Welcome to the official repository for AtlasVA! 🚀
AtlasVA is a teacher-free visual skill memory framework designed for Vision-Language Model (VLM) agents. Unlike traditional methods that compress spatial knowledge into lossy text and rely on proprietary LLMs for supervision, AtlasVA keeps experience visually grounded. It organizes memory into three complementary layers: spatial heatmaps, visual exemplars, and symbolic text skills. By evolving danger and affinity atlases directly from trajectory statistics, AtlasVA provides dense, coordinate-aware guidance for reinforcement learning. This unifies perception, memory, and optimization without external LLM supervision, achieving strong performance on spatially intensive tasks like Sokoban, FrozenLake, 3D embodied navigation, and 3D robotic manipulation! 🏆
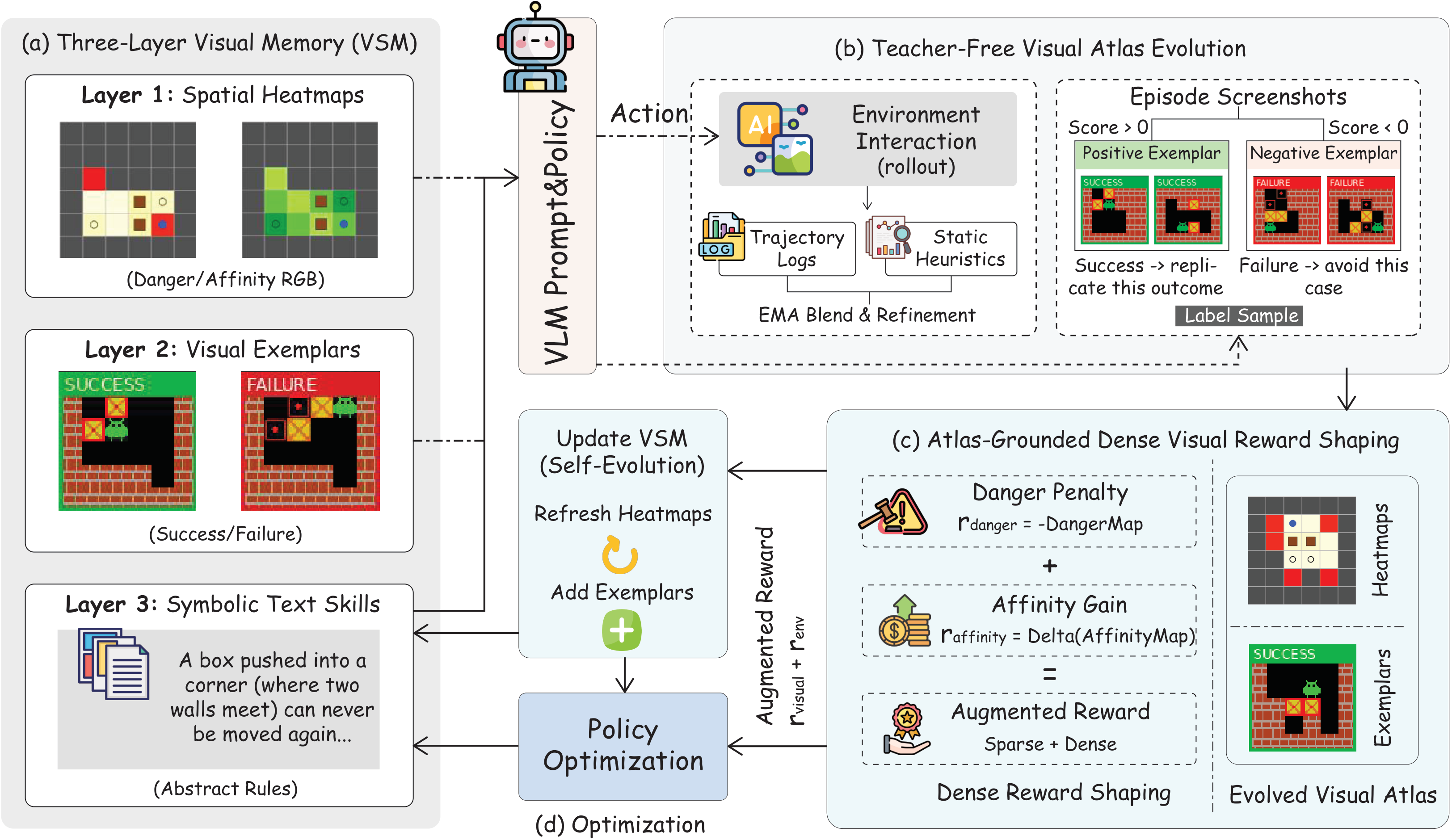
The code is organized to reproduce the reinforcement-learning runs and evaluation scripts used in the paper. The main package is atlasva, and the training backend is built on the vendored verl directory.
atlasva/: AtlasVA environments, agent loop, visual skill memory, reward shaping, and evaluation utilities.atlasva/configs/: Hydra entry configs. The main training config isatlasva_multiturn.yaml.scripts/: training and validation configs for each environment.scripts/Giants/: API-based zero-shot large-model evaluation scripts.verl/: the RL training backend used by the training scripts.
⚠️ Note: Large model checkpoints and experiment outputs are not included in the source artifact. Training scripts write outputs toexps/.
The full training scripts are configured for one node with 8 GPUs:
- 🐧 CUDA-capable Linux machine (CUDA 12.8).
- 🎮 8 GPUs for the default scripts.
- 🐍 Python 3.12. We used a Conda environment (PyTorch: 2.8.0+cu128, PyTorch CUDA build: 12.8).
