Reproducing Inference times #6751
-
|
Hi all! Thank you @glenn-jocher for this fantastic repo! I'm looking at the inference speeds listed on the front page, and I cannot even get remotely the same results. I've ran v5n through v5x6 (10 models) on a Nvidia Tesla K80 on MS Azure and all my results are much worse. It should be unrelated to whatever lag Azure introduces since the time taking is the actual inference process, I think. I've also specified --device to 0 producing this "YOLOv5 🚀 v6.0-187-gf3085ac torch 1.8.1+cu102 CUDA:0 (Tesla K80, 11441MiB)" to verify the CUDA. I've ran with the detect.py and not val.py, if that makes any difference. The results I get are anywhere from 2x and all the way to 12x (increasing with params) worse than those reported with a V100 b1. Does anyone have any similar experiences, or even better any solutions to the problem? 😄 |
Beta Was this translation helpful? Give feedback.
Replies: 1 comment 3 replies
-
|
@henningscale a K80 is one of the slowest GPUs available, so you should expect slow results. Hardware to reproduce (AWS P3 instance with V100 GPU) is indicated in table notes, as well as commands to reproduce.
|
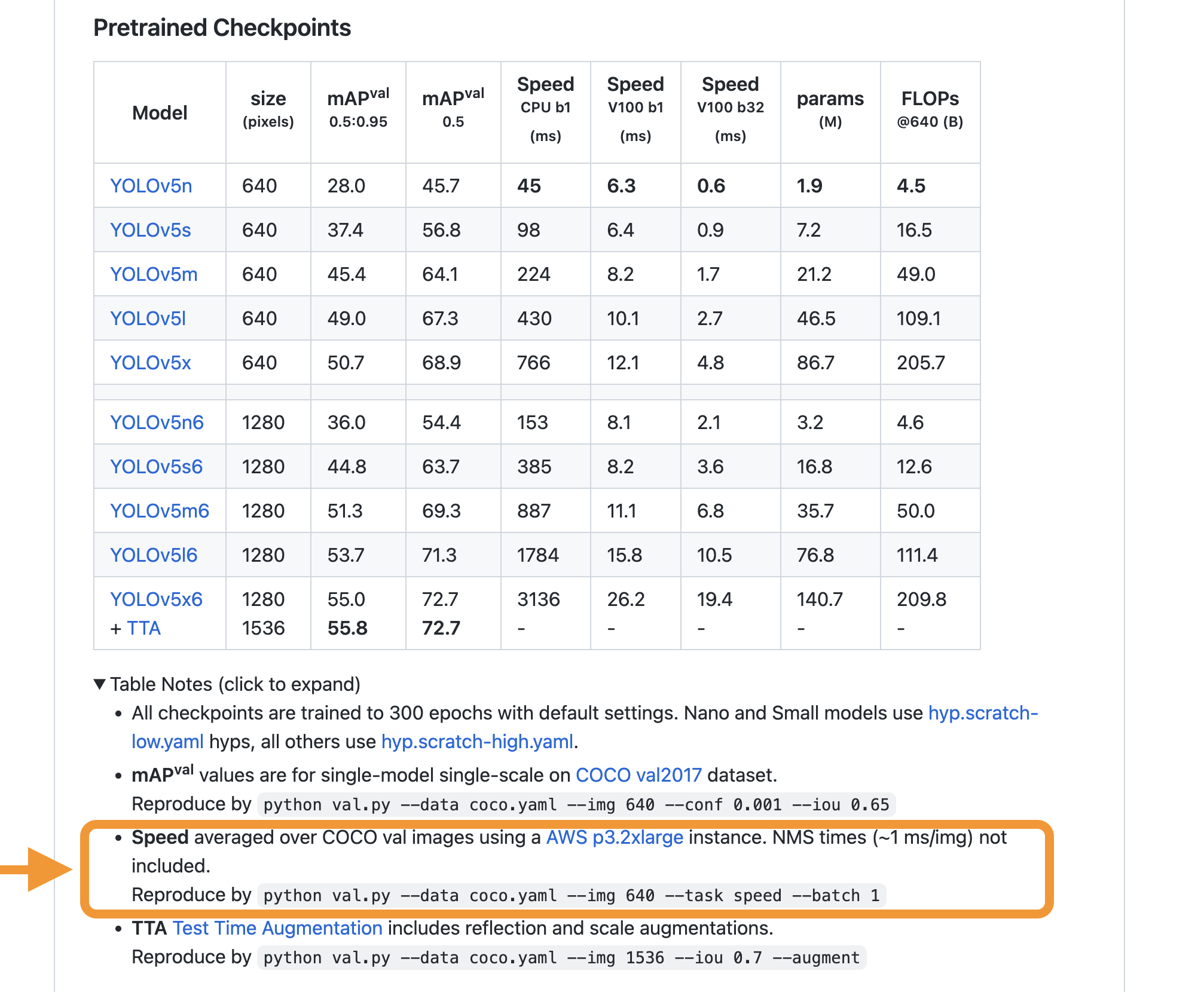
Beta Was this translation helpful? Give feedback.
-
|
Thanks Glenn, a minor detail I overlooked 😄 |
Beta Was this translation helpful? Give feedback.
-
|
@glenn-jocher |

Beta Was this translation helpful? Give feedback.
-
|
@tigerzjh see https://community.ultralytics.com/t/yolov5-study-batch-size-vs-speed |
Beta Was this translation helpful? Give feedback.
@henningscale a K80 is one of the slowest GPUs available, so you should expect slow results. Hardware to reproduce (AWS P3 instance with V100 GPU) is indicated in table notes, as well as commands to reproduce.