Add the introduction part to Snippet Tutorial #397
Conversation
|
Check out this pull request on See visual diffs & provide feedback on Jupyter Notebooks. Powered by ReviewNB |
|
@seanlaw: And, as you suggested, I tried to submit the first PR on this issue that includes only small changes. I will consider that 50 lines rule of thumb for subsequent pushes. |
Codecov Report
@@ Coverage Diff @@
## main #397 +/- ##
=========================================
Coverage 100.00% 100.00%
=========================================
Files 34 35 +1
Lines 2713 2719 +6
=========================================
+ Hits 2713 2719 +6
Continue to review full report at Codecov.
|

| @@ -1,5 +1,29 @@ | |||
| { | |||
There was a problem hiding this comment.
@ninimama I think this is pretty good and here are a couple of comments:
- In your opening sentence, it is claimed that it is a "common question" but it would be nice to provide some (obvious) real-world examples if possible
- I like the point that you are trying to make about snippets vs clustering but the clustering point could be a bit clearer
- "Although a clustering" should be "Although clustering"
- Since we acknowledge the original papers in the first sentence, there is no need to repeat things like "Authors in Matrix Profile XIII". We make no claims of these ideas being our own original ideas
- So, I don't think the final tutorial will go through the creation of the toy data. We will just create it in Zenodo.ipynb and then download the final data to analyze
Reply via ReviewNB
Yes, that should be fine
Sounds good! Thanks |
In my recent commit, I keep the toy data for now and just add textual context and improve the current flow/figures. I tried to follow the same structure used in the other tutorials. I can take care of retrieving the data from Zenodo in the future commits (If you have any suggestion regarding this matter, please let me know) ================================================ I have one question that has been bothering me: Sometimes I try to limit the changes into one particular area to avoid the term "and" in the commit message. In other words, I would like to consider each commit for one particular issue. So, it would be easier for the reviewer (you) to go through the changes in the commit. However, in some occasions, there are only a few changes that need to be done for a particular issue. For instance, adding the heading to the notebook is probably less than 10 lines. Or, modifying figures (and change their orders) is again less than 10 lines. This can easily happen in different scenarios, when I try to improve different parts of the Tutorial. Is that okay to do one git commit for all those small changes? (This is what I did in my recent commit that I pushed) OR: Can I do three small commits (each corresponds to small changes). Then, after a few commits, I can do git push. Since I don't know how the review process looks like on your end, I have no idea if the latter approach makes sense or not. |
|
@ninimama I can handle the Zenodo upload part. Let's just keep it as is for now Regarding commits, I wouldn't worry so much about tutorials. I think you can bundle a few things into a single commit for a notebook and then let me know in this comments section if there is anything that I need to know. I can tell you that I am not looking at every single commit. In fact, I'm only looking at the latest version via the "ReviewNB" purple button above. |
| @@ -1,8 +1,51 @@ | |||
| { | |||
There was a problem hiding this comment.
| @@ -1,8 +1,51 @@ | |||
| { | |||
There was a problem hiding this comment.
- You said "common question" but you've only presented a statement.
- Please remove "large" in "large time series" and then combine that sentence with the one following it
- Please replace "his sleep" with "their sleep"
This paragraph seems somewhat forced and out of place:
For instance, the respiration data of a person recorded during his sleep can be reported by showing only the top-2 snippets. As an another example, snippets can be used to find different stages in the walking-nordic walking-skipping-running cycle of a person. Particularly, the y-axis acceleration data recorded by a chest-worn sensor can be summarized into top-4 snippets where each snippet shows a different type of exercise.
This may be something that we'll need to think through and provide proper motivation without getting into too much unnecessary detail.
I think that the It is worthwhile to note what snippet is NOT part should not be in the starting section and should be its own section header
This sentence isn't so clear:
one should specify the beginning and ending of subsequences and then apply clustering on the set of subseuqences
Reply via ReviewNB
I am still thinking about it (I put "?" in the corresponding part in the notebook. =================================================== Just to confirm: Would you like to reproduce the result of another data (other than the toy data currently provided in the notebook)? |
I like the toy data as it is simple/easy to understand and it helps to lay the foundation for explaining things. However, I am open to adding a slightly more interesting example from the paper (if it exists) AFTER the toy data set. Of course, this runs the risk of making the tutorial too long/redundant. Unfortunately, it's one of those things that we'll need to decide whether it makes the tutorial "better"/"worse" only after it is added. How does that sound? |
Exactly! In fact, I, as a reader, prefer to understand the basics quickly and easily, and then go and explore my own data. ================================================================== The reason I asked was that I misinterpreted one of our previous conversations and I thought we should add a real data set. So, for now, I can try to polish the tutorial and see if I can find a good example of snippets application. |
| @@ -1,8 +1,84 @@ | |||
| { | |||
There was a problem hiding this comment.
