This is data management activity of New York University's Data Management and Analysis (CSCI-UA 479) class.
├── data
│ ├── nation_subset.sql
│ ├── CAERS-Quarterly--20220930-EXCEL.csv
├── src
│ ├── nation_subset_analysis.sql #Analyze nation_subset data
│ ├── create_staging_t.sql #Create table for CAERS events
│ ├── caers_event_data_import.sql #Add actual data to the tables
│ ├── staging_table_analysis.sql #Analyze caers event data for normalization
│ ├── normalization_t_ddl.sql #Create table to implement the data model
└── README.mdCreate ER Diagram based on tables in SQL file - nation_subset.sql.

nation_subset.sql contains information about countries (such as population, languages, etc.). This data is sourced from a site for another relational database (https://www.mariadbtutorial.com/), so the import statements have been adapted to postgres. The data is contained in multiple tables.
continents
- It has a one-to-many relationship with
regions. This relationship exists because of a foreign keycontinent_idinregionsthat referencescontinents(continent_id)
countries
- It has a one-to-many relationship with
regions. This relationship exists because of a foreign keyregion_idincountriesthat referencesregions(region_id) - It has a one-to-many relationship with
country_languages. this relationship exists because of a foreign keycountry_idincountry_languagesthat referencescountries(country_id) - It has a one-to-many relationship with
country_stats. This relationship exists because of a foreign keycountry_idincountry_statsthat referencescountries(country_id) - It has a many-to-many relationship with
languages. This relationship exists because third tablecountry_languagesreferences both primary keyscountries(country_id)andlanguages(language_id)as its foreign keys.
country_languages
- It has a one-to-many relationship with
countries. this relationship exists because of a foreign keycountry_idincountry_languagesthat referencescountries(country_id) - It has a one-to-many relationship with
languages. this relationship exists because of a foreign keylanguage_idincountry_languagesthat referenceslanguages(language_id)
country_stats
- It has a one-to-many relationship with
countries. This relationship exists because of a foreign keycountry_idincountry_statsthat referencescountries(country_id)
languages
- It has a one-to-many relationship with
country_loanguages. This relationship exists because of a foreign keylanguage_idincountry_languagesthat referenceslanguages(language_id) - It has a many-to-many relationship with
countries. This relationship exists because third tablecountry_languagesreferences both primary keyscountries(country_id)andlanguages(language_id)as its foreign keys.
region_areas
regions
- It has a one-to-many relationship with
continents. This relationship exists because of a foreign keycontinent_idinregionsthat referencescontinents(continent_id) - It has a one-to-many relationship with
countries. This relationship exists because of a foreign keyregion_idincountriesthat referencesregions(region_id)
Create table for the data sourced from FDA CAERS website, and examine dataset using PostgreSQL for normalization.
(All related SQL files are in src folder)
-- 1. Thie query tries to determine whether or not report id is unique
SELECT
report_id,
count(*) as report_id_count
FROM staging_caers_event_product
GROUP BY report_id
HAVING count(*) > 1
ORDER BY report_id_count DESC
LIMIT 5;
-- report_id | report_id_count
-------------+-----------------
-- 179852 | 44
-- 174049 | 39
-- 117851 | 39
-- 141218 | 36
-- 210074 | 35
--(5 rows)
-- Based on the output, report_id cannot be a primary key because value is not unique.
