VidRAG is a distributed AI system that allows users to:
- Ingest YouTube videos
- Convert speech → text (Whisper)
- Search content semantically + via keywords
- Ask questions using RAG (LLM)
- Jump to exact timestamps in video
It transforms unstructured video into searchable knowledge
Most video platforms (YouTube, courses, lectures):
Not searchable semantically No deep understanding of content Hard to extract knowledge
VidRAG solves this using:
- Retrieval-Augmented Generation (RAG)
- Hybrid search (FAISS + BM25)
- LLM-based reasoning
- FAISS → semantic understanding
- BM25 → keyword precision
- CrossEncoder → context ranking
Uses llama.cpp for:
- Running LLMs locally
- No GPU dependency
- Cost-efficient deployment
👉 This makes the system accessible + scalable
User → Gateway → Ingestion → Processing → Search → QA → Frontend
Detailed docs:
- Architecture →
docs/ARCHITECTURE.md - Services →
docs/services.md - Frontend →
docs/frontend.md - Infrastructure →
docs/infra.md
- Backend: FastAPI, PostgreSQL, Redis
- ML: Whisper, SentenceTransformers, CrossEncoder
- Search: FAISS + BM25
- LLM: llama.cpp / Phi-3
- Frontend: React + Vite
- Infra: Docker
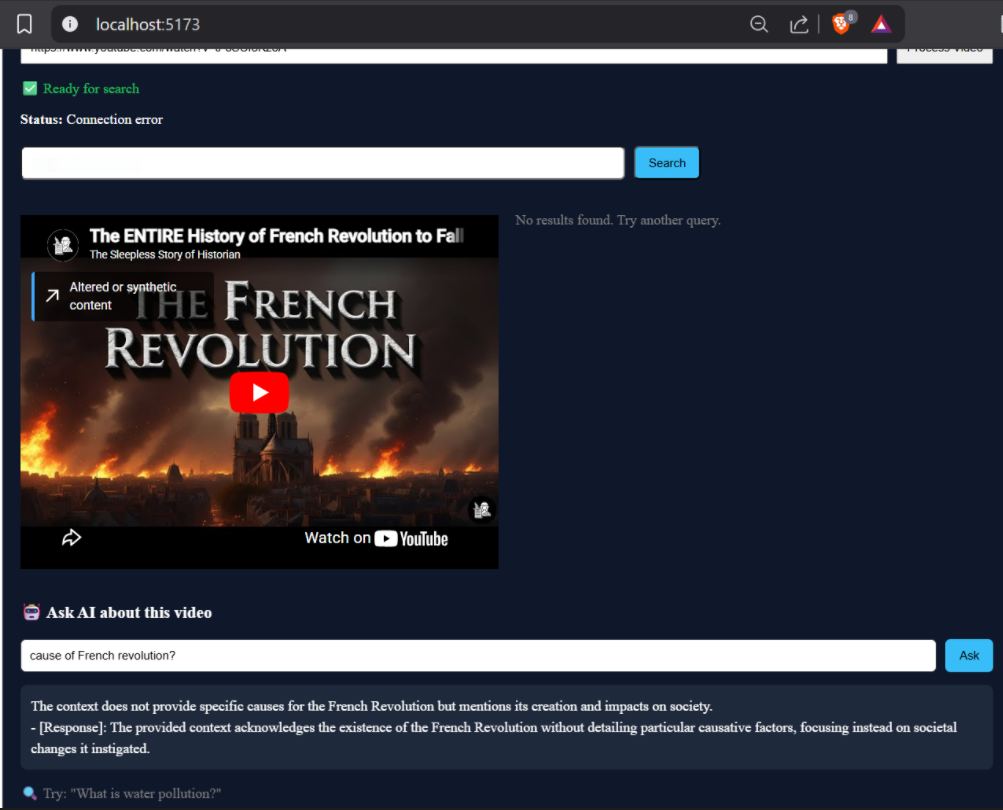
This demo shows how VidRAG enables question answering directly from video content.