I've just added a Matplotlib style file so the following lines:
plt.rcParams["figure.figsize"] = [20, 6] # width, height plt.rcParams['xtick.direction'] = 'out'
can be replaced with:
plt.style.use('stumpy.mplstyle')
Reply via ReviewNB
There was a problem hiding this comment.
@seanlaw
I have been busy with my research lately. Will take care of it and the other things soon.
There was a problem hiding this comment.
I have been busy with my research lately. Will take care of it and the other things soon.
@ninimama There is absolutely no rush. Quality over quantity! Please take your time
|
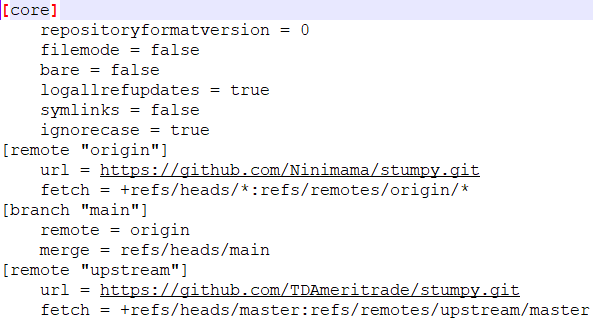
According to the github guide, I did
According to a stackoverflow question, I checked out the .git/config file (shown below) but things sound okay to me:
I also tried Could you please help me resolve this issue? (So, I can import mplstyle in my local repo) |
|
@ninimama I'm not entirely sure but it may be due to the fact that https://docs.github.com/en/github/collaborating-with-pull-requests/working-with-forks/syncing-a-fork |
|
@seanlaw And, now it works! |
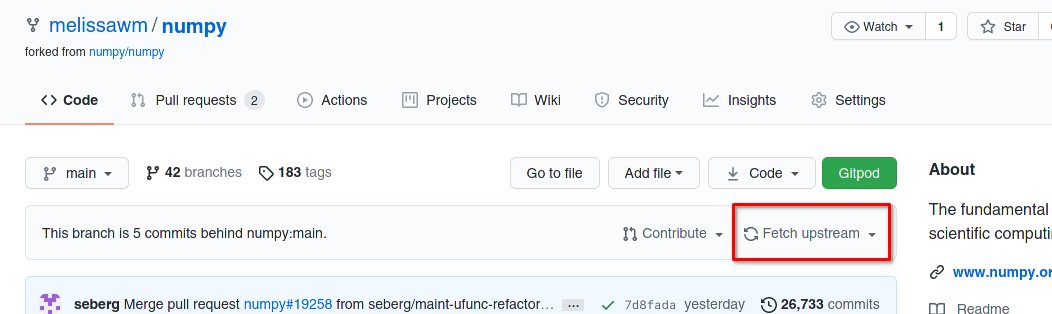
After asking around, I also learned that there is a button in your fork:
|
|
@ninimama Did you also happen to follow step 5 in https://docs.github.com/en/github/collaborating-with-pull-requests/working-with-forks/syncing-a-fork? It is one step to sync your fork with the I think this important process is missing from our contributor's guide. I've added a new issue #414 |
|
I think I did. And, if I remember correctly, the So, I did |
|
@ninimama I believe that both will work. However, https://www.atlassian.com/git/tutorials/merging-vs-rebasing Having said that, please don't be worried about doing it "perfectly". I am not familiar with this part of the process either and I am learning a lot about the challenges that a contributor is facing and this experience will help us make better documentation so that future contributors can benefit! So, you are doing us a huge favor by sharing your process. Thank you! |
I finished the unit tests. But before committing and pushing it, I would like to know if you have any particular definition of the concept of naive code. Below is my implementation: I also wrote a test function to compare it with the output of =================================================== However, after a quick search, I found a piece of code that is used in And, both |
So, we strongly prefer not adding any additional dependencies for testing as it affects our ability to maintain it long term. Self contained code is always preferred. I think your function is fine though the many |
|
Can you check if something like this might suffice? |
your implementation of the function
Regarding the ================================= You can check out the recently-pushed commits. |
stumpy/core.py
Outdated
| Parameters | ||
| ---------- | ||
| mask: ndarray | ||
| A boolean 1D array |
There was a problem hiding this comment.
The indentation looks off here
stumpy/core.py
Outdated
| Returns | ||
| ------- | ||
| slices: ndarray | ||
| slices of indices where the mask is True. Each slice has a size of two: |
There was a problem hiding this comment.
The indentation looks off here
tests/test_core.py
Outdated
| npt.assert_array_equal(left, right) | ||
|
|
||
|
|
||
| def naive_get_mask_slices(mask): |
There was a problem hiding this comment.
Please move this naive implementation to the top of the test file. See other test files to see the location of the naive implementation
There was a problem hiding this comment.
Please move this naive implementation to the top of the test file. See other test files to see the location of the naive implementation
I moved it to the TOP of the test_core.py file.
