Repository files navigation
2. What Are Design Fundamentals?
DFs are building blocks to solve Design Interview questions
Just like you need to know Data Structure to solve Coding interview questions
Flow when user enters url on browser and press enter:
A req is sent to DNS server, a resolved IP address corresonding to address is sent back to user
User uses that IP address as a unique identifier of one entity on the internet, send a message to server (including src IP and dest IP)
Server receives req from client, look at the req to determine what user needs before sending back the resource to src IP
HTTP (Hyper Text Transfer Protocol):
TCP (Transmission Control Protocol): top of IP, reliable (come in order + error checking), 3-way handshake before actual transmission
IP (Internet Protocol): used for routing purposes, header contains src IP && dest IP, limited size, no order
Database: stores data, supports 2 main operations: WRITE (Create, Update, Delete) && READ
2 types:
In-memory: Fast retrieval, not persist (after shutdown)
Disk: Slow, do persist
6. Latency And Throughput
Latency: How long it takes for data to traverse between systems.
Specific systems may requires higher latency: online games
Throughput: How much work can be handled at a time
Context 1️⃣ 1Gbps connection
Context 2️⃣ Refers to amount of reqs that one server can handle at a time
How to increase throughput:
Pay more $$$
Add more servers
What is availability? Resistant to failure or fault-tolerant (server shutdown || db shutdown || ...)
Why is it important? You can lose customers if they can not access the service
How to measure availability? Uptime / Total Time (1 Year) ~ 99.999%
High Availability: More Nines
SLA/SLO (Service Level Agreement/Objective):
The Service Provider's promise about service's uptime.
They will take penalty if they fail to keep up with their words.
Evaluating a system's availability, must consider all services, what is the core service.
How to increase Availability? Redundancy
Add more servers to avoid single point of failure, having LB to coordinate traffic
Add more LBs
2 types of Redundancy:
Passive: having multiple machines working at the same time, when one goes down, others will take care
Active: having one machine working at one time, when it goes down, one machine from the pool takes over
🥅 Goal: Reduce latency
Definition: Stores data in a place different from the original one. Only cache data to be read.
Places to cache:
FE: static data, fetch once
BE: expensive computations, frequent calls to DB
DB: long-running queries that data does change frequently
2 types:
Write-through: Write to both cache and DB, takes time but high-consistent
Write-back: Write to cache only, db will be updated later (intervals), high risk of losing data before db able to sync data
What types to choose: Depends on the resource and how important it is that resource is up-to-date
Comment on youtube: Requires high-accuracy
View Count: It's okay be stale for certain amount of time
Stale data:
One that is out-of-date (in cache), that is not in sync with latest one in db
Solution: Invalidate
Eviction policies: We don't want data to be in cache forever
LRU: Take the least recently used out
LFU: Take the least frequently used out
LIFO
FIFO
2 types
Reverse Proxy (nginx)
acts on behalf of server, DNS resolves to IP of reverse proxy
features: filters reqs, logging, caching html, Load Balancing
Forward Proxy: acts on behalf of client, like VPN
Context: 1 server has limited throughput
Scaling:
Vertical
Horizontal: Add more servers => need for a LB
What is a LB:
Server or reverse proxy (acts on behalf of server)
Balance reqs between servers
Types:
Hardware: Dedicated machine
Software (our focus)
Server selection strategies:
Random: Naive, inconsistent, imbalance
Round-Robin: Select one by one alternately
Round-Robin Weighted: Put a weight on prioritized server (powerful one) so more traffic is directed for that one
Performance-based: Frequently do health check amongst servers, select one highly-performant
IP-based:
Hash ip to get an unique number x
x % numOfServers => index of server
Pros: 1 ip / 1 server, reqs from 1 user comes back to same server, so never miss the cache
Cons: In case we add or remove servers, mapping will change
Can use multiple selection strategies for one system.
