-
네이티브 개발환경
개발하는 시스템의 프로세서와 프로그램이 실행될 시스템의 프로세서가 같은 개발환경
-
크로스 컴파일 개발환경
-
임베디드 소프트웨어 개발환경은 개발하는 시스템의 프로세서와 실행될 시스템의 프로세서가 같지 않은 환경
-
생성되는 개발 환경을 다른 컴파일러를 사용해야 한다는 뜻이 된다.
-
즉 임베디드 소프트웨어를 개발하려면 다른 프로세서용 기계코드를 생성해주는 컴파일러가 필요하며 이를 크로스 컴파일러라 한다. (arm-linux-gcc, ADC 등)
-
크로스 컴파일러, 크로스 어셈블러, 링커/로케이터 등으로 구성된 소프트웨어 개발도구를 "툴체인"이라 한다.
-
-
입출력 장치 제어 방법
- 입출력 장치 제어 방법에는 두가지 방법이 있다.
-
메모리 맵
=> 입출력 장치들이 사용하는 메모리가 따로 정해져 있지 않아서 장치가 사용할 메모리를 개발자가 직접 지정하여 사용하는 방법
-
I/O 맵 방법
=> I/O는 입출력 장치들이 사용하는 메모리가 미리 정해져 있어서 지정된 메모리를 사용하는 방법
-
하드웨어 제어 동작 예시
LED 3000_0000번지의 5,6,7번 비트에 값을 쓰는 방법은 다음과 같다.
char *p = (char*)0x30000000; //5,6,7번 비트를 1로 set *p |= (0x1<<5) + (0x1<<6) + (0x1<<7); //5,6,7번 비트를 0으로 set *p &= ~((0x1<<5) + (0x1<<6) + (0x1<<7)); //특정 비트 반전 *p &^= 0x1<<5;
-
비트 연산을 통한 활용
어떤 수에 대한 값을 더했을 때 가장 가까운 4의 배수에 해당하는 수를 만드려면 어떻게 해야하는가
-
그냥 C code
start = 100; scanf("%d", &x); start += x; if((start % 4) == 1) start += 3; else if ((start % 4) == 2) start += 2; else if((start % 4) == 3) start += 1;
-
비트 연산을 사용한 C code
start = 100; scanf("%d", &x); start += x; start += 0x3; //1에서 3을 더해도, 2에서 3을 더해도, 3에서 3을 더해도, 4에서 3을 더해도 // 0bxxxxx...1xx 형태에 해당하는 비트 값을 가진다. start &= ~(0x3); // 0bxxxxx.....1xx & 0bxxxxxxx...100 의 값은 0b100이 되기에 4의 배수에 해당하는 값이 된다.
-
-
비트 연산을 활용한 매크로 정리
-
한 비트 클리어(예> 5번 비트)
a &= ~(0x1<<5); -
연속된 여러 비트 클리어(예> 5,4,3,번 비트)
a &= ~(0x7<<3); -
떨어져 있는 여러 비트 클리어 (예> 5,3,2번 비트)
a &= ~((0x1<<5) + (0x3<<2)); -
한 비트 설정(예> 5번 비트)
a |= (0x1<<5); -
연속된 여러 비트 설정 (예> 5, 4, 3번 비트)
a |= (0x7<<3); -
떨어져 있는 여러 비트 설정 (예> 5,3,2번 비트)
a |= (0x1<<5) + (0x3<<2); -
한 비트 반전
a ^= (0x1<<5); -
연속된 여러 비트 반전
a ^= (0x7<<3); -
떨어져 있는 여러 비트 반전 (예> 5, 4, 3번 비트)
a ^= (0x1<<5) + (0x3<<2); -
비트 검사 (예> 5번 비트)
a & (0x1 <<5); -
비트 추출 (예 > 6, 5, 4번 비트)
b = (a>>4) & 0x7;
-
-
비트 연산은 보통 매크로를 통해 구현하는 것이 가장 좋은 방식이다. (매크로의 경우 가로를 쳐야만 개발자가 의도한 코드 대로 동작된다.)
//한 비트 클리어 #define clear_bit(data, loc) ((data) &= ~(0x1<<(loc))) //연속된 여러 비트 클리어 #define clear_bits(data, area, loc) ((data) &= ~((area)<<(loc))) //한 비트 설정 #define set_bit(data, loc) ((data) |= (0x1<<loc))) //한 비트 반전 #define invert_bit(data, loc) ((data) ^= (0x1<<(loc)))
-
임베디드 환경에서는 메모리 직접 접근이 가능하다. 아래와 같은 방식이 포인터 배열을 선언해서 할당 한 뒤 매번 접근하는 것 보다 빠르게 활성화 할 수 있다.
//LED의 주소 값이 0x30000000이며 해당 주소에 100을 넣으려면 *(volatile unsigned int*)0x30000000 = 100; //과 같이 정의할 수 있다. 하지만 근본적으로 매번 이렇게 접근할 수 없으므로 보통은 아래와 같이 전처리기를 사용한다. #define PA *(volatile unsigned int*)0x30000000 = 100 void init(void){ PA |= (0x7 << 5); }
-
임베디드 환경에서는 Switch를 기반으로한 코드는 메모리 접근 내역에서 좋지 않다. 따라서 다음과 같이 정의해 주는 것이 좋다.
- 임베디드 시스템에서 사용되는 메모리는 HDD 없이 ROM, RAM으로 구성되어 있어서 실행코드를 최소화하거나, 작업 공간을 최소화하는 방법으로 효율적으로 사용해야 한다.
//올바르지 않은 예 void display(int digit){ switch(digit){ case 1: PA &= ~(0x1 << 5); break; case 2 : PA &= ~(0x2 << 5); break; } }
void display(int digit){ //들어온 이진수의 일의 자리가 1이면 LED3을 ON 아니면 Off (digit & 0x1) ? (PA &= ~(0x1 << 5) ) : (PA |= (0x1 << 5) ); //들어온 이진수의 십의 자리가 1이면 LED2를 ON 아니면 Off (digit & 0x2) ? (PA &= ~(0x1 << 6) ) : (PA |= (0x1 << 6) ); //들어온 이진수의 백의 자리가 1이면 LED1를 ON 아니면 Off (digit & 0x4) ? (PA &= ~(0x1 << 7) ) : (PA |= (0x1 << 7) ); }
-
volatile의 기능적 의미는 캐시사용안함(no-cache)이다.보통 프로그램이 실행될 때 속도를 위해 필요한 데이터를 메모리에서 직접 읽어오지 않고 캐시로부터 읽어온다. 하지만, 하드웨어에 의해서 변경되는 값들은 캐시에 즉각적으로 반영되지 않으므로 데이터를 캐시로부터 읽어오지 말고 주 메모리에서 직접 읽어오도록 해야한다. 이러한 특성 때문에 하드웨어가 사용하는 메모리는 volatile로 선언해야 하드웨어에 의해 변경된 값들이 프로그램에 제대로 반영된다.
- 추가적으로 volatile은 캐시를 사용하지 않는 특성 외에 컴파일러 최적화가 임의로 코드를 변경하는 것을 막을 수 있기 때문이다.