FYI: Just in case you missed it, NOT all naive implementations are at the TOP. there are some test functions between the naive implementations.
There was a problem hiding this comment.
Okay, would you mind creating a new issue to track this and then we can handle it in a separate issue from this one? I think it's best when the naive implementations are at the top of the file and then followed by the tests below it
|
|
||
|
|
||
| def test_get_mask_slices(): | ||
| bool_lst = [False, True] |
|
@seanlaw I noticed you used the naive implementation of mpdist in the unit test of snippets. I was wondering if I should move the function |
Yes, if you plan to use |
|
@ninimama Nit trying to rush you as I'm sure you are busy but I just wanted to check in in case you need something from me. Please let me know how I can help |
Thanks for checking in. I took a look but then I got a little busy doing my research. I will try to finish this at the end of this week. |
|
I revised the
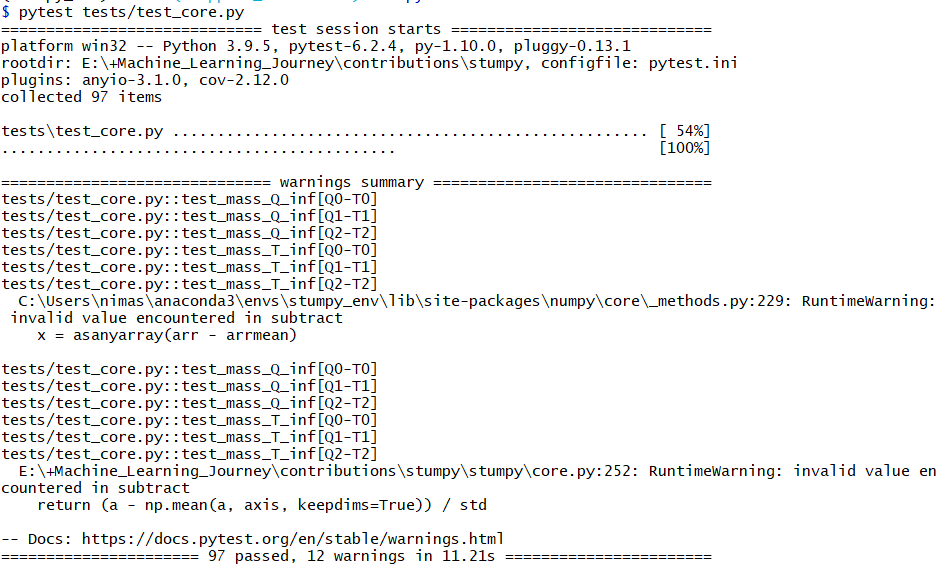
I am trying to fix this before doing the git push. If you think I should better do git push so you can take a look, please let me know. =================================================================== UPDATE: I ran the pytest only on
==================================================================== So, I don't know what causes the error. |

|
Yes, please push your latest changes and I can take a look. |
|
@ninimama So, it looks like the first thing that needs to be fixed is the code formatting. For STUMPY, we use the By running After you've resolved this, please commit the changes and push again. |
I thought black can automatically fix things and save them. But, after your note, I realized I have to do it and then do ========================================================== There we go! Finally! :) Thanks for your input. ========================================================== Just one note: The intro part of the tutorial notebook for |
As mentioned in the Contributing guide, for Python code, you should run both
Do you have any suggestions for this? I think the current example is simple and easy to understand but I agree that it would be nice to have a "real" example |
I, unfortunately, don't have any nice examples in mind. The authors provided several examples in the paper; however, I think it is not completely easy to understand them. One of the examples was about the electricity demand and it is somehow understandable why the electricity demand is different in summer and winter (two snippets). Since I am an electrical engineer, I might be a little biased. I think we can leave it as it is. In the future, some of the users might come forward and share their stories and provide a nice example for the application of this algorithm. |
Sounds good. This PR is focused on adding the Introduction so we'll continue to work on this tutorial until it is ready. The unit tests look great! The naive implementation isn't "naive" enough for my liking (i.e., it is too similar to the original code) and so I'm going to adjust it after the PR is merged. Thanks again for working on this and please look out for the next release v1.9.0 coming out really soon! I really appreciate all of your contributions @ninimama and I have enjoyed collaborating with you! |
|
@seanlaw
I will definitely check it out later to see the changes and learn more from you! |
|
@ninimama I made some changes/corrections to some of these files in this commit |
Corresponding to Issue #374
Pull Request Checklist
Below is a simple checklist but please do not hesitate to ask for assistance!
black(i.e.,python -m pip install blackorconda install -c conda-forge black)flake8(i.e.,python -m pip install flake8orconda install -c conda-forge flake8)pytest-cov(i.e.,python -m pip install pytest-covorconda install -c conda-forge pytest-cov)black .in the root stumpy directoryflake8 .in the root stumpy directory./setup.sh && ./test.shin the root stumpy directory