#Image Classification using deep learning
Image classification basically deals with classifying images in different classes. The dataset that we have used is MNIST dataset of hand written digits. It consists of 70,000 gray-scale images of hand-written digits of dimension (28,28)

In the first part, we have tried to make a network. The network architecture consists of two hidden layers with 512 and 256 and then the output layer with softmax classifier. We have run the network for 40 epochs .

The accuracy and loss on the test data is as follows:

In this part, the network architecture that we are using contains two convolutional layers one after the other with a filter size of (3,3). The first block contains 32 different fuilters of (3,3) and second layer consists of 64 different filters of (3,3) which are followed by a maxpool layer with shride 2 to reduce its size, then there is a dense layer which is then followed by the output layer with softmax classifier. We have used dropouts in dense layers.

The Network architecture is as follows(by tensorboard):


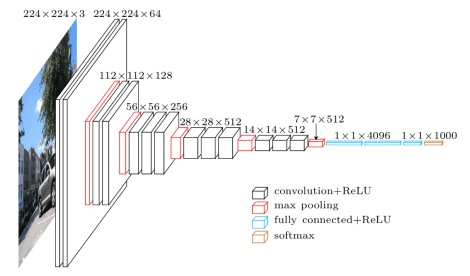
This network is characterized by its simplicity, using only 3×3 convolutional layers stacked on top of each other in increasing depth. VGGNet is invented by VGG (Visual Geometry Group) from University of Oxford. VGGNet is the 1st runner-up of the ILSVRC (ImageNet Large Scale Visual Recognition Competition) 2014 in the classification task. We have tried to classiffy images using VGGNet. The main use of VGG was earlier 11×11 or 5×5 filters were used in convolutional steps. The main idea of VGGNet is to use 3×3 filters in convolutional layers followed by other 3×3 filters convolutional layers. Thus, it is computationally better than 11×11 or 5×5 filters convolutions. Two consecutive convolutional layer step is then followed by a Max-pool layer which will reduce the size of the image, allowing the next convolutional layer to learn bigger patterns in the images.


The accuracy and loss on the test data is as follows:


ResNet Architecture(Source)
In case of very large networks, there is a problem of accuracy saturation. Thus, ResNet is based on the idea of use of residual blocks.
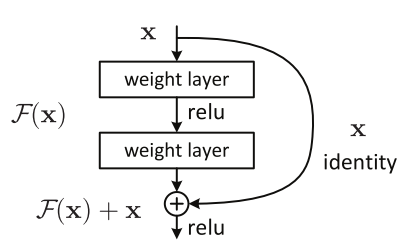
Residual blocks are based on the idea of skip connections or identity shortcut connections, that can skip one or more layer. Thus, helps to build bigger networks. We are using transfer learning and the inbuilt resnet from Keras. The activation from a previous layer is being added to the activation of a deeper layer in the network.

The Network architecture is as follows(by tensorboard):

The accuracy and loss on the test data is as follows:
