2") # Crossref → CSL-JSON
Source.from_arxiv("2305.14627") # arXiv API → CSL-JSON + abstract
Source.from_pdf("paper.pdf") # pypdf → title + body text
Source.from_pdf("paper.pdf", extractor="grobid") # GROBID → author/abstract/section text
Source.from_url("https://example.com/article") # readability-lxml + OpenGraph
# Bulk-load a library; each returns list[Source].
Source.from_bibtex("refs.bib") # BibTeX parser → CSL-JSON
Source.from_zotero("zotero-export.json") # Zotero CSL JSON / Better BibTeXAll fetchers are cached on disk via diskcache (~/.cache/citeformer/metadata/, override with CITEFORMER_CACHE_DIR).
[N] collides with Markdown link syntax. Switch it out with MarkerStyle:
from citeformer import MarkerStyle
cf = Citeformer(backend=backend, marker_style=MarkerStyle.PAREN) # (1), (2) ...
cf = Citeformer(backend=backend, marker_style=MarkerStyle.CURLY) # {1}, {2} ...
cf = Citeformer(backend=backend, marker_style=MarkerStyle.CARET) # ^1, ^2 ...The structural guarantee is identical across styles — the grammar's digit enum is bounded by range(1, len(sources) + 1) regardless of which delimiters surround it. See ADR-011.
stream = cf.stream(prompt="...", sources=sources)
for chunk in stream:
print(chunk, end="", flush=True)
result = stream.finalize() # full GenerationResult with parsed citations + refsGrammar constraints apply to every chunk. HF and llama.cpp deliver true token-by-token streaming; the API backends chunk on sentence boundaries for UI progression.
All numbers below come from running scripts in benchmarks/ — reproducible on a commodity laptop with uv run python -m benchmarks.<script>.
| Finding | Result | Script |
|---|---|---|
| Adversarial | 100% → 0% fabrication swing when the prompt demands out-of-scope ids | adversarial.py |
| Sweep | 0 ± 0 fabrication across 13 runs (3 models × up to 5 seeds) | sweep.py |
| Full-text premise | Support rate lifts with full-text NLI premise — but the number is noisy, so we report that honestly | sweep.py --premise fulltext |
| NLI calibration | DeBERTa-v3-large is bimodal; threshold isn't the right knob | threshold_calibration.py |
| Multi-prompt | 0% fab across 24 runs × 4 prompt shapes — guarantee is prompt-invariant | multiprompt_sweep.py |
citeformer's value is the composition, not the parts. The heavy lifting lives in established dependencies:
| We piggyback on | For |
|---|---|
| XGrammar / llguidance | Token-level logit masking at generation time |
| transformers / vLLM / llama-cpp-python | Running local models |
| openai / anthropic SDKs | API-provider generation |
| lark | Authoring citation grammars before hand-off to the decoder |
| pydantic | Immutable output schemas with extra="forbid" |
| httpx + diskcache | Metadata fetchers (Crossref, arXiv) with caching |
| pypdf | PDF text extraction |
| readability-lxml | URL extraction |
| DeBERTa-v3-MNLI (via transformers) | NLI entailment for verify() |
| typer + rich | CLI + pretty output |
The parts citeformer owns: citation grammar shape (§10.1), CSL-JSON source contract (§10.2), output pydantic models (§10.3), marker-to-reference coupling, the six bundled style formatters (APA 7, MLA 9, Chicago author-date, IEEE, Nature, Vancouver — ADR-004), the BibTeX parser, and the orchestration loop. Everything else is a composition.
The examples/ directory contains eight runnable scripts, each a living report:
| # | File | What it shows |
|---|---|---|
| 1 | 01_quickstart_mock.py |
Shortest possible demo — no ML, no extras |
| 2 | 02_rag_with_hf_and_verify.py |
Full RAG pipeline with HF + NLI verify |
| 3 | 03_standalone_rendering.py |
All six styles on the same CSL-JSON item |
| 4 | 04_fetch_and_render.py |
DOI → Crossref → rendered reference |
| 5 | 05_streaming.py |
Realtime chunk streaming via cf.stream() |
| 6 | 06_langchain_rag.py |
LangChain Document → Source → citeformer |
| 7 | 07_llamaindex_rag.py |
LlamaIndex NodeWithScore → Source |
| 8 | 08_literature_review.ipynb |
Full academic workflow notebook (arXiv → review → verify → APA-7) |
| 9 | 09_bibtex_source.py |
BibTeX + Zotero ingest → APA-7 render (no network, no model) |
A longer design + evaluation document is in PREPRINT.md. Eight sections covering motivation, related work, design, structural-guarantee evaluation (40-run sweep), NLI calibration findings (bimodal large vs under-confident base), known limitations, and roadmap.
Probably yes if:
- You're building RAG and need citations that can't hallucinate.
- You run open-weight models locally (HF / vLLM / llama.cpp) and want grammar-level guarantees.
- You call an API (OpenAI / Anthropic) and want the same
GenerationResult/Citation/Referencesurface across your providers. - You need APA / MLA / Chicago / IEEE / Nature / Vancouver bibliographies rendered deterministically.
- You care about claim-level NLI verification out of the box.
- You want to ingest from BibTeX / Zotero / DOI / arXiv / PDF / URL without glue code.
Probably no if:
- You want a full agent framework — use LangChain / LlamaIndex and compose citeformer as the generation step (examples 6 & 7 show how).
- You need a TypeScript surface today — a sibling
citeformer-tsmay come later; not here yet. - You need a citation style outside the six bundled — you can plug in
citeproc-pyyourself, or contribute aCitationFormattersubclass (see.claude/skills/add-citation-format).
- Getting started: getting-started
- Guarantees: guarantees — what "bulletproof" actually covers.
- Architecture: reference/architecture — layers + phase plan + tiered enforcement.
- Contracts: reference/contracts — the three §10 invariants.
- ADRs: docs/decisions/ — 11 short architecture-decision records documenting major design choices.
- Benchmarks: benchmarks/README.md — the five findings with reproduction commands.
See CONTRIBUTING.md. Short version: bug-fix PRs welcome and bump patch; feature PRs should open an issue first. The three §10 contracts (grammar shape, CSL metadata, output schemas) are deliberate ceremonies — read docs/reference/contracts.md before touching them.
Apache-2.0. See LICENSE.