In this project I tried to implement Off-Policy Monte Carlo Control Weighted Importance Sampling using OpenAI Gym environment.
In this I tried to play the game BlackJack. In a game of Blackjack,
Objective: Have your card sum be greater than the dealers without exceeding 21.
All face cards are counted as 10, and the ace can count either as 1 or as 11. For more information about the Importance Sampling and BlackJack look into Jupyter Notebook.
Importance Sampling
Importance sampling plays a key role in sampling inferencing and reinforcement learning RL. In RL, importance sampling estimates the value functions for a policy π with samples collected previously from an older policy π’. In simple term, calculating the total rewards of taking an action is very expensive. However, if the new action is relatively close to the old one, importance sampling allows us to calculate the new rewards based on the old calculation.
In specific, with the Monte Carlo method in RL, whenever we update the policy θ, we need to collect a completely new trajectory to calculate the expected rewards.
A trajectory can be hundreds in steps and it is awfully inefficient for one single update. With importance sampling, we just reuse the old samples to recalculate the total rewards. However, when the current policy diverges from the old policy too much, the accuracy decreases. Therefore, we do need to resync both policies regularly.
Let’s look at the algorithm in more detail. We generate episodes using behavioral policy action which is an ε-greedy policy which means that with probability ε, it chooses an action uniform randomly and with probability 1-ε, it chooses the greedy action. This ensures the exploration of previously unexplored state-action values. But, how are we using episodes generated from behavior policy to update our Q-values which are supposed to follow the greedy target policy? This is where the idea of importance sampling comes in.
In off-policy methods, these two functions are separated. The policy used to generate behavior, called the behavior policy, may, in fact, be unrelated to the policy that is evaluated and improved, called the target policy. Although in principle, the behavior policy can be unrelated to the target policy, but in practice, it is kept quite representative of the target policy.
The relative probability of the trajectory under the target and behavior policies is:

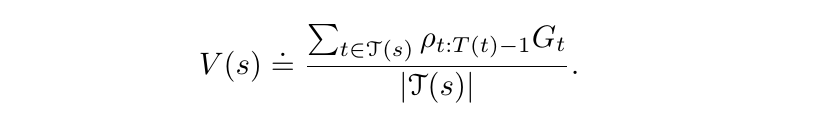
τ(s) in the equation below denotes the set of all time steps in which state s is visited.
Hence, the above equation is a simple average of all the returns weighted by the importance sampling ratios. Note that the above average is unbiased, i.e. its expectation is Vπ(s). But the variance of this estimator is in general unbounded because the variance of the ratios can be unbounded. Because of this issue of unbounded variance, generally, another estimator called weighted importance sampling, which uses a weighted average, is strongly preferred over ordinary importance sampling.
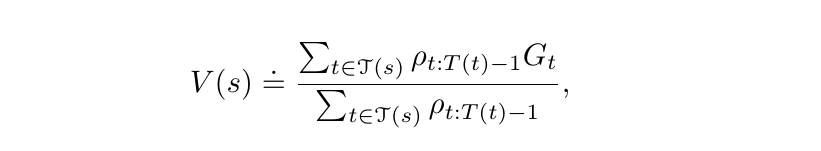
Although this estimator is biased (its expectation is Vb(s)), but if we assume bounded returns, then the variance of the weighted importance-sampling estimator converges to zero. In practice, the weighted estimator usually has a dramatically lower variance than ordinary importance sampling. Also note that the behavior policy is considered very representative of the target policy and hence in practice, the bias doesn’t lead to any adverse effects.
The above equation can be rewritten in the following way where G1, G2 … and so on are a sequence of returns, all starting in the same state and where each Wi is the importance sampling ratio.
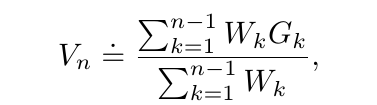
References:
- https://towardsdatascience.com/my-journey-into-reinforcement-learning-part-4-monte-carlo-methods-2b14657b7032
- https://towardsdatascience.com/solving-racetrack-in-reinforcement-learning-using-monte-carlo-control-bdee2aa4f04e
- https://towardsdatascience.com/importance-sampling-introduction-e76b2c32e744