Keşifsel Veri Analizi
Merhaba arkadaşlar. Bu çalışmada EDA olarak bilinen Keşifsel Veri Analizinden bahsetmek istiyorum. Genel olarak veri keşfi aşaması, bir probleme ilişkin elde veriler arasında ki temel özelliklerin saptandığı, verinin daha anlaşılabilir olması amacıyla bazı veri görselleştirme yöntemlerinin kullanıldığı aşamadır. Aslında sadece makine öğrenmesi ve derin öğrenme uygulamalarının değil genel olarak veri ile ilgili her işlemin temelini oluşturmaktadır. Çünkü veri anlaşılamadan problem tespiti ve probleme yönelik yöntem belirlemek çok mümkün olmayacaktır. Şimdi birde sözlük tanımına bakalım.
Sözlük anlamıyla Keşifsel Veri Analizi, özet istatistikler ve grafik gösterimler yardımıyla kalıpları keşfetmek, anormallikleri tespit etmek, hipotezi test etmek ve varsayımları kontrol etmek için veriler üzerinde ilk araştırmaları gerçekleştirmenin kritik sürecini ifade eder.
Bu tanımlardan hareketle EDA’yı, eldeki verileri kirletmeden önce onları anlamlandırmak ile ilgilenilen aşama olarak tanımlayabiliriz.
EDA, öncelikle resmi modelleme veya hipotez testi görevinin ötesinde hangi verilerin ortaya çıkabileceğini görmek için kullanılır ve veri seti değişkenlerinin ve bunlar arasındaki ilişkilerin daha iyi anlaşılmasını sağlar. Ayrıca, veri analizi için düşündüğünüz istatistiksel tekniklerin uygun olup olmadığını belirlemenize yardımcı olabilir.
İlk olarak 1970'lerde Amerikalı matematikçi John Tukey tarafından geliştirilen EDA teknikleri, günümüzde veri keşfi sürecinde yaygın olarak kullanılan bir yöntem olmaya devam ediyor.
Veri biliminde keşifsel veri analizi neden önemlidir? EDA’nın temel amacı, herhangi bir varsayımda bulunmadan önce verilere dışarıdan bir gözle bakmaya yardımcı olmaktır. Bariz hataları tanımlamanın yanı sıra verilerdeki kalıpları daha iyi anlamaya, aykırı değerleri veya anormal olayları tespit etmeye, değişkenler arasında ilginç ilişkiler bulmaya yardımcı olabilir.
Keşif amaçlı veri analizi türleri nelerdir? Dört ana EDA türü vardır:
Univariate non-graphical(Grafiksel olmayan tek değişkenli): Bu tür, analiz edilen verilerin yalnızca bir değişkenden oluştuğu en basit veri analizi şeklidir. Tek bir değişken olduğu için nedenler veya ilişkilerle ilgilenmez. Tek değişkenli analizin temel amacı, verileri tanımlamak ve içinde var olan kalıpları bulmaktır.
Univariate graphical(Tek değişkenli grafik): Grafik olmayan yöntemler, verilerin tam bir resmini sağlamaz. Bu nedenle grafik yöntemler gereklidir. Yaygın tek değişkenli grafik türleri şunları içerir: Tüm veri değerlerini ve dağılımın şeklini gösteren gövde ve yaprak grafikleri, Histogramlar, her çubuğun bir değer aralığı için vakaların sıklığını (sayı) veya oranını (sayı/toplam sayı) temsil ettiği bir çubuk grafiği ve son olarak Minimum, birinci çeyrek, medyan, üçüncü çeyrek ve maksimumun beş sayılık özetini grafiksel olarak gösteren kutu çizimleri.
Multivariate nongraphical(Çok değişkenli grafiksel olmayan): Çok değişkenli veriler, birden fazla değişkenden kaynaklanır. Çok değişkenli grafiksel olmayan EDA teknikleri genellikle çapraz tablolama veya istatistik yoluyla verilerin iki veya daha fazla değişkeni arasındaki ilişkiyi gösterir. Multivariate graphical(Çok değişkenli grafik): Çok değişkenli veriler, iki veya daha fazla veri kümesi arasındaki ilişkileri görüntülemek için grafikleri kullanır. En çok kullanılan grafik, her grubun değişkenlerden birinin seviyesini temsil ettiği ve bir grup içindeki her çubuğun diğer değişkenin seviyelerini temsil ettiği gruplandırılmış bir çubuk grafik veya çubuk grafiktir.
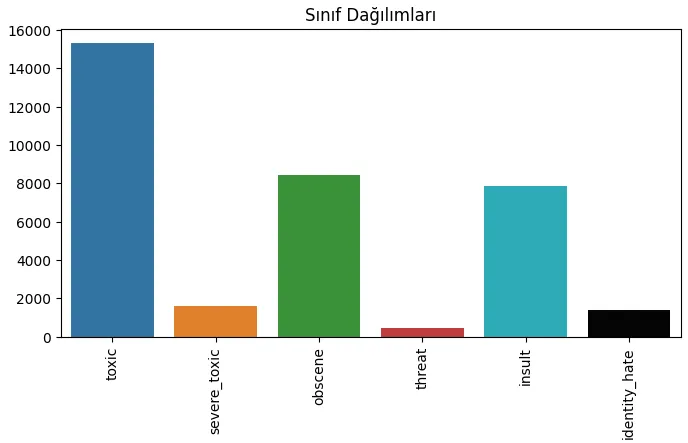
Burada kullanacağımız veri seti, NLP projeleri için çok popüler bir veri seti olan [Kaggle Toxic Comments Classification](https://github.com/tr-brain-com/acikhack2023TDDI/tree/main/data](https://www.kaggle.com/competitions/jigsaw-toxic-comment-classification-challenge)’dan gelmektedir. Burada gerçekleştireceğimiz şey, bu veri setinin özelliklerini keşfetmek ve bazı çıkarımlarda bulunmak olacaktır.
Burada veri görselleştirme için matplotlib, seaborn ve wordcloud kütüphanelerini kullanacağız. Bunları sisteminize kurun.
pip install matplotlib
pip install seaborn
pip install wordcloud
pip install scikit-learn