The standard library functions such as malloc and new are general-purpose allocators. These functions work on multithreaded paragdigms and that makes them slow. They make calls to the Operating System kernel requesting memory, while free and delete make requests to release the memory. This means that the operating system has to switch between user-space code and kernel code every time a request for memory is made. Programs requesting repeated calls of malloc or new eventually will run slow because of the repeated context switching. IBM page describes the need for creating custom memory allocator in detail.
This repository describes two ways to manage custom memory allocator. We stay with the basics - a pool allocator and a free list allocator. For the sake of simplicity, memory alignment, padding and guard bytes were not considered as part of this project. This repository is mainly to understand the nuances of implementing a custom memory allocation built from heap.
To mitigate the disadvantages of general-purpose allocators, custom memory allocators improves performance by calling general purpose malloc only once to get a big chunk of memory, and then it manages this chunk internally to provide smaller allocations. It uses some data structures to keep track of the allocated/used and free blocks.
A pool allocator splits the big memory chunk in smaller chunks of the same size. It uses a stack to keep track of free and used blocks. When an allocation is requested, it returns the next free chunk and removes it from the stack, and when a free is done, it push the free block into the stack.
To implement the book-keeping stack, we use contiguous array and allocated the size required for the array from the same memory along with the big memory chunk requested for pool allocation.
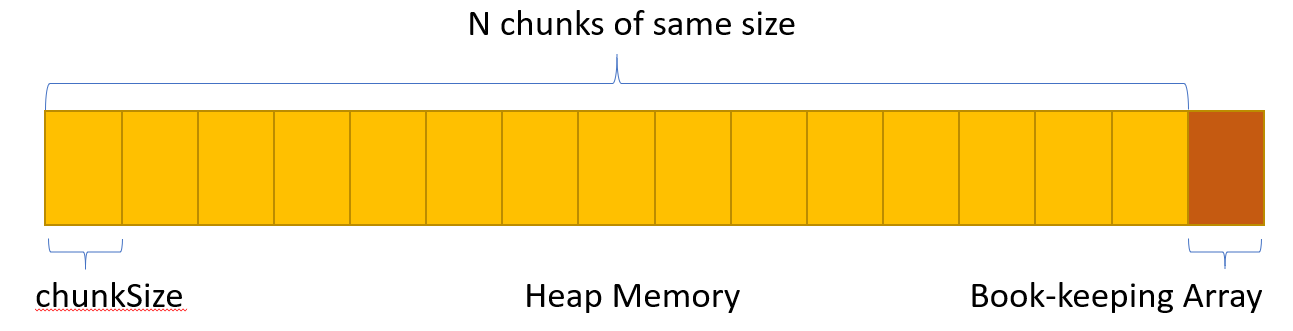