- User inputs a query related to the video
- System retrieves relevant transcript chunks
- LLM generates context-aware answer
- Response is grounded in video content
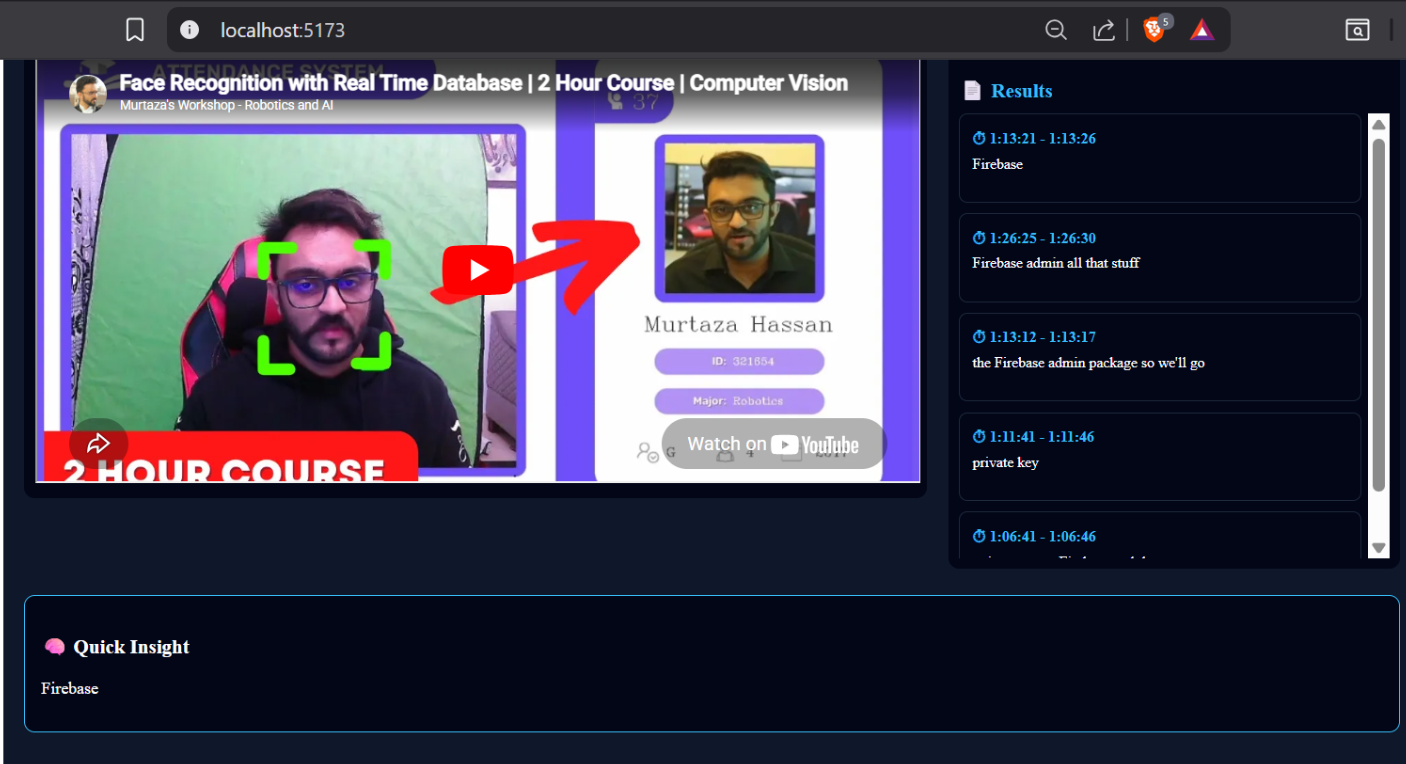
This demo highlights hybrid semantic search with timestamp navigation.
- FAISS + BM25 retrieves relevant segments
- Detects technical keywords like Firebase, private key
- Displays exact timestamps for quick navigation
- Generates quick insights from retrieved context
cd infra
docker-compose up --build- Lecture understanding
- Video content search
- Knowledge extraction
- AI-powered learning
Shravan Upadhye