Stan summary() method header should be on one line #600
Description
Summary:
The summary being dumped by .stansummary() is being rendered like this
>>> fit_dice.summary()
Mean MCSE StdDev 5% 50% 95% N_Eff N_Eff/s R_hat
name
lp__ 0.00000 NaN 0.00000 0 0 0 NaN NaN NaN
x 3.46225 0.027806 1.72099 1 3 6 3830.87 93435.8 1.000050
y 3.47550 0.027395 1.70767 1 3 6 3885.67 94772.4 1.000100
z 6.93775 0.038624 2.40579 3 7 11 3879.74 94627.8 0.999701
Fix it so that name is on the same line as the other header names.
Here's a tutorial on row names and indexing in pandas using the data frame method set_index()
Description
I'm labeling as a bug because this isn't how headers are supposed to work in tables. For example, it means we can't extract the names using the usual approach.
>>> s = fit_dice.summary()
>>> s["Mean"]
name
lp__ 0.00000
x 3.46225
y 3.47550
z 6.93775
Name: Mean, dtype: float64I see that this gets name carried over, which is surprising. Because the following doesn't work.
>>> s["name"]
Traceback (most recent call last):
File "/usr/local/lib/python3.9/site-packages/pandas/core/indexes/base.py", line 3621, in get_loc
return self._engine.get_loc(casted_key)
File "pandas/_libs/index.pyx", line 136, in pandas._libs.index.IndexEngine.get_loc
File "pandas/_libs/index.pyx", line 163, in pandas._libs.index.IndexEngine.get_loc
File "pandas/_libs/hashtable_class_helper.pxi", line 5198, in pandas._libs.hashtable.PyObjectHashTable.get_item
File "pandas/_libs/hashtable_class_helper.pxi", line 5206, in pandas._libs.hashtable.PyObjectHashTable.get_item
KeyError: 'name'It also renders poorly through Quarto with an extra wasted line:
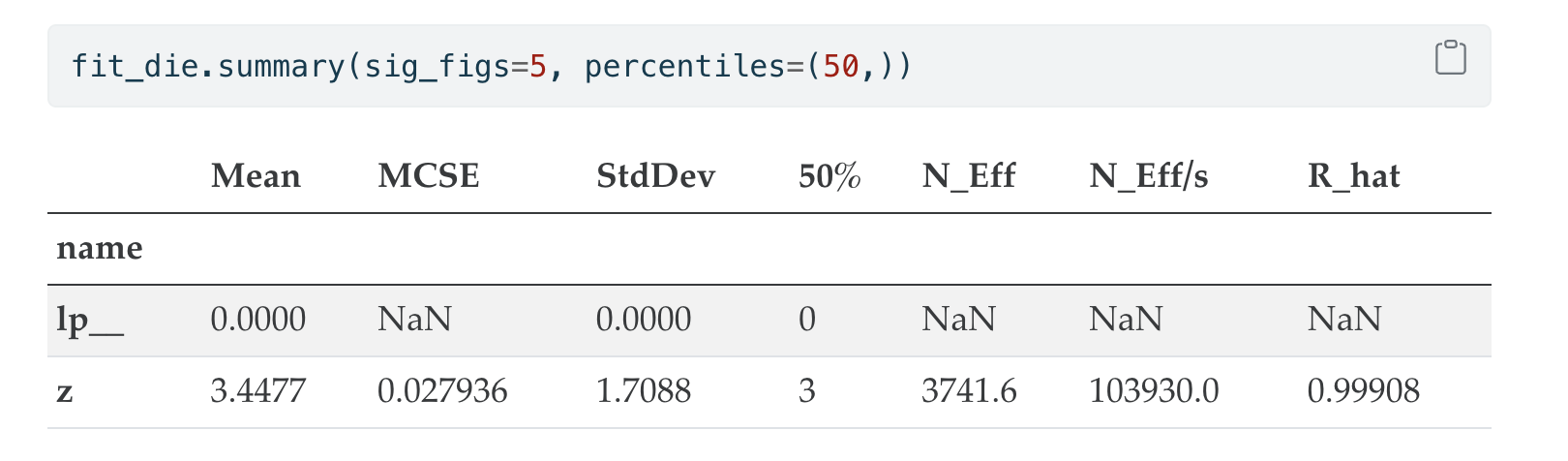
Description:
Additional Information:
I'm filing this issue for cmdstanpy because that's where I want to see the fix. Even if this problem originates in CmdStan, I think it's going to be easier to fix in CmdStanPy because there won't be the same backward compatibility issues.
Meanwhile, is there an easy way I can hack this all to fix it myself?
Current Version:
>>> import cmdstanpy
>>> cmdstanpy.show_versions()
INSTALLED VERSIONS
---------------------
python: 3.9.4 (default, Apr 5 2021, 01:47:16)
[Clang 11.0.0 (clang-1100.0.33.17)]
python-bits: 64
OS: Darwin
OS-release: 21.6.0
machine: x86_64
processor: i386
byteorder: little
LC_ALL: None
LANG: en_US.UTF-8
LOCALE: ('en_US', 'UTF-8')
cmdstan_folder: /Users/bcarpenter/.cmdstan/cmdstan-2.30.0
cmdstan: (2, 30)
cmdstanpy: 1.0.4
pandas: 1.4.3
xarray: None
tdqm: None
numpy: 1.21.4
ujson: 5.4.0
' '