-- 2. This query check whether we have duplicate rows or not
SELECT fda_first_received_report_date, report_id,
event_date, product_type, product, product_code,
description, patient_age, age_units, sex,
case_meddra_preferred_terms, case_outcome, COUNT(*) as duplicates_count
FROM staging_caers_event_product
GROUP BY fda_first_received_report_date, report_id,
event_date, product_type, product, product_code,
description, patient_age, age_units, sex,
case_meddra_preferred_terms, case_outcome
HAVING COUNT(*) > 1
LIMIT 5;
-- fda_first_received_report_date | report_id | event_date | product_type | product | product_code | description | patient_age | age_units | sex | case_meddra_preferred_terms | case_outcome | duplicates_count
----------------------------------+-----------+------------+--------------+----------------+--------------+----------------------------------------+-------------+-----------+--------+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+----------------------------------------------------------------------------------+------------------
-- 2004-01-22 | 65952 | | SUSPECT | EXEMPTION 4 | 54 | Vit/Min/Prot/Unconv Diet(Human/Animal) | 60.00 | year(s) | Female | ABDOMINAL PAIN, COUGH, FATIGUE, FIBROMYALGIA, HEADACHE, IMMUNE SYSTEM DISORDER, IRRITABLE BOWEL SYNDROME, JOINT SWELLING, RASH | Visited a Health Care Provider | 2
-- 2004-03-12 | 70661 | | SUSPECT | EXEMPTION 4 | 53 | Cosmetics | | | Female | BLISTER, SWELLING | Visited a Health Care Provider | 2
-- 2004-04-13 | 68138 | | SUSPECT | EXEMPTION 4 | 53 | Cosmetics | 32.00 | year(s) | Female | BURNING SENSATION, HYPERSENSITIVITY, INFECTION, PRURITUS, SECRETION DISCHARGE, SWELLING | Visited a Health Care Provider | 5
-- 2004-05-21 | 69134 | 1999-08-01 | SUSPECT | EXEMPTION 4 | 54 | Vit/Min/Prot/Unconv Diet(Human/Animal) | 51.00 | year(s) | Female | ALANINE AMINOTRANSFERASE INCREASED, ASPARTATE AMINOTRANSFERASE INCREASED, BLOOD ALKALINE PHOSPHATASE INCREASED, GAMMA-GLUTAMYLTRANSFERASE INCREASED, HEPATITIS, HOSPITALISATION | Hospitalization, Other Serious or Important Medical Event, Other Serious Outcome | 2
-- 2004-06-09 | 69634 | | CONCOMITANT | FRUIT SMOOTHIE | 09 | Milk/Butter/Dried Milk Prod | | | Female | HEADACHE, VOMITING | Other Outcome | 2
--(5 rows)
-- Based on the output, we have duplicate rows in table. Therefore, our table currently does not satisfy 1NF.
-- 3. To satisfy 1NF, we need to drop duplicate rows This query delete duplicate rows from the table
CREATE OR REPLACE VIEW staging_caers_event_product_view AS
SELECT DISTINCT fda_first_received_report_date, report_id,
event_date, product_type, product, product_code,
description, patient_age, age_units, sex,
case_meddra_preferred_terms, case_outcome
FROM staging_caers_event_product;
-- CREATE VIEW
-- Based on the output, we successfully extract unique rows from our table and saved them as a view.
-- 4. Find candidate keys by adding new columns until there are no duplicates
SELECT report_id, product_type, product, product_code, COUNT(*) AS duplicates_count
FROM staging_caers_event_product_view
GROUP BY report_id, product_type, product, product_code
HAVING COUNT(*) > 1
LIMIT 5;
-- report_id | product_type | product | product_code | duplicates_count
-------------+--------------+---------+--------------+------------------
--(0 rows)
-- Based on the output, our possible candidate key column combinations are report_id, product_type, product, and product_code because with this composite columns, we can identify unique rows
-- 5. This query check functional dependency between product_code and description
SELECT product_code, COUNT(*) AS count
FROM(
SELECT DISTINCT product_code, description
FROM staging_caers_event_product_view
) tmp
GROUP BY product_code
ORDER BY count DESC
LIMIT 5;
-- product_code | count
----------------+-------
-- 34 | 1
-- 18 | 1
-- 32 | 1
-- 37 | 1
-- 13 | 1
--(5 rows)
-- Based on the output, description is functionally dependent on product_code because only unique description value is associated with unique product_code
-- 5. Check partial key dependency between composite keys
SELECT product, COUNT(*) AS count
FROM(
SELECT DISTINCT product, product_code
FROM staging_caers_event_product_view
) tmp
GROUP BY product
ORDER BY count DESC
LIMIT 5;
-- product | count
---------------------------+-------
-- EXEMPTION 4 | 40
-- SALAD | 5
-- TURMERIC | 4
-- JIF PEANUT BUTTER | 4
-- DAILY HARVEST SMOOTHIES | 4
--(5 rows)
-- Based on this output, the product column is not functionally dependent on the product_code column because many products are associated with same product_code.
