1236. Web Crawler #6
Description
Burada, arama motorlarının "crawler" denilen mekanizmasını simüle eden bir sistem tasarlayacağız.
Bu sistem bazen "örümcek" olarak da adlandırılır.
Bir url altındaki tüm linkleri toplar. Buna "crawl" etmek diyelim.
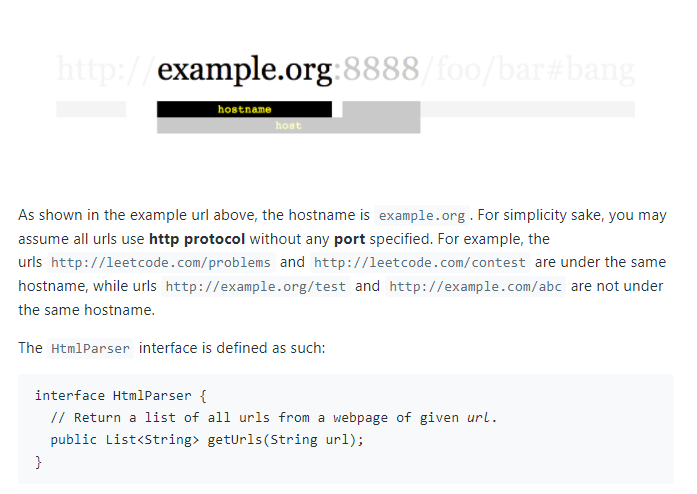
Bunu simule etmek için soruda HtmlParser denilen bir parser verilmiş.
Gûyâ, ona url parametresi ile bir link ona gönderildiğinde, bize o link altındaki tüm url'lerin listesini o gönderecek.
interface HtmlParser {
public List<String> getUrls(String url) {}
}
Bizim tarafımızda ise, şu kod implement edilmeli:
public List<String> crawl(String startUrl, HtmlParser htmlParser) {
}
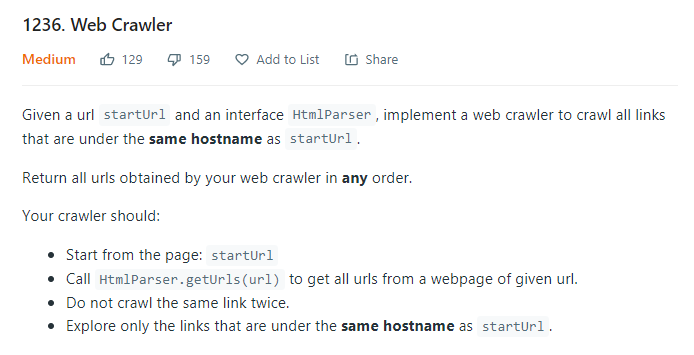
Dikkat edilecek hususlar:
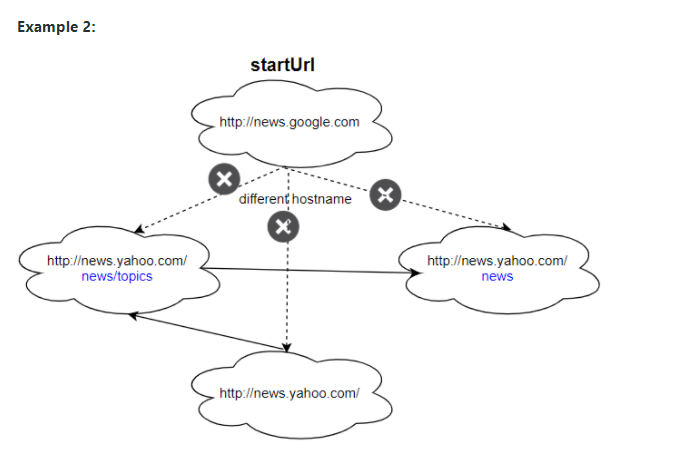
- startUrl ile belirtilen sayfadan başlanmalı.
- Verilen web sayfasının altındaki tüm linkleri çekmek için HtmlParser.getUrls(url) çağrılmalı.
- Aynı link birden fazla kez "crawl" edilmeyecek.
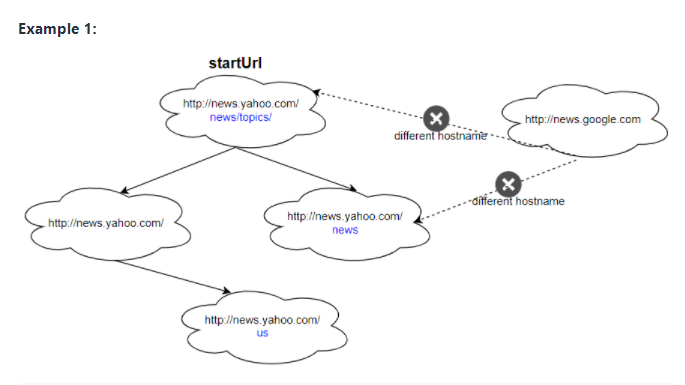
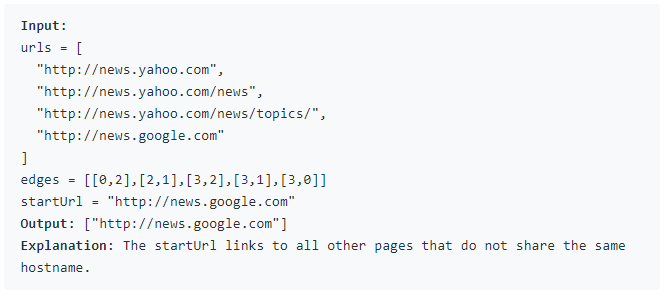
- Sâdece startUrl ile aynı url altındaki linkleri tara.