[test] GPU dgemm and pointer chasing tests #1687
Conversation
|
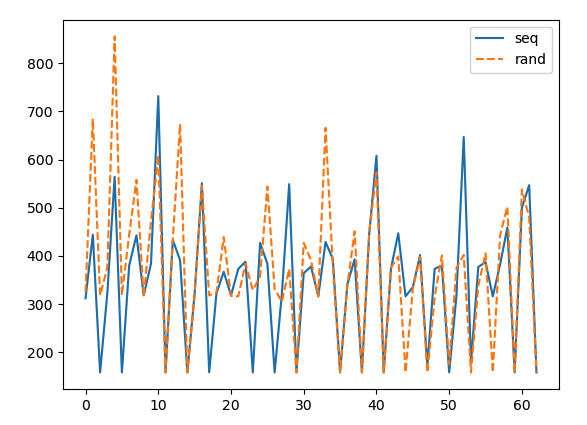
Hmm, not sure there is a need for more node jumps. All these reframe tests do not use the random init, and despite having only 64 nodes, the timings are pretty consistent. There are two types of tests in here. The first type measures the overall traversal time, and the second one measures each jump independently. For the second type, the reframe tests work out the L1 hits and misses, and compute the average timing only for these two categories. As it can be seen in the figure below (data from a P100), the timings for an L1 hit are pretty consistent at 158 cycles. If we were to capture the latency of L2 (which sits somewhere below 400 cycles), then I'd agree that we might need more nodes. But in that case, extracting the data that only belongs to an L2 hit is a challenge on its own. Though, as you say, if we make it circular we could easily tune the list to fit in any memory level. Let me experiment a bit.
|
|
The linked lists are now circular and the number of node jumps is fixed to 256. The number of nodes is now an input parameter from the user, which means that we can do something like a list with 2 nodes (resident in L1) and jump around 256 times to collect all the data we need. At the moment, there is some inconsistent behaviour with the clock latency on the P100s. This needs further testing in the other cards present in Ault. |
cscs-checks/microbenchmarks/gpu/pointer_chase/src/linked_list.hpp
Outdated
Show resolved
Hide resolved
cscs-checks/microbenchmarks/gpu/pointer_chase/src/linked_list.hpp
Outdated
Show resolved
Hide resolved
cscs-checks/microbenchmarks/gpu/pointer_chase/src/linked_list.hpp
Outdated
Show resolved
Hide resolved
cscs-checks/microbenchmarks/gpu/pointer_chase/src/linked_list.hpp
Outdated
Show resolved
Hide resolved
|
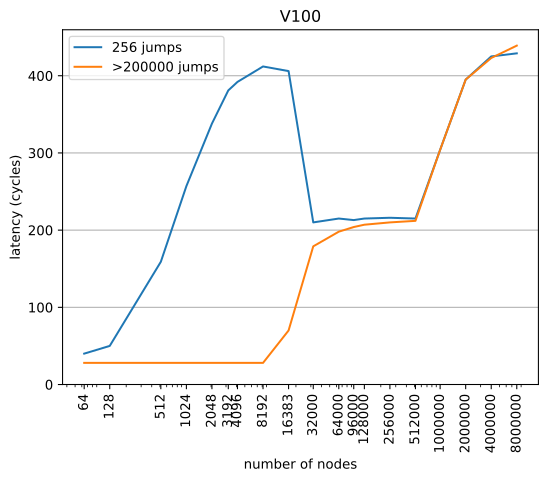
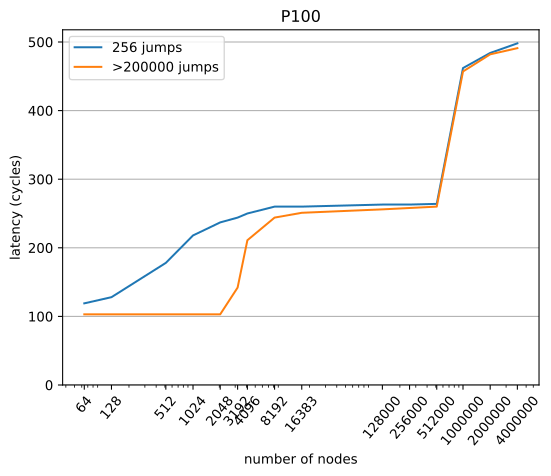
The timings don't seem converged. As I mentioned previously, setting the number of hops to a fixed number is not a viable approach and also 256 jumps are not enough by a long shot to get converged results. Here are the results on V100: and P100: List linkage was random, with no additional node-padding. On the V100, the L1 latency now is 28 cycles which agrees with other reports that I found online.
|
 jjotero
left a comment
jjotero
left a comment
There was a problem hiding this comment.
I've now stripped all the code related to measuring latencies of single node jumps and done the cleanup.
The plot below shows a parametric sweep for all the cards in ault, for a large range of list sizes, and different strides; all using 400k node jumps for the timing. The nodes are placed in sequential order in the buffer, so the --stride parameter here was used to control the filling of the cache lines.