As described above, a contiguous array is kept aside for maintenance of the pools of equal chunks. Only two stack operations push() and pop() is required for book-keeping and these operations are implemented using an chunkIndex variable. Whenever an allocation is required pop() operation is imitated by reserving the address at current chunkIndex for allocation, and then incrementing the chunkIndex to point to next available address in the array. Similary, whenever a free is done push() operation is imitated by decrementing the chunk Index, and then storing the free address in the new chunk Index. This free address is now available for next requested allocation.
- The book-keeping array looks like the following before any allocation or free operation is done.
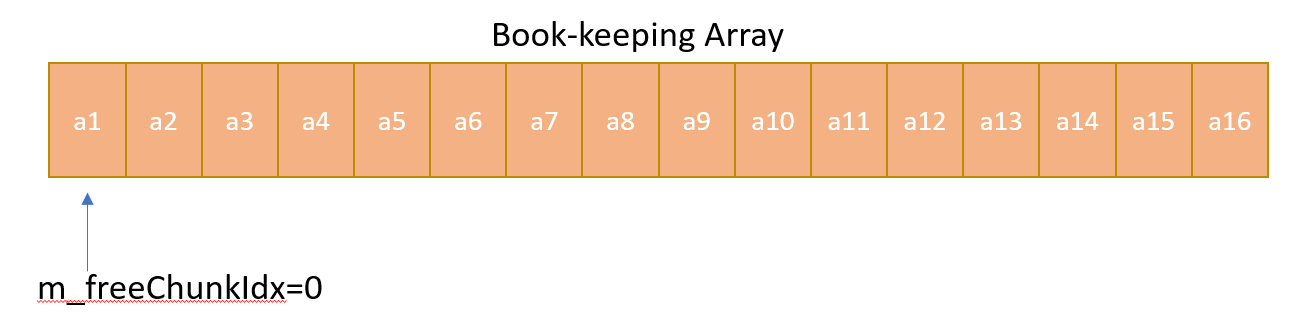
- After the first allocation is done, the book-keeping array looks like following:
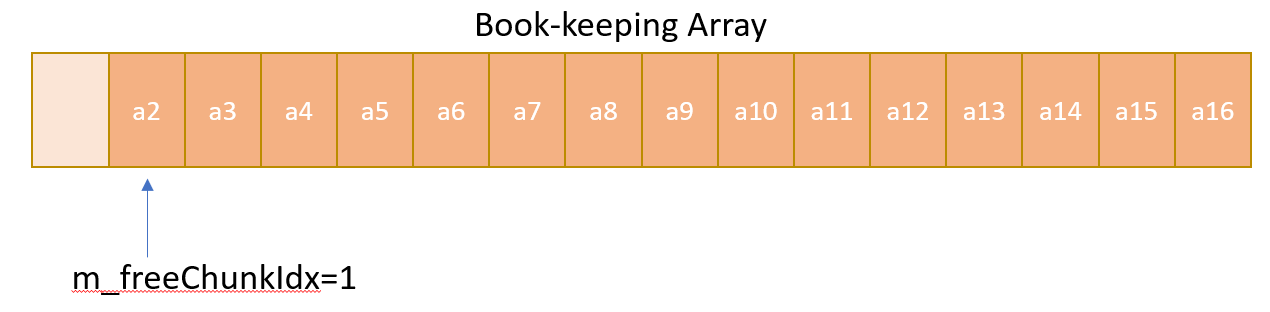
- After second allocation is done, the book-keeping array looks like the following:
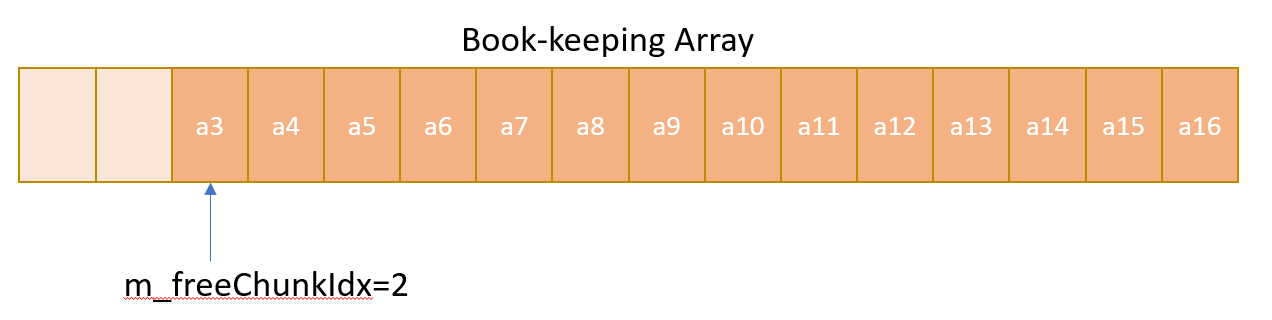
- After several allocation is done but no deallocation is done, the book-keeping array may look like following:
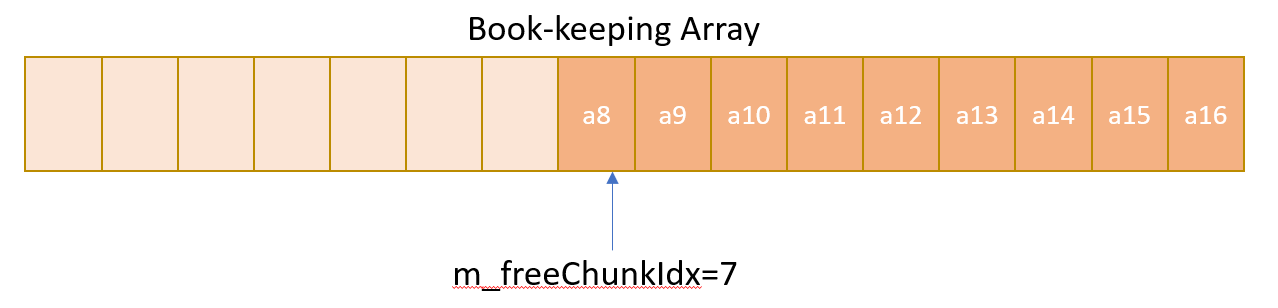
- After first deallocation is requested using address a2, the address a2 is pushed to the stack, the book-keeping array may look like the following:
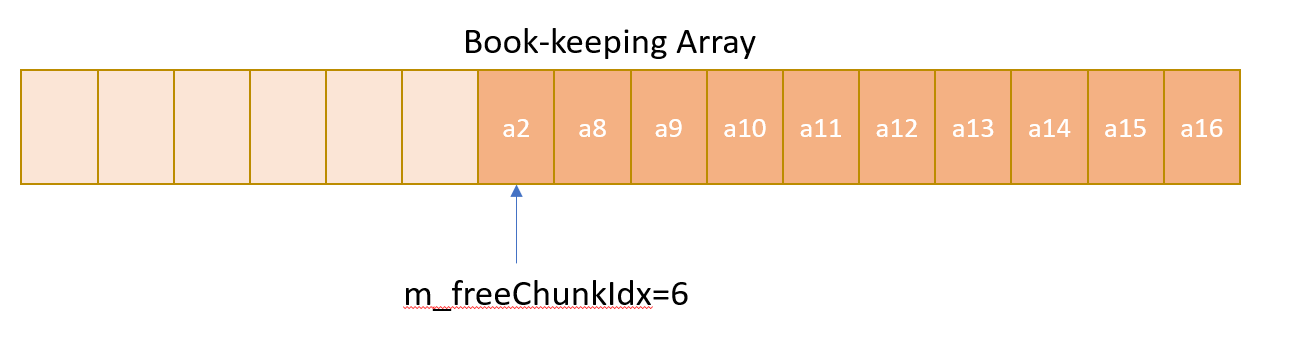
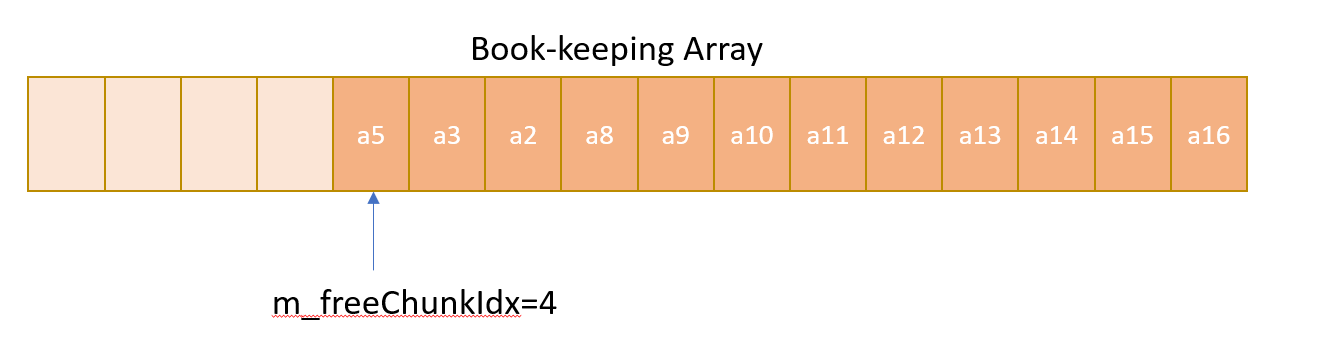
- After several deallocation is requested with mixed addresses being pushed, the book-keeping array may look like the following:
The free list allocator allows allocation of any size of chunks - an advantage over pool allocator. For this reason, it requires different data structures like a linked list or a red black tree. Hence, its performances will not be as good as the pool allocator. The data structure needed to maintain is kept as header of each block in the same memory pool.
