

A neural audio codec for expressive speech.
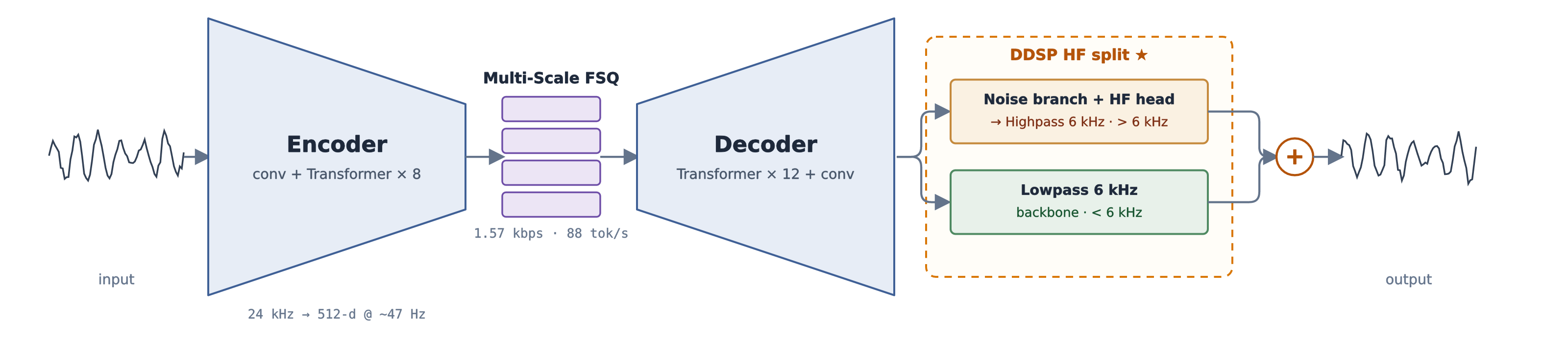
Spine encodes 24 kHz mono audio into multi-scale FSQ tokens at 1.57 kbps (~88 tokens/s) across four temporal scales (~6 / 12 / 23 / 47 Hz), keeping sequences short for downstream language models. The convolutional decoder is hard-bandlimited at 6 kHz by a fixed crossover; a filtered-noise branch and a complex-STFT head synthesize the high band under purely adversarial supervision, eliminating the high-frequency static typical of GAN codecs.
- 115M-parameter generator: conv encoder/decoder with a 512-d transformer bottleneck (8 + 12 layers)
- Multi-scale FSQ (
pool → quantize → repeat) on a shared latent, with no codebook collapse - Reconstruction losses bandlimited below the crossover; the high band is owned by the DDSP split
pip install spine-codecTraining pulls in extra dependencies (wandb):
pip install "spine-codec[train]"For development, clone this repo and run uv sync.
The pretrained model is downloaded from twangodev/spine-codec on first use; pass --checkpoint to use a local training checkpoint instead.
spine encode --input speech.wav --output codes.pt
spine decode --input codes.pt --output speech.wav
spine recon --input speech.wav --output roundtrip.wavimport torchaudio
from spine import Spine
model = Spine.from_pretrained("twangodev/spine-codec")
audio, sr = torchaudio.load("speech.wav") # 24 kHz mono
codes = model.encode(audio.unsqueeze(0))
reconstruction = model.decode(codes)spine train --config configs/train.yamlTraining configs live in the repo (not the wheel), so train from a git checkout
with the train extra installed.
YAML configs are sparse overrides on top of the defaults in spine/config.py.