After quantization aware training, the inference time of the int8 tflite model is slower than float32 in the CPU #599
Description
Describe the bug
For the int8 tflite model created by quantization aware training, the inference time is very slow. I got the int8 and flaot32 tflite models by training example. And I run both on the TFLite Model Benchmark Tool. I found that the int8 tflite's average running time is 258.413 microseconds and float32 tflite's average running time is 41.7952 microseconds.
System information
TensorFlow version (installed from source or binary): tf-nightly(2.5.0-dev20201123)
TensorFlow Model Optimization version (installed from source or binary):0.5.0
Describe the expected behavior
the int8 tflite should run faster than float32 in the CPU.
Describe the current behavior
the int8 tflite runs much slower than float32 in the CPU.
Screenshots
Here is the result of the benchmark
For the float32,
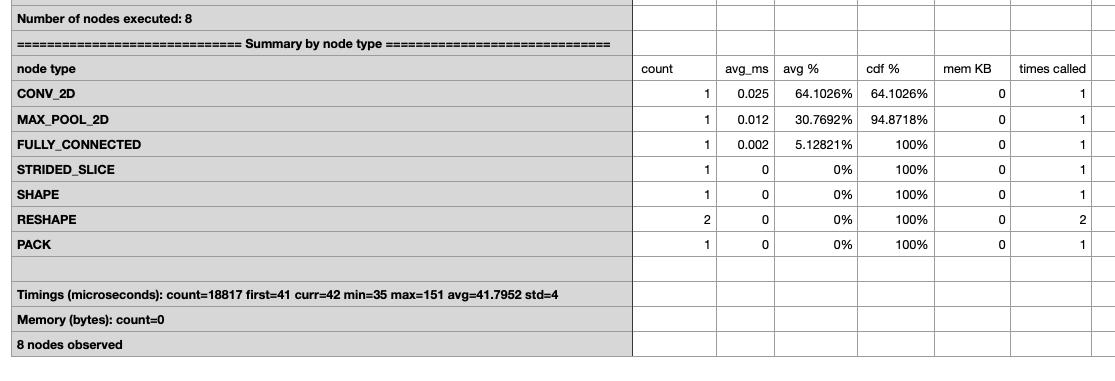
For the int8,
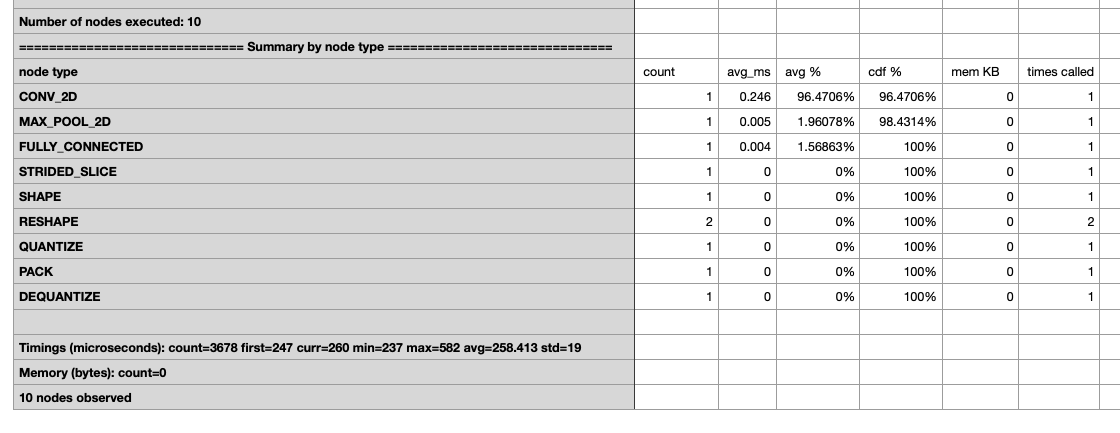
Additional context
I also found a similar situation for the MobileNetV1. The system I am using is macOS 10.15.7 with Intel Core i9-8950HK.