Context: Server selection algorithm of LB (ip based)
Problem with ordinary ip-based:
IP % numOfServers => index of server
As numberOfServers changes, the mapping between IP and Server will also change
As numberOfServers changes (add servers || existing one goes down) most of mappings will not change
One server gets lot of load? Virtual servers
Idea: Client_A_IP <=> [ 👉 ServerA , ServerB, ServerC ] (First Choice)
Definition: table (row: data record, col: props), structured (adding data to db must comply with schema)
Powerful queries with SQL
ACID
Atomicity (transaction): transfer money = (subtract from A'account, add to B's account)
Consistency: No stale data (>< eventual consistency)
Isolation (locking):
trasactions run in isolation from each other at the same time
but is sequential at the end
Durability: once transaction is committed, can't reverse (permanent effect)
Indexing:
Use auxiliary table to optimize read queries
Cons: Slow down write queries (must write to 2 tables)
Characteristics: non-relational, no sql
Pros:
Flexible (no structure)
Simple
Fast (hashing)
Use cases:
Variations:
Write to: disk || ram
consistency: strong || eventual
UC1: Increase availability
Main db handles queries, update sync to replicas
In case main db goes down, replicas take over
UC2: Increase latency
Have dbs at different regions, storing data for users coming from there
Users from region A might get replicated to region B's db asynchrously (eventual consistency - can't see immediate results)
UC3: Increase throughput
Horizontal scale: Clone more dbs (replicas) and have them all handle traffic
Cons: inefficient in case of huge db
Idea: Split db
Pros: No duplication, increase throughput
How to split:
Name start with _
Users by regions
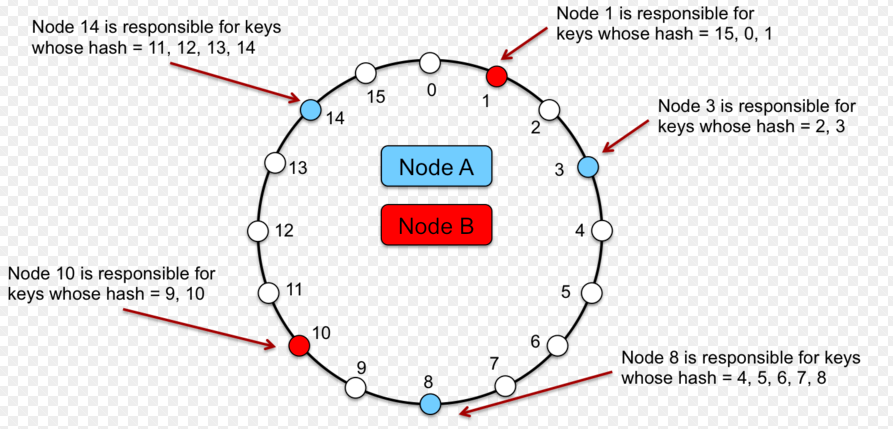
Consistent hashing
Determine which shard to go:
In server
In reverse-proxy
Context: Business logic is executed once amongst multiple servers
Example: Recurring payment
Flow: (1) 3rd service charge user's money (2) 3rd service sends a message to update db
We don't want to expose db for 3rd service => set up a server to listen for message
Scaling quesiton: What if it goes down => set up standby servers that can take over anytime and do business logic
There must be a way to communicate between servers: (1) who is leader now, (2) who will be leader if current leader goes down
Leader election: consensus algorithm
Tools
Zoo Keeper (Uber)
Etcd: key-value store, high availability, strong consistency
17. Peer-To-Peer Networks
Context: Sending huge files to a lot of clients
Problem: Low throughput in general, as clients have to wait for their turns to be served
Solution:
Break file into small chunks
Consider each client as peer, can send and receive chunks from others, not just from server
Have a tracker to coordinate traffic: decide who should talk to who
Use DHT: Distributed Hash Table
18. Polling And Streaming
Same: Data needs to be updated in a automatic way
Polling:
Client proactively sends reqs to server after certain interval
Cons: Data may become stale
Solution: Reduce interval time => Cons: Load overhead on server side
Use case: Don't need data to be updated regularly
Streaming:
Server proactively push messages to client on a long-lived connection
Data is always updated
Use case: Need for realtime data like trading app, chat app
Def: Set of constants
Formats: json, yaml
Types
Static: Any change config requires new code deployment
Dynamic: Quick impact
Def: A threshold of how many operations can be executed over a certain period of time (exp: 2 reqs / 10s)
Why? DoS protection (not DDoS), reduce overhead for server
Limit based on factors:
Scaling:
Put Rate Limiting service on a separate machine, using Redis to store data.
21. Logging And Monitoring
Why: Reproduce issue, debug
Formats: json, syslog
What to logs: error, reqs
Features: Visibility, logs -> metrics -> insights, Auto alerts when err reaches threshold
Variations: ggStackDriver, time series database
22. Publish/Subscribe Pattern
Context: Streaming
4 entities:
Subscribers: Clients
Publishers: Servers
Topics (Channels): intermediary over which publishers push messages
Messages:
Idempotent ops: data could be sent > 1 times => in case publishers don't receive ack msg
Filtering
Topic-based
Content-based: Publishers decide whether or not to deliver messages based on message's content
Variations: google cloud pubsub, Apache kafka
MapReduce
Security And HTTPS
API Design
About
No description, website, or topics provided.
Resources
Stars
Watchers
Forks
You can’t perform that action at this time.