-- 6. Column "case_meddra_preferred_terms" is not atomic.
-- This query check all distinct terms in "case_meddra_preferred_terms" column
SELECT DISTINCT unnest(string_to_array(case_meddra_preferred_terms, ', ')) AS preferred_term
FROM staging_caers_event_product_view
LIMIT 5;
-- preferred_term
--------------------------
-- Abortion threatened
-- KAWASAKI'S DISEASE
-- BONE CANCER METASTATIC
-- EMBOLISM
-- URINE ANALYSIS
--(5 rows)
-- Based on the output, we should make seperate table for prefereed term with these distinct values.
-- 7. Column "case_outcome" is not atomic.
-- This query check all distinct terms in "case_outcome" column
SELECT DISTINCT unnest(string_to_array(case_outcome, ', ')) AS outcome
FROM staging_caers_event_product_view;
-- outcome
--------------------------------------------
-- Other Serious Outcome
-- Death
-- Injury
-- Visited Emergency Room
-- Life Threatening
-- Required Intervention
-- Visited a Health Care Provider
-- Other Serious or Important Medical Event
-- Other Outcome
-- Hospitalization
-- Disability
-- Allergic Reaction
-- Congenital Anomaly
--(13 rows)
-- Based on the output, we should make seperate table for prefereed term with these distinct values.
-- 8. To optimize our database storage, check the max lengths for each cols
SELECT MAX(char_length(report_id)) FROM staging_caers_event_product_view; -- 15
SELECT MAX(char_length(product_type)) FROM staging_caers_event_product_view; -- 11
SELECT MAX(char_length(product)) FROM staging_caers_event_product_view; -- 200
SELECT MAX(char_length(product_code)) FROM staging_caers_event_product_view; -- 3
SELECT MAX(char_length(description)) FROM staging_caers_event_product_view; -- 44
SELECT MAX(char_length(age_units)) FROM staging_caers_event_product_view; -- 9
SELECT MAX(char_length(sex)) FROM staging_caers_event_product_view; -- 12
-- Based on the output, we can save each columns - report_id, product_type, product, product_code, description, age_units, sex - into each max length varcahr.
