
Presentation Google Slides
Dashboard click here

The objective of this project is to assist a financial institution in its decision to approve or deny credit card applications. A model was built to predict the probability of future defaults using personal information and data submitted by applicants.
The decision to approve a credit card application is mainly dependent on the personal and financial background of the applicant. Factors such as age, gender, income, employment status, credit history and other attributes all carry weight in the approval decision.
Credit analysis focused on recognizing, assessing and reducing the financial or other risks that could lead to losses for the bank.
There are two basic risk factors:
- Opportunity loss that results from not approving the good candidate
- Financial loss that results from by approving a non-credit worthy candidate.
It is very important to manage credit risks and handle challenges efficiently for credit decision as it can have adverse effects on credit management.
The current global economy is relatively precarious.
-
In the last year $24 trillion has been added to the global debt
-
A total record high of $281 trillion and debt-GDP ratio of over 355% (source Reuters London).
Financial institutions will be looking for ways to minimize the risks associated with the many sectors they are involved in.
- The credit card charge-off rates have increased to 3.76% compared to 0.93% for other consumer credit products (source Federal Reserve reports).
Credit cards being one of the major income segments for banks, new models that help these institutions mitigate the risks involved in extending credit to their clients will be very sought after.
To minimize its losses, the financial institution has a responsibility to control and objectively quantify the magnitude of risk and credit card issuance.
The primary objective of this analysis is to design a Machine Learning model to be used on a credit card applicant dataset.
Following the results and information derived from the different models, recommendations will be provided so the financial institution can make better informed decisions.
-
Description of data source
This dataset, from kaggle, has been selected for its high ratings of usability, votes and credits.
The dataset includes a mix of binary, categorical and continuous features.
-
The Dataset contains two files:
-
Demographics & application data - "application_record.csv"
This data is provided by the applicants at the time of the credit card application.
It contains socio-economic and demographic information including gender, car & real estate ownership, income level, education, occupation, marital status, contact information.
application_record.csv Feature name Explanation Remarks/Variable Type ID Client number CODE_GENDER Gender Binary FLAG_OWN_CAR Is there a car Binary FLAG_OWN_REALTY Is there a property Binary CNT_CHILDREN Number of children Continuous AMT_INCOME_TOTAL Annual income Continuous NAME_INCOME_TYPE Income category Categorical NAME_EDUCATION_TYPE Education level Categorical NAME_FAMILY_STATUS Marital status Categorical NAME_HOUSING_TYPE Way of living Categorical DAYS_BIRTH Birthday Count backwards from current day (0), -1 means yesterday. / Continuous DAYS_EMPLOYED Start date of employment Count backwards from current day(0). If positive, it means the person currently unemployed. / Continuous FLAG_MOBIL Is there a mobile phone Binary FLAG_WORK_PHONE Is there a work phone Binary FLAG_PHONE Is there a phone Binary FLAG_EMAIL Is there an email Binary OCCUPATION_TYPE Occupation Categorical CNT_FAM_MEMBERS Family size Continuous -
Payment History data - "credit_record.csv"
Data showing payment experience and the date of the last data extraction.
credit_record.csv Feature name Explanation Remarks ID Client number MONTHS_BALANCE Record month The month of the extracted data is the starting point, backwards, 0 is the current month, -1 is the previous month, and so on / Continuous STATUS Status 0: 1-29 days past due1:30-59 days past due2:60-89 days overdue3:90-119 days overdue4:120-149 days overdue5:Overdue or bad debts, write-offs for more than 150 daysC:paid off that monthX:No loan for the month/ Categorical
-
-
Based on the dataset, what are the standard requirements for an individual to be approved for a credit card?
-
Can the model minimize the following risks?
-
Opportunity Loss from not approving the good applicant
-
Loss resulting from approving a non-credit worthy candidate
-
Preliminary data pre-processing must be completed before any analysis and/or machine learning models can be used on the dataset.
-
Determine "good" and "bad" applicants in the credit_records.csv file
As illustrated in the Overview of Dataset, the credit_record.csv contains information of all the applicants and their payment experience. The status of payment of the card holder's credit account from the starting month of their credit account until the current month is provided. From additional sources, credit card accounts are closed and sold to a collection agency when an account has not received payment for 3 or more months.