-
volatile의 추가적인 기능은 컴파일러가 main에서 호출되지 않는 함수나 delay를 위한 BusyWaiting 코드의 생략을 막을 수 있다.int time; //하드웨어에 의해 호출되고 메인에는 없는 코드 void interrupt_handler(void){ time++; } //비프음이 들리지 않는다. //왜냐하면 컴파일러 입장에서 main에는 호출될 일 없는 interrupt_handler 함수는 최적화 대상이기 때문에 삭제시킨다. //따라서 int time;을 volatile int time;으로 선언해야 개선이 가능하다. //또한 busy waiting을 통해 1초를 기다리는 for문 역시도 컴파일러 입장에서는 연산만하고 내부가 아무것도 수행되지 않는 문이므로 초기화 대상이다. //따라서 volatile int j = 0;으로 선언해야 원하는 데로 수행된다. void main(){ time = 0; int j = 0; while(1){ if((time%10) == 0 && time != 0) beep(); for(j = 0; j < 100000; j++); } }
-
데이터 구조의 영역을 먼저 이해하는게 좋다.
-
main()이 호출되는 과정은 OS의 유무에 따라 두 가지로 나눌 수 있다.
- OS의 유(리눅스)
- 쉘에서 프로그램 수행 : ./test
- fork로 새로운 프로세스 복사
- execve() 호출(시스템 콜) -> sys_execve() 호출(사용자 모드에서 커널 모드로 전환)
- do_execve() -> open_exec()가 파일 정보를 읽어 들여 적합한 binary handler를 실행
- flush_old_exec()가 기존 프로세스 정보를 삭제하고, 현재 프로세스를 "current"로 설정
- 새로운 프로세스에서 사용할 메모리 레이아웃 설정. text, data, bss, stack 등의 세그먼트를 선형 메모리에 맵핑
- 독적 링커 메모리에 로딩, elf 포맷이면 load_elf_interp()가 /lib/ld_linux.so.2를 메모리에 로딩
- start_thread() -> elf 인터프리터(elf_interpreter) 실행
- sys_execve() 종료(커널 모드에서 사용자 모드 전환)
- reschedule() / 문맥교환
- _start 코드에 의해 main() 호출
- OS 무
- 하드웨어에 대한 초기화나 클록 설정 등은 부트 코드에서 처리, C 프로그램이 작동될 수 있는 환경을 만들어 주는 과정은 스타트업 코드에서 처리한다.
-
인터럽트 사용불가(disable)로 설정한다.(와치독도 마찬가지. 스타트업 코드 실행 중에 인터럽트 발생시 어떤 일이 발생할 지 모름)
-
Rw_data를 ROM 에서 RAM으로 복사(data 세그먼트 복사. 보통 임베디드 시스템에서 실행 파일은 ROM에 저장되는데 data 세그먼트는 초기화된 전역 변수가 저장되는 곳으로 프로그램이 실행될 때 값이 변할 수 있다.)
보통 임베디드 시스템에서 실행 파일은 ROM에 저장되는데 data 세그먼트는 초기화된 전역 변수가 저장되는 곳으로 프로그램이 실행될 때 값이 변할 수 있다. 그러므로 이러한 값의 변동을 적용시키려면 RAM으로 복사해서 RAM에 있는 전역 데이터를 사용해야 한다.이 때 초기화되지 않은 전역 변수가 저장된 bss 세그먼트를 0으로 초기화한다. 이 과정 때문에 초기화 되지 않은 전역 변수는 0으로 초기화되는 것이다. -
ZI(bss)영역을 0으로 클리어
-
모드별 stack 생성
-
힙 생성
-
인터럽트 사용가능(enable)으로 설정
-
main() 호출
-
메모리에 대해 직접 접근은 포인터를 통해서만 가능하다?
아니다. 위에도 나와 있듯이 직접 메모리 접근도 가능하다.
*(volatile unsigned int*)0x30000000 = 100;
-
포인터와 포인터 연산은 +만 가능하다?
아니다. 오히려 +, - 둘 다 가능하지만 +의 경우 컴파일러가 protect 시키는 경우가 더 많다.
int *p, *q; p = 104; q = 100;
일 경우 가능한 것은
정수와의 +, - 단항 연산 포인터 - 포인터 대입 비교 p+1; p-1; p++; p--; p - q; p = q; if(p > q){} 불가능한 것은
실수와 +, - 정수와 *,/ 포인터끼리 +,*,/ p + 3.1; p - 3.1; p + q; p * q; p / q; -
배열의 이름은 포인터이다?
배열의 이름은 포인터가 아니다!
포인터의 특성은 값이 바뀔 수 있어야 하는데, 배열 이름은 상수이기 때문에 값이 바뀌지 않는다. 마찬가지로 &i도 주소를 나타내기는 하지만 포인터는 아니다. 배열 이름과 &i는 주소를 저장하거나 변경할 수 없기 때문이다.
만약 같다면, 아래와 같은 코드는 오류가 날 이유가 없다.
int a[] = {1,2,3}; int c = 100; int *b = &c; a = b;
-
a[] 배열의 a와 &a는 같은 의미이다?
a는 배열의 첫 요소에 대한 주소를 나타낸다. 그래서 한 단위는 배열 한 칸을 의미한다. &a는 배열의 시작 주소를 나타내며, 한 단위는 배열 전체가 된다.
실 주소 값의 표현 0x100 a[0] == *a 0x104 a[1] == *(a+1) 0x108 a[2] == *(a+2) 위의 표에서
- a, &a의 값은 각각 얼마인가? => 0x100, 0x100
- a+1, &a + 1의 값은 각각 얼마인가? => 0x104, 0x10c
-
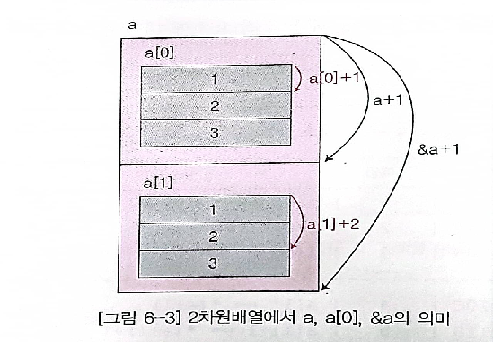
2차원 배열의 경우 다음과 같은 특징이 있다.
-
2차원
a[2][3] = { {1,2,3}, {4,5,6} };에서 a, &a. a[0] 의 값이 어떻게 되는지는 상단의 그림과 같다. -
이를 근거로 아래와 같은 질문을 생각해보면 다음과 같다.
- a[0], a[0] + 1의 값은?
- a, a + 1의 값은?
- &a, &a + 1의 값은?
위의 그림을 보면 a라는 큰 배열 안에 a[0], a[1]이라는 작은 배열이 있다. 여기서 a[1][0]의 주소는 a[1]이라는 것을 알 수 있고, a[0][0]의 주소는 a[0]이라는 것을 알 수 있다. 그렇다면, a[0][1]을 포인터로 표현하면 어떻게 되는가. => a[0][0]의 주소에서 한 칸 이동한 것과 같다. a[0][0]는 a[0]의 주소와 같으며, a[0]에서 한칸 이동한 a[0] + 1이 a[0][1]의 주소이다. 따라서, a[0][1]의 주소의 값을 접근하려면 *(a[0] + 1)이 된다. 이 중에서 a[0]의 값은 a가 가지는 주소의 값에 해당하므로 *(*a + 1)이 a[0][1]과 같다.