In this implementation, a pointer is kept to keep track of the head of the linked list. When an allocation is requested, it searches in the linked list for a block where the requested size of data can fit. Before sending the data to caller, we put some information to header of the chunk about the size of chunk and put a new header on the next free available slot with available block size. We also keep track of next available free chunk through a next pointer kept in the header. During deallocation, we get back the address from the caller, we read the allocation header to know the size of the block that we are going to push back to linked list. We traverse the linked list to put the free node back between prior free node and next free node. If the free block is contigous to other free blocks , we also merge those blocks to create bigger blocks.
The source code has both find-first and find-best policy implementation.
- The memory pool of 4M looks like the following before any allocation or free operation is done.

- After the first allocation of 128K memory is done, the memory pool looks like following:

- After second allocation of 256K is done, the memory pool looks like the following:

- After first memory of 128K is deallocated, the memory pool may look like the following:

- After several allocation and deallocation are requested, the memory pool may look like the following:

In order to build and test the C++ code in the repository, please do the following:
$ make
$ bin/test
If your data requires fixed-size bytes all of same size, then pool allocator is the best choice. It is faster than general purpose allocator as well as free list allocator. It also has no fragmentation - external or internal.
Free-list allocator is useful if your data has no predefined structure. This allows you to allocate and free any fixed-size bytes but still provides faster speed than malloc. It may suffer from fragmentation.
Please contact Shomit Dutta for follow-up questions.
GNU General Public Licence