With this added information, determining how an applicant is deemed "good" or "bad" for credit card companies.
Applicants with 3 or more late payments (i.e. 3 times or more of "STATUS" of any 0-5) were classified as "bad" applicants, and any applicants who have less than 3 late payments as "good" applicants. The dataframe containing the modified status of applicants is under the name new_credit,
The process of the preliminary data pre-processing steps above are demonstrated in cells 13 to 22 of cleaning_and_preprocessing_data.ipynb.
-
-
Cleaning and encoding data
The next preliminary data preprocessing was to clean, encode, and rescale data from the application_record.csv file.
After converting the csv file to a dataframe, the first step of cleaning the aplication_record_df was to remove duplicate records and filling in null values. The .drop_duplicates() method was used to remove duplicates and filled in the null values in the "OCCUPATION_TYPE" column as "No Occupation Type".
Further encoding of gender, car ownership, owning realty, income category, education level, marital status, housing type, and occupation columns was done.
The annual income column was re-scaled by dividing the whole column by 10000 and new columns for age and employment period were created as they were initially counted in days and not years.
Features, such as 'days of birth', 'days of employment', 'FLAG_MOBIL', 'FLAG_WORK_PHONE', 'FLAG_PHONE', 'FLAG_EMAIL', 'Months_from_Today', 'MONTHS_BALANCE' and 'id' were dropped as they were not deemed important for predicting whether an applicants pay their credit cards or not.
The process of cleaning, and encoding of the application_record_df is demonstrated in the cells 24 to 55 of machine_learning.ipynb.
The two dataframes new_credit and application_record_df were merged to create the dataframe for the machine learning models, and export the merged dataset as a csv file from the PostgreSQL databse hosted on AWS RDS.
- The target variable ("STATUS_y") for this dataset is binary, i.e. approve (1) or not approve (0). Hence, the machine learning models used will be based on supervised binary classification models. Classification machine learning models such as Logistic Regression, Decision Trees, Random Forests, and Gradient Boosted Trees, will be applied to the data.
-
The data is in a PostgreSQL database hosted on AWS RDS. The two files making up the dataset will be merged in PostgreSQL and then integrated with the Jupyter Notebook file for machine learning using 3 different libraries.
-
These libraries are:
- ipython-sql
- SQLALCHEMY
- A python database API (DBAPI) library (i.e. psycopg2)
-
All the columns, except for the column "STATUS_y", from the pre-processed dataset were used as features to build the models.
-
The target variable was determined to be "STATUS_y".
-
The dataset was split into training and testing sets, 75% training and 25% testing.
-
The data was scaled using StandardScaler() for the features of the training and testing sets.
-
The process above is demonstrated in cells 12 to 17 of machine_learning.ipynb.
-
The next step is to feed the cleaned dataset into multiple Machine Learning models to find out which model is the best suited for the dataset.
-
The dataset is unbalanced and to address this, different sampling techniques will be used to balance the dataset.
-
Two oversampling techniques, Random Oversampling and Synthetic Minority Oversampling Technique (SMOTE) will be used for the first set of analyses.
-
The process above is demonstrated in cells 57-70 of machine_learning.ipynb.
-
The database for this project is a PostgreSQL database hosted in AWS RDS.
-
The database is created through pgAdmin and the structure and connections of the tables can be demonstrated in the PostGresDB_Draft.txt from the PostgreSQL_Database folder.
-
The machine learning model is connected as shown in the demo.ipynb file from the machine_learning folder.
-
The ERD diagram for our provisional database is also provided in the PostGreSQL_Database folder.


As illustrated above, Python in combination with multiple librairies and tools were used for the project.
Data Cleaning and Analysis
- Pandas and NumPy libraries in Jupyter notebook was used to clean data and perform exploratory analysis.
Database
- PostgreSQL was used to create the database tables and AWS RDS used for data storage.
Machine Learning
- Scikit-learn was the machine learning library used to create the Oversampling and Undersampling models.
Visualization
- Seaborn SNS is the library used to create graphics for the Confusion Matrices.
- Matplotlib is used for all other charts within the project.