정리하면 다음과 같다.
a[0] = 0x100, a[0] + 1 = 0x104
a = 0x100, a + 1 = 0x10C
&a = 0x100, &a + 1 = 0x118
이를 근거로 하면 더 신기한 내용도 찾을 수 있다. 예를 들면 배열의 첨자를 음수로 하여
a[1][-1]이라는 수도 내역을 찾을 수 있다.배열의 음수 값은 그만큼의 이전 수를 나타내기 때문에 배열 사이즈를 정확히 안다면 사용해서 접근도 가능하다.
a[1][-1]는a[1][0]의 전 주소인a[0][2]를 참조하게 된다.#include <stdio.h> void main(){ int a[2][3] = { {1,2,3}, {4,5,6} }; printf("a[1][-1] = %d", a[1][-1]); //3이 출력된다. }
-
-
변수 이름을 기준으로 해서 가장 가까이 있고, 변수의 뒤에 있는 표현부터 해석 (가장 가까이 있는 뒤의 수식부터 해석해야 한다.)
int (*p[3])(int);를 해석해보면 다음과 같다.p를 기준으로 보면 가장 가깝게 변수의 뒤에 있는 표현부터 해석하면 [3]이라는 내역이므로 p는 배열임을 알 수 있다.
#include <stdio.h> void main(){ char a[] = "rose"; char *p = "grace"; a[0] = 'n'; p[0] = 't'; printf("a = %s\n", a); printf("p = %s\n", p); }=> 위의 코드에서 배열에 저장된 문제는 오류 없이 출력되지만, p에 대한 출력은 오류가 나거나 원하는데로 동작되지 않을 것이다.
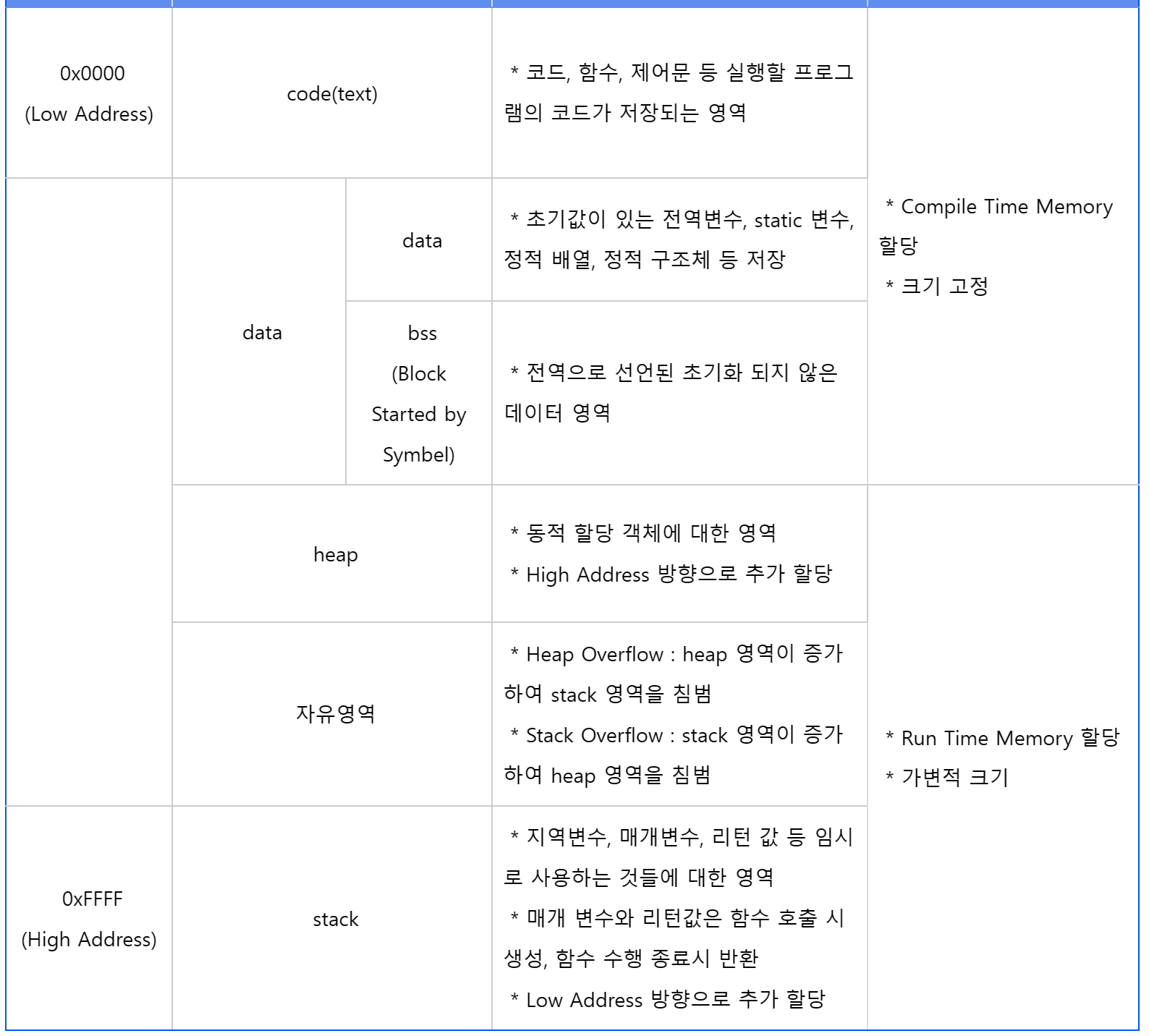
C 프로그램에서 사용하는 데이터는 종류에 따라 저장되는 위치가 달라진다. 텍스트 영역에는 프로그램 코드와 상수가 저장되며, 데이터 영역에는 정적(static) 변수와 전역 변수가 저장된다. 그리고, 스택은 함수가 사용하는 메모리로, 지역 변수나 함수의 인자, 리턴 값 등이 저장된다. 힙 영역은 malloc()과 같은 함수로 메모리를 할당 받아 사용할 수 있으며, 포인터로만 접근이 가능한 메모리이다.
-
텍스트 문자열을 배열에 넣는 것과 포인터의 넣는 것의 차이는 다음과 같다.
보통 C언어의 메모리 영역에서 "rose", "grace"와 같이 텍스트로 선언한 것은 텍스트 메모리에 저장되며 해당 메모리는 수정이 불가능하다.
이 때 배열을 선언한 뒤 텍스트 메모리의 것을 저장하게 된다면 배열 하나하나에 텍스트 원소가 복사되어 넣어지는 것이기 때문에 다른 메모리에 할당된다. => 즉, 수정이 가능하다.
하지만 포인터로 선언하는 것은 텍스트 메모리의 주소를 직접 확인하여 넣는 것이다. => 즉, 텍스트 메모리를 접근하여 수정하게 됨으로 수정이 불가능하며 오류가 발생하거나, 그대로 참조된다.
-
printf에 넣는 "%s" 나 "%d\n"도 텍스트 메모리 중 일부이다.
따라서 다음과 같은 코드도 사용 가능하다.