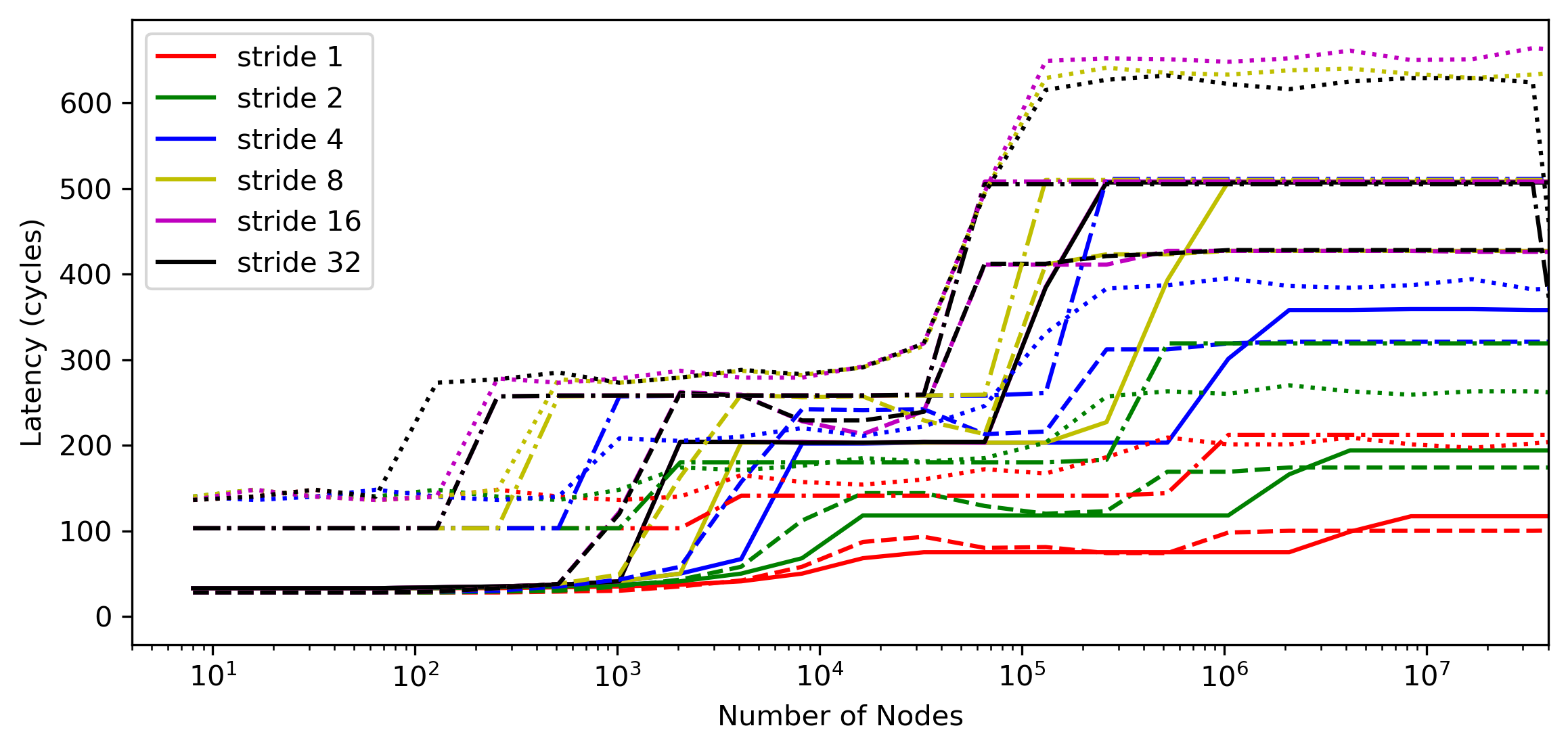
A100: solid; V100: dashed; P100: dash-dotted; Vega20: dotted
Now I just need to add the actual tests. For now, I'll fix the stride to 32 in all of them and check the L1, L2 and DRAM latencies.
cscs-checks/microbenchmarks/gpu/pointer_chase/src/linked_list.hpp
Outdated
Show resolved
Hide resolved
cscs-checks/microbenchmarks/gpu/pointer_chase/src/linked_list.hpp
Outdated
Show resolved
Hide resolved
cscs-checks/microbenchmarks/gpu/pointer_chase/src/linked_list.hpp
Outdated
Show resolved
Hide resolved
|
The tests are in now. |
 vkarak
left a comment
vkarak
left a comment
There was a problem hiding this comment.
I didn't go through the C++ code, but I've gone through your discussions and the results and I think that we are good to go. Great work of both of you! I've only some minor ReFrame test comments.
jjotero
left a comment
There was a problem hiding this comment.
PR comments addressed.
New
dgemmandpointer_chaseregression tests. Like all the other microbenchmark tests, these run with bothcudaandhip.Pointer chase checks:
clockfunction.