Unofficial fork at
smolix/mxnet— Blackwell (sm_120) port of MXNet 2.0.Apache MXNet was archived on 2023-11-17. The upstream tree is frozen at CUDA 11 / cuDNN 8 / oneDNN v2 and does not build on Blackwell GPUs or modern CUDA toolchains. This fork carries the minimum set of patches needed to run existing MXNet code on current hardware. It is not an official Apache release.
Current version string: 2.0.0+cu13.bw.20260517
(<upstream-version>+cu<cuda-major>.bw.<YYYYMMDD>).
The primary goal is to run existing MXNet notebooks on Blackwell (RTX PRO
4000 / RTX 50-series / B100-class) hardware with the current CUDA 13 +
cuDNN 9 + oneDNN v3 + NCCL 2.28 stack. The secondary goal is to keep the
residual MXNet user community (legacy research code, frozen production
pipelines, niche operators like _contrib_quantize_*) able to use current
GPUs without a full rewrite to PyTorch / JAX. See issues.md for
the open work list and priority-ordered triage.
- Blackwell
sm_120SASS / PTX (CUDA 13.0), plus sm_80 (Ampere), sm_86 (Ada), sm_89 (RTX 40), sm_90 (H100), and PTX 120 fallback in fatbin. - cuDNN 9.22 — including the rewritten v8 RNN path (LSTM / GRU / vanilla
RNN, fwd + bwd). TF32 enabled by default on FP32 conv (mirrors PyTorch /
TensorFlow defaults; ~2.87× speedup on sm_120 vs the legacy
MXNET_CUDA_TENSOR_OP_MATH_ALLOW_CONVERSION=0mode). - oneDNN v3.11 — full INT8 path (per-OC weight scales, fused conv/FC, fused sum, dequant-to-fp32 output).
- NCCL 2.28 — single-process / multi-GPU.
- INT8 quantization (
quantize_net,_sg_onednn_conv,_sg_onednn_fully_connected). - fp16 and fp32 forward + backward training.
- F16C CPU intrinsics for fast fp16 host (de)serialization.
- DNNL subgraph fusion, the activation/eltwise/layer-norm/softmax stack, pooling, batch norm fwd+bwd, transpose, concat, where, masked softmax.
- bf16 on non-AVX-512-BF16 CPUs — oneDNN falls back to fp32 emulation; not fixable in software, test on Intel SPR or AMD Zen 4 / Granite Rapids.
- Backward through quantized ops — forward inference is solid; backward
through
_sg_onednn_fully_connectedand_sg_onednn_convis unvalidated. - AMP (automatic mixed precision) subgraph — 6 known failures with
inner_productprimitive creation; investigation pending. - int8 quantized concat —
test_pos_single_concat_pos_neg[*-data_shape1]fails with entire output channels zeroed; suspect oneDNN v3 uint8→int8 reorder semantics. - ONNX export / import — both
tests/python/onnx/test_models.pyandtest_operators.pyerror at collect time; the ONNX path was not updated for MXNet 2.0 numpy ops. - See
issues.mdfor the full open list (45 items).
- Linux x86_64 (tested on Ubuntu 22.04 / 24.04).
- NVIDIA driver supporting CUDA 13 (R570+).
- CUDA 13.0 toolkit.
- cuDNN 9.22+ (cuDNN 9.22 has the best
sm_120heuristic coverage; earlier 9.x works but routes more conv shapes through generic fallback engines — notably depthwise 3×3 is ~7× faster on 9.22 vs 9.14). The release wheel bundles 9.22 undermxnet/lib/. - NCCL 2.28.3.
- Python 3.10+ (3.11 / 3.12 / 3.13 are CI-tested).
pip install https://github.com/smolix/mxnet/releases/download/v2.0.0.cu13.bw.20260517-beta/mxnet-2.0.0+cu13.bw.20260517-cp311-cp311-linux_x86_64.whlThe wheel itself is 454 MB. pip will transitively pull
nvidia-cudnn-cu13 (~1 GB) and nvidia-nccl-cu13 (~190 MB). The
remaining CUDA 13 toolkit libs (libcudart.so.13, libcublas.so.13,
libcufft.so.12, libcusolver.so.12, libcurand.so.10,
libnvrtc.so.13) come from your system CUDA 13 install at
/usr/local/cuda/ — NVIDIA has not yet published cu13 wheels for
those on PyPI (the rest of the nvidia-*-cu13 packages are placeholder
stubs at version 0.0.1 as of 2026-05-17). libmxnet.so's RUNPATH
covers both locations.