#include <stdio.h> void error_print(int x); void main(void){ int a, i; char b[3][10] = {"test1","test2","test3"}; char *p = "%s\n"; for(i=0; i<3; i++) printf(p, b[i]); printf(p, "1~4사이의 숫자를 입력하시오"); scanf("%d", &a); error_print(a); } void error_print(int x){ char *a[5] = {"error number : %s\n", "200", "300", "400", "500"}; printf(a[0], a[x]); }
-
void 포인터는 데이터 타입이 없는 포인터를 말한다. 따라서 void 포인터는 저장은 가능하지만 연산에 사용할 수는 없다. 하지만, 모든 주소를 저장할 수 있다는 장점을 가지고 있다.
-
하나의 프로세서의 주소는 32비트로 표현된다. 따라서 4바이트가 동일하게 사용된다.
-
그러나 데이터 타입이 지정되지 않아 증감, 데이터의 시작 주소로부터 몇 바이트를 읽어와야 할지 결정하지 못한다.
#include <stdio.h> void add(void *p, void *q, void *s, int op); void main(void){ int a = 1, b = 2, sum_i; float x = 1.5, y = 2.5, sum_f; add(&a, &b, &sum_i, 1); printf("int의 합 = %d\n", sum_i); //int의 합 = 3 } void add(void *p, void *q, void *s, int op){ if(op == 1) *(int*)s = *(int*)p + *(int*)q; //void 포인터는 연산 시 캐스팅 else if(op == 2) *(float*)s = *(float*)p + *(float*)q; }
-
malloc 함수의 return 값 역시 void 형 포인터이다.
void* malloc(size_t size);malloc() 함수는 할당한 메모리가 어떠한 타입으로 사용될지 모른다. 만약 메모리를 할당해주는 함수가 데이터 타입이 지정되어 있다면, C에서 사용하는 데이터 타입에 대응하는 메모리 할당함수들을 모두 만들어 주어야 한다. 그래서 데이터 타입이 지정되지 않은 void 포인터를 반환하는 것이다. 대신 이 포인터를 사용하려면, 꼭 원래의 데이터 타입으로 캐스팅해서 사용해야 한다.
int *p = (int*)malloc(sizeof(int) * 10);
-
임베디드 환경에서는 디바이스의 종류별로 함수를 다르게 호출하는 경우가 많아서 함수 포인터의 사용이 빈번하므로 확실히 이해해야한다.
-
함수 이름도 다른 포인터와 같이 함수가 사용하는 메모리의 시작 주소를 갖는 상수이다.
#include <stdio.h> void test(char* str); void main(void){ void(*p)(char*); char a[] = "함수 포인터 테스트"; p = test; p(a); } void test(char* str){ printf("\n%s\n", str); //함수포인터 테스트 }
-
Switch 문을 활용해서 함수 포인터를 배열 자체에 넣어서 선언할 수도 있다.
#include <stdio.h> int a(int); int b(int); int c(int); int (*p[3])(int) = {a,b,c}; void main(void){ int i; int z; scanf("%d", &i); z = p[i-1](4); printF("%d\n", z); } int a(int k){ return k*k; } int b(int k){ return k*k*k; } int c(int k){ return k*k*k*k; }
-
C언어는 고급언어이기 때문에 컴파일러가 바로 이해하기는 어렵다. 따라서 C언어 => 어셈블러 => 기계어로 변환해 주는데
기계어도 쉽게 이해하고, 개발자도 바로 이해할 수 있는 중간단계의 언어가 어셈블러이다.
test.c 코드가 전처리기를 통해 test.i로 변환하고 컴파일러를 거쳐 test.s로 변환된 뒤 어셈블러를 거쳐 test.o로 변환되고, 링커를
마지막으로 거리면 실행파일인 test로 생성된다.
-
오브젝트 파일
오브젝트 파일은 PE(Portable Executable), COFF(Common Object File Format), ELF(Executable and Linking Format) 등 다양하며, 이중 PE 포맷은 윈도우에서 사용되고, ELF 포맷은 유닉스, 리눅스, 솔라리스에서 사용된다.
-
오브젝트 파일은 세가지 타입이 있다.
-
재배치 가능 파일 : 코드와 데이터로 이루어져 있고, 다른 오브젝트 파일들과 결합하여 실행 가능 파일이나 공유 오브젝트 파일을 생성한다.
-
실행 가능 파일 : 실행 가능한 프로그램을 가지고 있다.
-
공유 오브젝트 파일 : 코드와 데이터로 이루어져있다. 재배치 가능한 오브젝트 파일로 프로그램 실행 시 동적으로 로드 및 링킹되는 파일이다.
-
-
실행 가능 파일을 제외한 재배치 가능 파일, 공유 오브젝트 파일은 완벽한 파일이 아니기 때문에 또 다른 과정을 거쳐야 한다.
-
-
링킹
- 링킹이란 여러 개로 나눠진 오브젝트 파일들을 하나로 합치는 역할을 한다.
- 여러 오브젝트 파일들의 코드는 text 섹션에, 초기화된 전역 변수와 정적 변수는 data 섹션에, 초기화되지 않은 전역 변수와 정적 변수는 bss 섹션으로 묶여져 하나의 파일을 이룬다.
-
재배치
- 재배치는 심볼 정의와 심볼 참조를 연결하는 과정이다.
-
로딩
- 실행 가능한 오브젝트 파일이나 공유 오브젝트 파일은 정적 프로그램이다. 정적 프로그램이 실행되려면 시스템이 이 파일들을 이용해서 동적으로 표현된 프로그램이나 프로세스 이미지를 만들어야 한다.
//값에 의한 호출
#include <stdio.h>
void f1(struct Test x);
struct Test{
int a;
float b;
char c;
};
void main(){
struct Test t1;
t1.a = 3;
t1.b = 5.5;
t1.c = 'x';
f1(t1);
}
void f1(struct Test x){
printf("%d, %f, %c\n", x.a, x.b, x.c);
}//참조에 의한 호출
#include <stdio.h>
void f1(struct Test *x);
struct Test{
int a;
float b;
char c;
};
void main(){
struct Test t1, *p;
p = &t1;
t1.a = 3;
t1.b = 5.5;
t1.c = 'x';
f1(p);
}
void f1(struct Test *x){
printf("%d, %f, %c\n", x->a, x->b, x->c);
}- 물론 위와 같이 직접 포인터를 통해 접근하는 코드를 통해 데이터를 변경시킬 수 있는 위험성도 제공된다.
- 하지만 const 키워드 하나를 통해 값의 접근을 제한하는 방법을 주로 사용한다.
- 구조체 자체는 그대로 선언하고 포인터 할당시에 const를 할당하여 캐스팅해주는 방법이다.