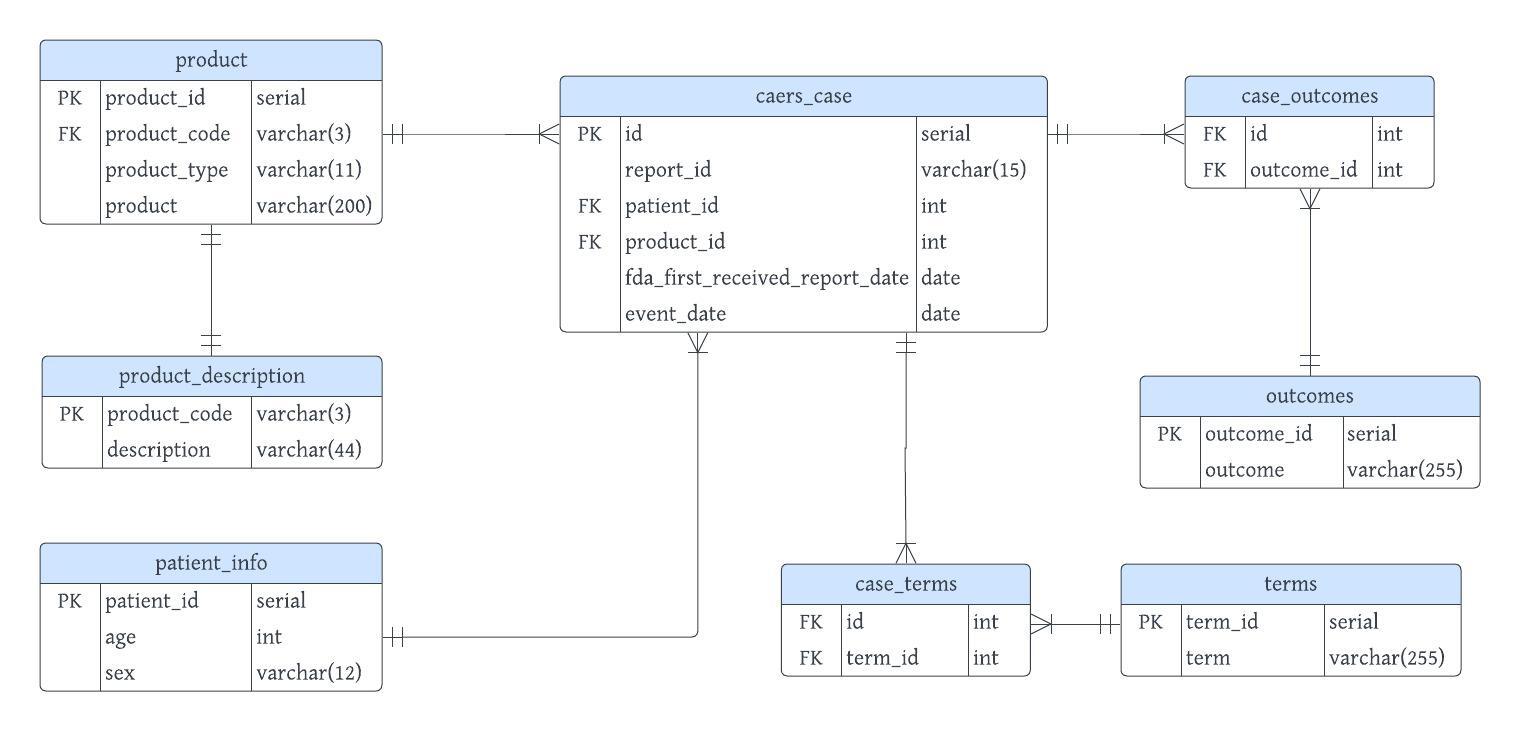
caers_case
- I made one caers case with column report_id, fda_first_received_report_date, event_date. I didn't use the first candidate key that I first assumed because I wanted to have seperate table for
productbecause uniqueproductcan be associated with manycaers_case, so that we can save database storage. For same reason, I wanted to seperatepatienttoo fromcaers_case. In addition to this, I needed to seperatecase_meddra_preferred_termsandcase_outcomecolumn because those two columns have multiple values. Therefore, I only keptreport_id,fda_first_received_report_date, andevent_datefrom original data and insertpatient_idandproduct_idfor table relation and addedidfor primary key
product
- I made seperate table for product. This table contains all information for product. Add
product_idfor primary key and setproduct_codeas foreign key for one-to-one table relationship withproduct_description
product_description
- I made seperate table for
product_codeanddescriptionbecause I noticed they are functionally dependet. Setproduct_codeas primary key.
patient_info
- I made seperate table for patient.
patient_ageandage_unitscan be combined together intoageby calculation with query, so I addedageinstead of two columns and addpatient_idas primary key.
case_terms
- I made join table for
caers_caseandtermsfor seperate multiple values incase_meddra_preferred_termscolumn. Setidandterm_idas foreign key for table relation
terms
- I made seperate table for each unique values in
case_meddra_preferred_termscolumn and connect withcaers_casemany-to-many relation with using join tablecase_term
case_outcomes
- I made join table for
caers_caseandoutcomesfor seperate multiple values incase_outcomecolumn. Setidandoutcome_idas foreign key for table relation
outcomes
- I made seperate table for each unique values in
case_outcomecolumn and connect withcaers_casemany-to-many relation with using join tablecase_outcomes