Presentation and Dashboard
-
Google Slides have been used to walk the client through the methodologies used, the findings from the data set and commentaries about how the machine learning model will help the bank with its credit card application approval process.
-
A dashboard using JavaScript, HTML and CSS has been used for a live demonstration of the project's findings.
-
Flask and Pickle have also been used to demonstrate the interactivity of the model. The Pickle module has been used to enable applicants to input data in the model and have an instantaneous reply with regards to the application's status.
-
The dashboard is hosted on GitHub Pages.
Dashboard Display click here
-
The Confusion Matrix and their relative Metrics for each analysis (Logistic Regression, Decision Tree, Random Forest and Gradient Boosted Tree) for the oversampling undersampling and combination sampling techniques have been summarized in the tables below:
-
Oversampling results:

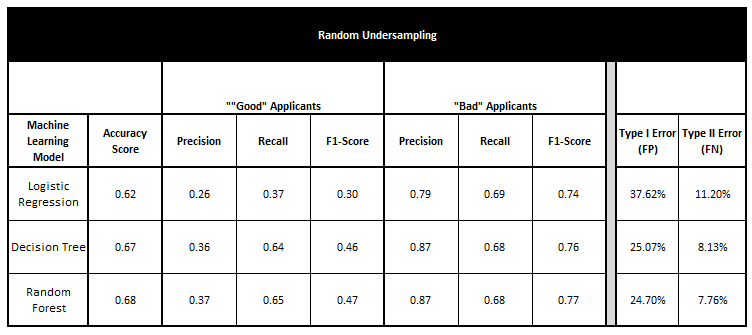
- Undersampling models yielded the following results:
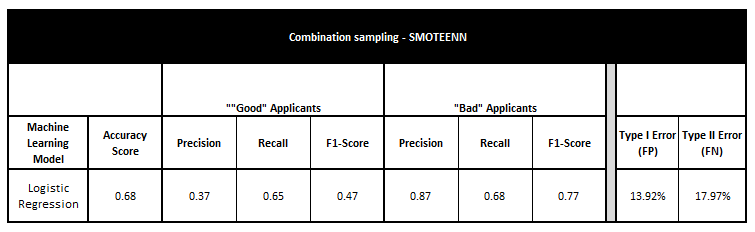
- Combination Sampling using SMOTEENN provided the following results when used on the same dataset:
Interpreting the Machine Learning Results
-
The tables above have a multitude of variables for what is deemed as "Good Applicants" and "Bad Applicants".
-
The Bank has 2 risks to mitigate for losses from its credit card applicants:
-
Loss by approving "bad" applicants - known as Type I error.
-
Opportunity Loss by denying "good" applicants - known as Type II error.
-
-
-
From the tables above, the Random Forest method under both the Random Oversampling and SMOTE techniques yielded the best results to help achieve the bank's risks mitigation goals.
-
The least probability of Type I error is from the SMOTE Oversampling Random Forest model (12.06%) with the Type II error being at 10.71%.
-
The metrics from the Confusion Metrics, presentated in the classiffication table also indicated the following:
Accuracy: overall measure of how ofteh the classifer is correct
Precision: when the model predicts "Good" applicant, how often is it really a "Good" applicant
Recall: when is is actually a "Good" applicant, how often does the model predicts it is a "Good" applicant
-
-
The SMOTE OVERSAMPLING Decision Tree model yields the best combination of the above metrics.
These results showcase the predictive accuracy of the model which will help the bank in its decision to approve or decline ab application.
- Use the SMOTE Oversampling Random Forest for the decision making process
- Use a live database to feed the model
- Collect more detailed and focused information from applicants
- Include updated credit bureau information in the datasets
- Expand the population size of the datasets
- Market other product types, i.e. prepaid credit cards, to "denied" applicants
- Use the findings from the analysis (features of "Good" applicants) for target marketing
Each team member's branch has been named as follows: "First_name_DeliverableN", where N stands for the deliverable number. Example for the first deliverable, "Binoy_Deliverable1"
- Binoy Luckoo's Branch Name: Binoy_DeliverableN
- Samir Rifi's Branch Name: samir_DeliverableN
- Jane Huang's Branch Name: jane_DeliverableN
- Lucas Chandra's Branch Name: lucas_DeliverableN