#include <stdio.h>
void f1(const struct Test *x);
struct Test{
int a;
float b;
char c;
};
void main(){
struct Test t1, *p;
p = &t1;
f1(p);
}
void f1(const struct Test *x){
printf("%d, %f, %c\n", x->a, x->b, x->c);
}#include <stdio.h>
struct sample{ //구조체 sample 정의
char a[10];
int b;
float c;
}f[3] = { //구조체 배열선언 및 초기화
{"test1", 10,10.5},
{"test2", 20, 20.5},
{"test3", 30, 30.5}
};
int add(int,int);
// 인자 테스트에 사용할 함수들의 프로토타입
void arg_arr_test(int*);
void arg_str_test(char*);
void arg_stru_test(struct sample*);
void arg_func_test(int(*) (int, int));
void main(void){
int d[] ={1, 2, 3, 4, 5, 6, 7, 8, 9, 10};
char *e = "hello";
arg_arr_test(d);
arg_str_test(e);
arg_stru_test(f);
arg_func_test((int(*)(int,int))add);
}
void arg_arr_test(int *x){
int i;
for(i=0; i<10; i++)
printf("d[%d] = %d\t", i, x[i]);
printf("\n");
}
void arg_str_test(char *x){
printf("e=%s\n", x);
}
void arg_stru_test(struct sample *x){
int i;
for(i=0; i<3; i++)
printf("%d번째 : %s %d %f\n", i, x[i].a, x[i].b, x[i].c);
}
void arg_func_test(int (*x)(int,int)){
int a = 10, b = 10;
printf("add 함수결과 : %d\n", x(a,b));
}
int add(int x, int y){
return x+y;
}- 임베디드 환경에서는 malloc을 지원하는 컴파일러가 없을 가능성이 크다. 따라서 보통의 경우는 링크드리스트를 통해 구현하는 경우가 대부분이다.
- 구조체 포인터를 사용하다 보면 구조체 멤버의 멤버의 멤버에 접근하는 것처럼 포인터가 체인을 형성하는 일이 발생한다.
//포인터 체인의 발생 내역
struct Point {
int x, y, z;
};
struct Obj{
Point *p1, *d;
};
void draw(struct Obj *a){
a->p1->x = 0;
a->p1->y = 0;
a->p1->z = 0;
} struct Point{
int x, y, z;
};//포인터 체인 제거
struct Obj{
Point *p1, *d;
};
void draw(struct Obj *a){
struct Point *k = a->pl;
k -> x = 0;
k -> y = 0;
k -> z = 0;
}- 속도에서는 배열이, 메모리에서는 포인터가 효율적이다.
- 함수에서 인자의 크기가 큰 경우, 값을 복사해서 넘기는 것보다 포인터를 활용하는 것이 효과적이다.
- 힙 엑세스와 함수의 인자로 배열, 문자열, 함수를 전달할 때에는 포인터를 활용한다.
- 포인터 체인은 제거한다.
- 초기화되는 전역 변수와 정적 변수 => 데이터 세그먼트
- 초기화되지 않은 전역 변수와 정적 변수 => bss 세그먼트
- 지역 변수와 함수 인자 => 스택
- 레지스터 변수 => 레지스터
- 문자열과 상수 => 텍스트 세그먼트
- 데이터 세그먼트에 저장되며, 프로그램이 실행될 때 생성되고, 프로그램이 수명을 다할 때까지 유지된다.
- 물론 전역변수와 정적변수가 비슷한 부분이 많고, extern을 통해 외부 파일에서 접근이 사용 불가능하다 외에는 큰 차이점은 없다.
- 하지만 전역 변수의 성질을 갖는 지역 변수를 만들어 쓸 수 있다는 점이 있다.
- 정리하면 전역변수이지만 지역변수처럼 해당 scope 내에서만 접근이 가능하도록 설계가 되어 있다.
- 정적 지역 변수는 지역 변수처럼 동작하고, 정적 메모리에 저장되므로, 빠른 속도와 데이터의 은닉성을 보장한다.
#include <stdio.h>
int* func3(int* x);
void main(void){
int *a, i;
int b[] = {1,2,3,4,5,6,7,8,9,10};
a = func3(b);
printf("배열의 요소는 \n");
for(i = 0; i< 10; i++)
printf("%d\t", b[i]);
//또한 다른 함수가 해당 주소를 참조하지 않기 때문에 똑같이 sum을 출력하면 오류가 발생한다.
//따라서 sum을 다시 하나 만들어야 오류가 발생하지 않는다. (static의 접근 자체는 지역변수의 접근과 같다.)
int sum = INT_MAX;
//INT_MAX 출력됨.
printf("어디의 sum인가요? : %d", sum);
}
int* func3(int* x){
int i;
//아래와 같이 단순히 지역 변수 sum을 선언한 뒤 sum의 주소를 리턴하면 쓰레기 값을 참조하게 된다.
//int sum = 0;
//하지만 다음과 같이 static으로 접근하면 sum의 주소 값을 참조가 가능하다.
//또한 함수 내에서 선언된 static은 다른 함수에서 직접 접근할 수 없다.(이게 전역 변수와의 차이점이다.)
static int sum = 0;
for(i=0; i<10; i++){
sum += x[i];
}
return ∑
}- 두가지 용도로 사용된다.
- 전역 변수를 의미하는 키워드(보통 함수 바깥에 있으면 전역변수로 인식하기 때문에 굳이 extern 키워드를 쓰지않고 생략한다.)
- 다른 모듈의 전역 변수를 끌어다 쓰겠다는 의미이다.
- 지역 변수 또는 자동 변수라 하며, 스택에 저장된다.
- 선언된 블록이 실행될 때 동적으로 메모리 할당을 받고, 블록이 끝나면, 같이 생명을 다한다. 유효 범위에 가장 제약을 받는 변수이다.
#include <stdio.h>
void func4(void);
int a;
void main(void){
int a = 10;
{
int a = 500, b = 5;
printf("main의 블록 내에서 출력 : a = %d b = %d\n", a, b);
}
printf("블록외부에서 b = %d\n", b);
func4();
printf("func4의 지역 변수 c = %d\n", c);
printf("main의 블록 외부에서 출력 : a = %d\n", a);
}
void func4(void){
int c = 100;
printf("func4에서 출력 : a = %d c = %d\n", a, c);
}-
에러 결과로는 10번 줄 외에는 발생되지 않는다.
-
변수 a는 다음과 같은 이유로 발생되지 않는다.
a는 같은 이름으로 3번 선언하고 있다. 하나는 전역 변수이고 나머지 두 개는 지역 변수로, 이 중 하나는 main 함수 내에, 또 하나는 블록 내에서 선언하였다.
같은 메모리 영역 내에서는 같은 이름의 변수는 중복해서 선언할 수 없으나, 메모리 영역이 다른 경우에는 가능하다.
전역 변수는 데이터 세그먼트에, 지역 변수는 스택에 저장되며, 스택은 각 함수와 블록에 따로 할당된다.
같은 이름의 변수가 여러 개일 때 이들 중 하나가 선택되는 방법은, 가장 가까운 것, 즉 현재 실행되고 있는 블록이나 함수에서 선언된 것이 사용된다.
- 레지스터 변수는 말 그대로 레지스터에 저장되는 변수이며, 저장되는 메모리만 다를 뿐 작동은 지역 변수와 비슷하다.
- ROM, RAM, 레지스터 중 CPU에 가장 가까운 메모리는 레지스터이기 때문에 메모리 크기는 아주 작지만 메모리 중에서 가장 빠른 성능을 가진 메모리이다.
- 레지스터 변수는 주소가 없으므로 포인터가 없다. 만약 레지스터의 주소를 읽어오려고 하면, 레지스터를 스택에 복사한 후 스택의 주소를 넘겨주기 때문에 비효율적이다.