Requires Python 3.11, Linux x86_64, NVIDIA driver R570+, and the CUDA
13 toolkit installed at /usr/local/cuda/ (e.g. apt install cuda-13).
To build from source see BUILDING.md. The short version
is: clone with submodules, install libnccl-dev before invoking cmake,
then cmake -DUSE_CUDA=ON -DCUDA_ARCH_LIST="12.0" ...
This fork builds on the work of the Apache MXNet community and its contributors. All upstream code is Apache 2.0; the Blackwell / CUDA 13 patches in this fork are likewise Apache 2.0. The original project history follows below — its build status badges, social links, and roadmap targets refer to the (now archived) upstream and are kept for historical reference.
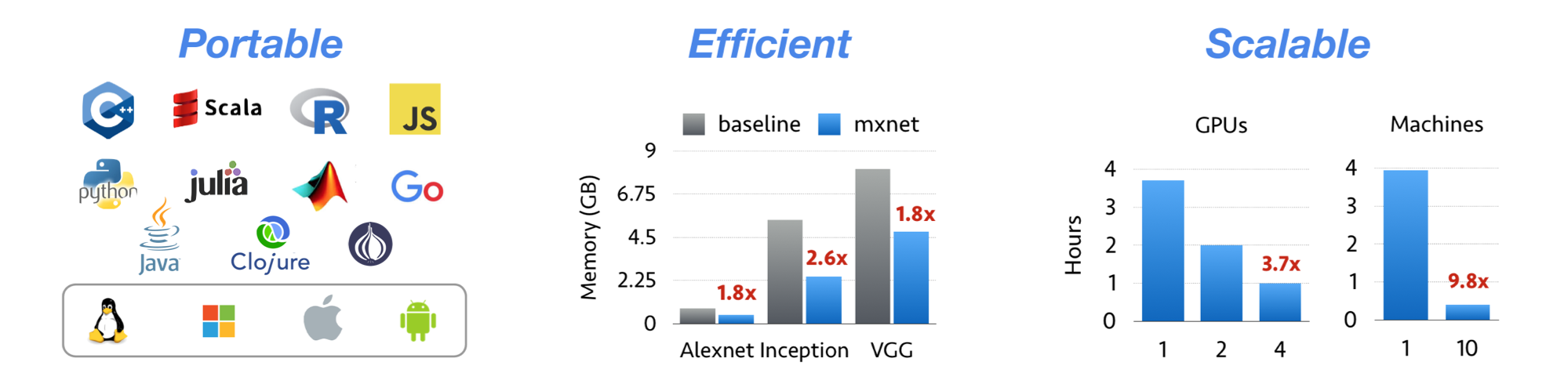
Note: the sections below describe the original Apache MXNet 2.0 project. They are kept verbatim for historical context. Build status badges, mailing lists, Slack channels, and Twitter/Medium links refer to the archived upstream project and are not actively monitored.



















Apache MXNet is a deep learning framework designed for both efficiency and flexibility. It allows you to mix symbolic and imperative programming to maximize efficiency and productivity. At its core, MXNet contains a dynamic dependency scheduler that automatically parallelizes both symbolic and imperative operations on the fly. A graph optimization layer on top of that makes symbolic execution fast and memory efficient. MXNet is portable and lightweight, scalable to many GPUs and machines.
Apache MXNet is more than a deep learning project. It is a community on a mission of democratizing AI. It is a collection of blue prints and guidelines for building deep learning systems, and interesting insights of DL systems for hackers.
Licensed under an Apache-2.0 license.
| Branch | Build Status |
|---|---|
| master | |
| v1.x |
- NumPy-like programming interface, and is integrated with the new, easy-to-use Gluon 2.0 interface. NumPy users can easily adopt MXNet and start in deep learning.
