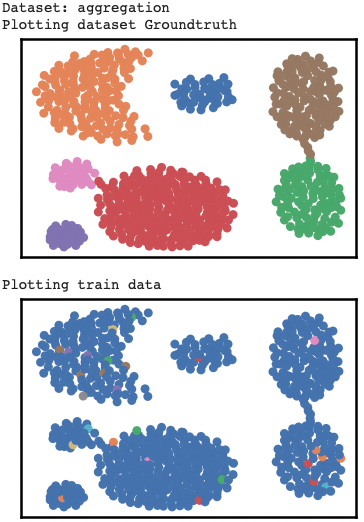
Different performance of the algorithm depending on input data type (np.ndarray or pd.DataFrame) #5
Description
I encountered a performance issue (in terms of clustering results) depending on the type of input data.
In particular, if train_data is np.ndarray, the predicted cluster labels are incorrect.
Example to reproduce the issue (starting from 2D shapes datasets.ipynb):
- Working version (using
pd.DataFrameas input data type fortrain_data):
data_path = 'datasets/denmune/shapes/'
# datasets = {"aggregation": 6, "jain": 15, "flame": 8, "compound": 13, "varydensity": 23,
# "unbalance": 8, "spiral": 6, "pathbased": 6, "mouse": 11}
datasets = {'aggregation': 6}
for dataset in datasets:
data_file = data_path + dataset + '.csv'
X_train = pd.read_csv(data_file, sep=',', header=None)
y_train = X_train.iloc[:, -1]
X_train = X_train.drop(X_train.columns[-1], axis=1)
print ("Dataset:", dataset)
dm = DenMune(train_data=X_train,
train_truth=y_train,
k_nearest=datasets[dataset],
rgn_tsne=False)
labels, validity = dm.fit_predict(show_noise=True, show_analyzer=True)
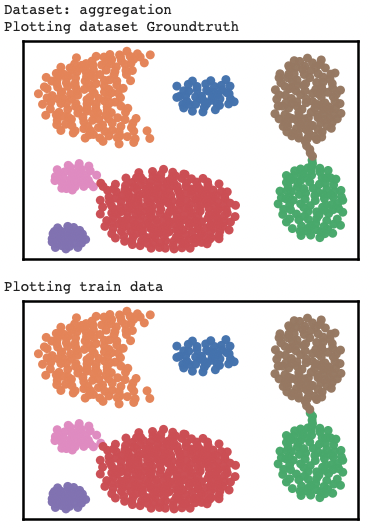
- Version with performance issue (using
np.ndarrayas input data type fortrain_data):
data_path = 'datasets/denmune/shapes/'
# datasets = {"aggregation": 6, "jain": 15, "flame": 8, "compound": 13, "varydensity": 23,
# "unbalance": 8, "spiral": 6, "pathbased": 6, "mouse": 11}
datasets = {'aggregation': 6}
for dataset in datasets:
data_file = data_path + dataset + '.csv'
X_train = pd.read_csv(data_file, sep=',', header=None)
y_train = X_train.iloc[:, -1]
X_train = X_train.drop(X_train.columns[-1], axis=1)
X_train = X_train.values
print ("Dataset:", dataset)
dm = DenMune(train_data=X_train,
train_truth=y_train,
k_nearest=datasets[dataset],
rgn_tsne=False)
labels, validity = dm.fit_predict(show_noise=True, show_analyzer=True)