-
메모리를 절약하기 위해서 기존의 int형 자료를 모두 char나 short로 변경하면 괜찮을까 => 기존 네이티브 자료형은 int형이기 때문에 메모리는 절약할 수 있어도 성능면에서 문제가 발생된다.
-
각 프로세서는 가장 잘 다룰 수 있는 데이터 타입을 가지고 있으며, 이를 네이티브 데이터 타입이라고 한다.
네이티브 데이터 타입의 크기는 해당 마이크로프로세서의 한 워드 크기와 같으며, 한 워드의 크기는 레지스터 크기와 같고, 데이터 버스의 폭과 같다.
-
부동 소수점을 피하는 것이 좋다.
부동 소수점은 최악의 경우 정수 연산에 비해 수백 배까지 성능을 떨어뜨릴 수 있다. 그래서 고속 부동 소수점 연산을 지원하는 FPU(Floating Point Unit)을 사용하기도 하는데 프로세서에 따라서 이 유닛을 지원할 수도 있고 지원하지 않을 수도 있다.
-
전역 변수는 레지스터에 할당할 수 없으므로 함수나 루프에서 사용하지 않는 것이 좋다.
만약 함수나 루프에서 전역 변수를 써야 한다면, 지역 변수에 복사하여 사용하는 것이 좋다.
전역변수를 통한 메모리 접근은 외부 메모리 엑세스로 CPU 컴퓨팅보다 시간 소비가 크다.
//코드 자체는 짧지만 전역변수를 지속적으로 접근하게 된다. int global_var; void f1() { int i; for(i = 0; i < 100; i++){ if(f2()){ global_var++; } } }
int global_var; void f1(){ int i; int local_var = global_var; for(i = 0; i < 100; i++){ if(f2()){ local_var++; } } global_var = local_var; }
-
타입 한정자
타입 한정자에는 volatile 과 const가 있다.
- volatile은 예상치 못한 값의 변화에 대처하려고 사용한다.
- const의 경우 값의 변경을 금지하는 키워드로 const 한정자로 지정된 변수는 읽기 전용으로 처리된다.
-
Const 키워드는 위치에 따라서 역할이 조금씩 달라진다.
const int *p_a; int const *p_b; int * const p_c; int const * const p_d;
- 1,2 번은 서로 같은 의미이다.
- 3번의 경우는 const 앞에 포인터가 있으므로 주소 값을 변경할 수 없다.
- 4번의 경우는 const가 둘 다 있다. 즉, 주소도 변경할 수 없고, 값도 변경할 수 없다.
-
루프를 이용한 배열 접근
for(i=0 i<10; i++){ a[i] = i + 1; }
가장 가독성은 좋지만 효율에선 좋지 않다.
루프 변수 i의 접근과 반복 조건을 만족하는지 테스팅하는 비교 연산 및 변수의 증가가 반복적으로 수행되므로 루프에서 발생하는 오버헤드 떄문에 속도가 느려지기 때문이다.
-
인덱스 증감을 이용한 배열 접근
i = 0; a[i++] = k * PI; a[i++] = l * PI; a[i] = 3 * PI;
속도 면에서 아주 효과적
루프를 이용했을 때와 같은 반복적 오버헤드가 발생하지 않고, 주소의 오프셋만 계산되므로 비용을 훨씬 줄일 수 있다.
-
하드 코드 배열 접근
a[0] = k * PI; a[1] = l * PI; a[2] = 3 * PI;
가장 효과적인 접근
-
포인터를 이용한 배열 접근
int a[5], *p; p = a; *p = k * PI; *(p+1) = l * PI; *(p+2) = 3 * PI;
간접 접근 방식(포인터를 이용해서 배열에 접근하면 포인터 주소에 접근한 다음에 데이터에 접근하게 된다.)
하지만 메모리 엑세스가 두번 발생하기 떄문에 효율X, 코드를 이해하기 가독성이 좋지 않으며, 무엇보다 배열과 같이 인덱스를 사용하지 않기 때문에 메모리의 유효 범위 검사가 어렵다. 아래 예제를 보자
#include <stdio.h> void main(){ int i, a[5] = {1,2,3,4,5}; int *p = a; for(i = 0; i < 10; i++) printf("%d\t", p[i]); } //실행 결과 //1 2 3 4 5 5 1245120 4199017 1 4394608
위와 같이 배열 인덱스는 5까지 할당되지만 out of bound 관련 에러가 발생되지 않는다.
이로 인해 정상적인 오류를 발생시키지 않는다. 문제는 이 경우는 단순히 읽기이지만 만약 쓰기 명령어에 포인터로 접근한다면 더 큰 에러가 발생할 수 있으며, 임베디드 환경이라면 더욱 문제가 커질 가능성이 있다.
-
유니온은 구조체와 흡사하나 멤버들이 메모리를 공유한다는 특징이 있다.
union Test{ int x; char y[4]; }t1;
=> t1.x의 값을 4등분하여 y배열에 저장되어 있다. 즉, 4바이트의 int형 데이터의 값을 1바이트의 char형 4개로 만들어 접근이 가능하도록 만들었다.
-
유니온은 이렇게 데이터를 쪼개거나 데이터의 순서를 바꿔줄 떄 사용하면 유용하다.(엔디언의 변경 등)
0x12345678을 저장할 때 빅엔디안과 리틀엔디안은 다음과 같은 차이를 가진다.
빅 엔디안(RISC기반 컴퓨터들의 사용 방법으로 높은 자리수부터 먼저 저장한다.)
=> 0x100번지에 0x12, 0x101번지에 0x34, 0x102번지에 0x56, 0x103 번지에 0x78을 저장되어 0x103부터 0x100까지 78, 56, 34, 12 순으로 저장되어 있다.
리틀 엔디언(리틀 엔디언은 인텔 프로세서에서 사용되는 방법으로 낮은 자리수부터 저장한다.)
=> 0x100번지에 0x78, 0x101번지에 0x56, 0x102번지에 0x34, 0x103 번지에 0x12을 저장되어 0x103부터 0x100까지 12, 34, 56, 78 순으로 저장되어 있다.
문자열의 경우 빅엔디안, 리틀 엔디안 모두 동일하게 저장된다.