- Automatic hybridization provides imperative programming with the performance of traditional symbolic programming.
- Lightweight, memory-efficient, and portable to smart devices through native cross-compilation support on ARM, and through ecosystem projects such as TVM, TensorRT, OpenVINO.
- Scales up to multi GPUs and distributed setting with auto parallelism through ps-lite, Horovod, and BytePS.
- Extensible backend that supports full customization, allowing integration with custom accelerator libraries and in-house hardware without the need to maintain a fork.
- Support for Python, Java, C++, R, Scala, Clojure, Go, Javascript, Perl, and Julia.
- Cloud-friendly and directly compatible with AWS and Azure.
- 1.9.1 Release - MXNet 1.9.1 Release.
- 1.8.0 Release - MXNet 1.8.0 Release.
- 1.7.0 Release - MXNet 1.7.0 Release.
- 1.6.0 Release - MXNet 1.6.0 Release.
- 1.5.1 Release - MXNet 1.5.1 Patch Release.
- 1.5.0 Release - MXNet 1.5.0 Release.
- 1.4.1 Release - MXNet 1.4.1 Patch Release.
- 1.4.0 Release - MXNet 1.4.0 Release.
- 1.3.1 Release - MXNet 1.3.1 Patch Release.
- 1.3.0 Release - MXNet 1.3.0 Release.
- 1.2.0 Release - MXNet 1.2.0 Release.
- 1.1.0 Release - MXNet 1.1.0 Release.
- 1.0.0 Release - MXNet 1.0.0 Release.
- 0.12.1 Release - MXNet 0.12.1 Patch Release.
- 0.12.0 Release - MXNet 0.12.0 Release.
- 0.11.0 Release - MXNet 0.11.0 Release.
- Apache Incubator - We are now an Apache Incubator project.
- 0.10.0 Release - MXNet 0.10.0 Release.
- 0.9.3 Release - First 0.9 official release.
- 0.9.1 Release (NNVM refactor) - NNVM branch is merged into master now. An official release will be made soon.
- 0.8.0 Release
- oneDNN for Faster CPU Performance
- MXNet Memory Monger, Training Deeper Nets with Sublinear Memory Cost
- Tutorial for NVidia GTC 2016
- MXNet.js: Javascript Package for Deep Learning in Browser (without server)
- Guide to Creating New Operators (Layers)
- Go binding for inference
| Channel | Purpose |
|---|---|
| Follow MXNet Development on Github | See what's going on in the MXNet project. |
| MXNet Confluence Wiki for Developers | MXNet developer wiki for information related to project development, maintained by contributors and developers. To request write access, send an email to send request to the dev list . |
| dev@mxnet.apache.org mailing list | The "dev list". Discussions about the development of MXNet. To subscribe, send an email to dev-subscribe@mxnet.apache.org . |
| discuss.mxnet.io | Asking & answering MXNet usage questions. |
| Apache Slack #mxnet Channel | Connect with MXNet and other Apache developers. To join the MXNet slack channel send request to the dev list . |
| Follow MXNet on Social Media | Get updates about new features and events. |
Keep connected with the latest MXNet news and updates.
 Apache MXNet on Twitter
Apache MXNet on Twitter
 Contributor and user blogs about MXNet
Contributor and user blogs about MXNet
 Discuss MXNet on r/mxnet
Discuss MXNet on r/mxnet Apache MXNet YouTube channel
Apache MXNet YouTube channel Apache MXNet on LinkedIn
Apache MXNet on LinkedInMXNet emerged from a collaboration by the authors of cxxnet, minerva, and purine2. The project reflects what we have learned from the past projects. MXNet combines aspects of each of these projects to achieve flexibility, speed, and memory efficiency.
Tianqi Chen, Mu Li, Yutian Li, Min Lin, Naiyan Wang, Minjie Wang, Tianjun Xiao, Bing Xu, Chiyuan Zhang, and Zheng Zhang. MXNet: A Flexible and Efficient Machine Learning Library for Heterogeneous Distributed Systems. In Neural Information Processing Systems, Workshop on Machine Learning Systems, 2015