-
아래의 예시는 바이트 열의 순서를 바꾸기 위해 유니온을 사용한 예시이다.
union Test{ int x; char y[4]; }; void main(){ char buf[4]; int i; union Test t1; t1.x = 10; for(i=3; i>=0; i--){ buf[3-i] = t1.y[i]; } //바꾼 buf 값을 변경해서 보내기 send(buf); }
-
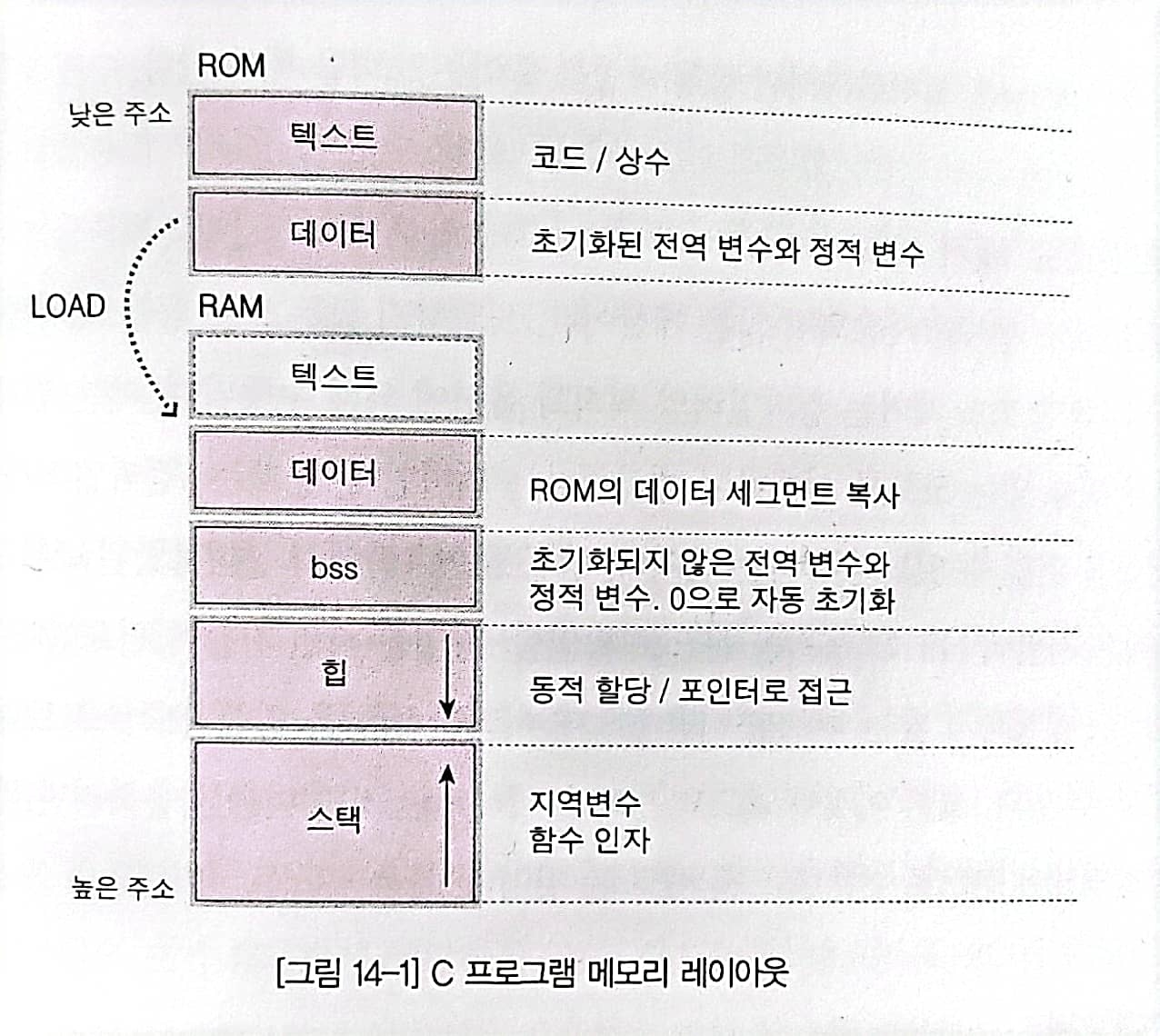
ROM
프로그램 코드와 상수, 초기화된 전역 변수와 정적 변수들
- Rom 영역에 저장된 요소들(코드 + 상수 + 초기화된 전역 변수)은 모두 하나의 실행 파일이다.
- 실행 파일을 HDD에 저장했다가, RAM으로 로딩하여 프로그램을 실행시킨다.
- 임베디드 환경에서는 HDD가 없다. 실행 파일을 ROM에 저장하고 런타임에 사용되는 나머지 섹션들은 RAM에 저장
- ROM을 최적화하기 위해선 실팽 파일을 줄여야한다.
-
RAM
ROM의 초기화된 전역 변수와 정적 변수들의 복사본, 초기화 되지 않은 전역 변수와 정적 변수, 지역 변수, 함수의 인자 및 함수 호출 시 발생하는 문맥(Context)
-
데드 코드 제거
데드 코드 제거란 사용되지 않는 계산이나, 도달하지 않는 코드 등을 제거하는 것
volatile로 선언하거나, 여러가지 방법이 있다.
-
매크로나 인라인을 사용하지 않는다.
속도 최적화에서는 분기가 성능을 감소 => 간단한 함수는 매크로나 인라인 함수로 대체하면 좋다.
크기 최적화에서는 코드 크기가 증가하기 때문에 좋지 않다.
-
전역 변수는 초기화하지 않는다.(ROM, RAM 모두에 저장된다.)
전역 변수나 정적 변수를 초기화하여 사용하면 ROM과 RAM, 두 메모리에 모두 저장된다.
-
만약 여기서 초기화를 안하면 bss 세그먼트에 저장된다.(RAM에 위치함)
-
bss 세그먼트는 초기화되지 않은 전역 변수와 정적 변수가 저장되며 자동으로 초기화된다.
=> 이 경우에는 스타트업 코드에서 초기화를 진행한다는 의미이며, 이 때문에 부팅속도가 늘 가능성은 있다.
-
-
상수나 전역 변수 대신 지역 변수 사용
전역 변수를 지역 변수로 대체하는 것도 ROM을 절약하는 한 방법이다.
마찬가지로 상수 역시 코드 크기를 늘리므로 변수로 대체한다.
-
표준 라이브러리 함수 자제
표준 라이브러리 함수들은 많은 조건들에 대비한 코드들이 많기 때문에 코드 증가가 증가하는 경향이 있다.
- 특히 임베디드 소프트웨어는 타겟 프로세서에 연결된 주변기기가 각 시스템마다 다르기 때문에 직접 만들어 사용하는 경우가 많다. (malloc 같은 경우는 직접 만들어 사용한다.)
-
RAM 최적화는 스택 최적화로 볼 수 있다.
-
함수 호출은 깊지 않게
함수의 작업 공간은 스택이므로 스택과 함수는 밀접한 관계가 있다. 함수에서 다른 함수를 호출하며느 새로운 함수가 사용할 메모리를 또 할당받아야 하고, 여기서 발생하는 문맥정보 또한 스택에 저장해야 하므로 메모리의 사용량이 늘어난다.
- 함수가 호출되면 가장 먼저 복귀 주소를 저장
- pc 레지스터에 분기 주소를 저장, 해당 함수로 분기하여 함수를 실행.
- 함수 실행 이전에 함수의 인자나 지역 변수를 저장하는 데 스택에 저장해야한다.
-
함수는 매크로나 인라인으로 대체
앞으로 살펴봤듯이 함수는 스택 사용량이 크다. 그래서 ROM은 넉넉하지만, RAM이 부족할 때는 함수 대신 매크로나 인라인을 사용해서 절약하는하다.
-
구조나 배열 대신 포인터 활용
구조체는 대부분 크기가 큰편이다. 함수의 인자나 리턴 값이 구조체일 때 값에 의한 호출이 아닌 참조에 의한 호출을 사용하는 것이 좋다.
-
비트 플래그 활용(구조체 비트 필드 => C 언어 코딩 도장: 56.1 구조체 비트 필드를 만들고 사용하기 (dojang.io))
비트 필드는 다음과 같이 사용 가능하다.
#include <stdio.h> struct Flags { unsigned int a : 1; // a는 1비트 크기 unsigned int b : 3; // b는 3비트 크기 unsigned int c : 7; // c는 7비트 크기 }; int main() { struct Flags f1; // 구조체 변수 선언 f1.a = 1; // 1: 0000 0001, 비트 1개 f1.b = 15; // 15: 0000 1111, 비트 4개 f1.c = 255; // 255: 1111 1111, 비트 8개 printf("%u\n", f1.a); // 1: 1, 비트 1개만 저장됨 => (실행결과 1) printf("%u\n", f1.b); // 7: 111, 비트 3개만 저장됨 => (실행결과 7) printf("%u\n", f1.c); // 127: 111 1111, 비트 7개만 저장됨 => (실행결과 127) return 0; }
현재의 프로그램 상태를 나타내는데 boolean 형태의 flag를 기반으로 사용할 때가 많다.
하지만 C에는 flag가 없기 때문에 보통 int형 변수를 사용한다.
#include <stdio.h> struct SR{ unsigned int CF : 1, PF : 1, AF : 1, ZF : 1, SF : 1, IF : 1, MOD : 4; }; void main(){ struct SR flag = {1,1,0,1,0,1,0xF}; if(flag.CF) printf("carry\n"); if(flag.PF) printf("parity\n"); if(flag.AF) printf("assistant carry\n"); if(flag.ZF) printf("zero\n"); }
-
값이 변하지 않는 전역 변수의 상수화
전역 변수를 초기화하면 ROM, RAM 모두에 저장된다. 그래서 값이 바뀌지 않는 전역 변수라면 const 키워드를 사용하여 상수화하는 것이 좋다.
전역 변수를 상수화 하면 RAM에 복사하는 것을 막을 수 있기 때문이다.
-
프로그램은 롬에서 실행
-
인라인 함수는 함수를 호출하는 대신 함수 코드를 호출 위치에 삽입하는 방법으로 gcc를 비롯한 대부분의 C컴파일러에서 인라인을 지원하며, 높은 레벨의 최적화에서는 작은 크기의 함수를 자동으로 인라인 처리하기도 한다.
-
분기를 하지 않기 때문에 속도를 높일 수 있지만, 코드를 직접 삽입하기 때문에 프로그램 크기가 커진다.
__inline int square(int x){ return x * x; } double add(int x, int y){ return (square(x) + square(y)); }
재귀 함수는 반복적인 처리를 짧은 코드와 효과적인 처리로 편의를 제공한다. 하지만, 함수의 반복적인 호출은 비용이 많이 들며, 이전 계산 결과가 필요한 재귀 함수는 성능을 굉장히 떨어뜨린다.
- 최적화를 위해서는 goto 문을 이용하여 재귀 호출을 제거하는 것이다.
int face(int x){
int i, result = 1;
if(x==0) return 1;
L1:
if(i <= x)
result *= i++;
else
return result;
goto L1;
}- 함수의 리턴 타입이 void가 아니면 함수에서 일을 수행한 결과를 리턴한다.
- ARM 마이크로프로세서는 r0 레지스터에 함수의 리턴 값을 저장한다. 그리고 함수 인자 일부는 레지스터에 저장된다.
- 만약 ARM 마이크로프로세서에서 인자가 4개를 넘을 때는 어떻게 될까?
int fool(int a, int b, int c, int d){
return a+b+c+d;
}
int foo2(int a, int b, int c, int d, int e, int f){
return a+b+c+d+e+f;
}
void main(){
int x,y;
x = foo1(1,2,3,4);
y = foo2(1,2,3,4,5,6);
}- 인자가 4개인 함수와 6개인 함수를 호출하였을 떄, 인자들이 어떻게 저장되는지를 살펴보기 위한 소스이다.
- 인자가 4개인 경우는 모두 레지스터에 저장되지만, 6개인 경우에는 앞의 4개만 레지스터 2개는 스택에 저장된다.
- 따라서 함수의 속도를 생각한다면 인자의 개수를 4개 이하로 주는 것이 좋다.
- 리프 함수는 함수내에서 다른 함수를 호출하지 않는 함수.
- 리프 함수는 다른 함수를 호출하지 않으므로 인자의 개수가 많아지고, 좀 복잡해질 수도 있지만, 이로 인한 오버헤드는 리프 함수의 이점에 비하면 작은 편이다.
- 그래서 가능하다면 프로그램의 함수들을 리프 함수들로 구성하는 것이 속도 향상을 위해서 좋다.
- 다중 분기문의 비교문에서 사용하는 연산은 한 번만 수행하고, 이를 변수에 저장하여 사용한다.
- 다중 분기문은 if 문 보다는 switch 문이 속도, 메모리 모두 효율적이다.
- 비교문과 같이 반복적으로 사용되는 데이터의 데이터 타입을 잘 선택해야 한다.
-
아래와 같이 이상한 코드를 보면 굳이 이렇게 짤 필요가 있나 싶지만 기계의 입장에서는 차이가 있다.
int i, j = 10; for(i = 0; i < 20; i++){ function(j); }
int i, j = 10; for(i = 0; i < 20; i += 4){ function(j); function(j); function(j); function(j); }
- for 문은 원하는 문장만 반복 수행하는 것이 아니라, 반복을 위한 연산 또한 지정된 횟수만큼 반복한다.
- 반복할 때마다 분기가 발생하는데 분기는 이미 준비된 파이프라인을 파괴하고, 다시 생성해야 하는 문제를 발생시키므로 속도의 효과 면에서는 좋은 방법이 아니다.
- && : 논리곱인 경우에 첫 비교문이 거짓이면 모두 거짓이므로 그 뒤의 비교문은 모두 수행하지 않는다.
- || : 논리합의 경우에는 첫 비교문이 참이면 모두 참이 되므로 그 뒤의 비교문은 모두 수행하지 않는다.
-
a = b / c + d / c;은a = (b + d) / c;로 변경이 가능하다. -
if( (a >=0 && a < 10) && (b >= 0 && b < 10) ) { f1(); } 은 if( (unsigned) (a | b) < 10 ){ f1(); }
-
if( (x==1) || (x==2) || (x==4) || (x==8) ){ f1(); } 은 if( x & (x-1) == 0 && x!=0 ){ f1(); }
-
실수의 나누기는 느리다. 따라서 나누기 연산을 상수를 이용한 곱의 형태로 바꾼는 등 다른 연산자를 이용하여 표현하는 것이 좋다.
x = x / 4.0; //상기 내용을 하기와 같이 변경할 수 있다. x = x * (1.0 / 4.0);
-
가능하면 double 대신 float를 사용하라.
double은 8바이트이기 때문에 메모리 엑세스가 늘어나며, 메모리 소비량도 늘어난다.
-
Math 라이브러리 함수를 되도록 사용하지 않는다.
Math 라이브러리 함수는 오버헤드가 크다. 자주 사용되는 연산의 값을 참조 테이블에 저장하는 방식이 빠르게 수행 가능하다.
-
고정 소수점으로 변환하여 연산하라.
FPU를 지원한다 하더라도 성능차이를 부동소수점에 비해 면할 수 없다. 주의 필요하다.