- 🧠 Qwen2.5-VL-3B-Instruct as the default policy model.
- 📊 Optional Weights & Biases logging. Disable or change
trainer.loggerin the scripts if W&B is not available.
For quick code checks, a CPU-only machine is enough. For full reproduction, reviewers should run on a CUDA machine with enough GPU memory for vLLM and FSDP.
Create and activate a fresh environment:
conda create -n atlasva python=3.12 -y
conda activate atlasvaInstall the vendored verl backend:
cd verl
USE_MEGATRON=0 bash scripts/install_vllm_sglang_mcore.sh
pip install --no-deps -e .
cd ..Install AtlasVA and runtime dependencies:
pip install -e .
pip install "trl==0.26.2"
pip install "vllm==0.11.0"
pip install "transformers==4.56.2"
pip install "setuptools==79.0.1"
pip install matplotlib einops pyzmq hydra-core fire ray wandb PillowIf your CUDA/PyTorch setup requires FlashAttention explicitly, install it after PyTorch is available:
pip install "flash-attn==2.8.3" --no-build-isolationPrimitiveSkill and Swap use ManiSkill/SAPIEN rendering. Install ManiSkill and download the assets before running those environments:
pip install "mani_skill==3.0.0b20"
python -m mani_skill.utils.download_asset PickSingleYCB-v1 -y
python -m mani_skill.utils.download_asset partnet_mobility_cabinet -yOn headless Linux machines, ManiSkill/SAPIEN also needs working EGL/Vulkan drivers and GLVND vendor files. If imports fail with messages such as /usr/share/glvnd/egl_vendor.d missing, install the host NVIDIA driver, Vulkan/GLVND runtime packages, and verify that the container or job exposes /usr/share/glvnd/egl_vendor.d and the NVIDIA ICD files.
The pre-trained AtlasVA model weights are publicly available on Hugging Face: 🤗 wangpan-ustc/AtlasVA
For training, the scripts use Qwen/Qwen2.5-VL-3B-Instruct as the base policy model by default. To avoid repeated downloads, point the scripts to a local checkpoint:
export QWEN25_VL_3B_LOCAL_PATH=/path/to/Qwen2.5-VL-3B-InstructEach script checks this variable first. If config.json exists under that directory, the script switches Hugging Face and Transformers to offline mode. Otherwise, it falls back to the Hugging Face model ID.
Run these commands before launching expensive training:
python -m compileall -q atlasva scripts setup.py
python -c "import atlasva; import atlasva.envs.registry; import atlasva.envs_remote; print('imports ok')"
python setup.py --nameAfter installing Hydra/Ray/vLLM dependencies, check that the training entry can load:
python -m atlasva.main_ppo \
--config-path="$(pwd)/atlasva/configs" \
--config-name=atlasva_multiturn \
--help| Path | Purpose |
|---|---|
atlasva/main_ppo.py |
PPO training entry point. |
atlasva/ray_trainer.py |
AtlasVA training loop extensions. |
atlasva/agent_loop/ |
Multi-turn environment-agent interaction loop. |
atlasva/skills/ |
Text skills, visual skill memory, heatmaps, exemplars, and visual rewards. |
atlasva/envs/ |
Sokoban, FrozenLake, Navigation, and PrimitiveSkill environments. |
atlasva/envs_remote/ |
HTTP client/server wrapper for remote rendered environments. |
scripts/*/*.yaml |
Dataset and environment specifications. |
scripts/*/*.sh |
Reproduction scripts for main runs and baselines. |
Run all commands from the repository root. The scripts create experiment directories under exps/<project>/<experiment>/.
bash scripts/sokoban/train_ppo_qwen25vl3b_Base.sh
bash scripts/sokoban/train_ppo_qwen25vl3b_Skill.shbash scripts/frozenlake/train_ppo_qwen25vl3b_Skill.sh
bash scripts/frozenlake/train_grpo_qwen25vl3b_Skill.shNavigation uses a remote environment server. Start the server first:
python -m atlasva.envs.navigation.serve \
--port=8036 \
--devices='[0,1,2,3,4,5,6,7]' \
--max_envs=512For a local single-server run, use the _Local script and local YAML files:
bash scripts/navigation/train_ppo_qwen25vl3b_SkillCommon_Local.shFor multi-server runs, edit base_urls in scripts/navigation/train_navigation_base_common.yaml and scripts/navigation/val_navigation_base_common.yaml, then run:
bash scripts/navigation/train_ppo_qwen25vl3b_BaseCommon.sh
bash scripts/navigation/train_ppo_qwen25vl3b_SkillCommon.shPrimitiveSkill also supports remote rendering. Start one or more servers:
python -m atlasva.envs.primitive_skill.serve --port=8037 --max_envs=512
python -m atlasva.envs.primitive_skill.serve --port=8038 --max_envs=512
python -m atlasva.envs.primitive_skill.serve --port=8039 --max_envs=512Then edit the base_urls fields in scripts/primitive_skill/train_primitive_skill_vision_remote.yaml and scripts/primitive_skill/val_primitive_skill_vision_remote.yaml if your server addresses differ from the defaults. Launch:
bash scripts/primitive_skill/train_ppo_qwen25vl3b_Base.sh
bash scripts/primitive_skill/train_ppo_qwen25vl3b_Skill.shTraining scripts write:
- 💾 checkpoints to
exps/<project>/<experiment>/verl_checkpoints/; - 📈 validation traces to
exps/<project>/<experiment>/validation/; - 🎥 rollout dumps to
exps/<project>/<experiment>/rollout_data/; - 📝 logs to both the experiment directory and the repository root.
The default scripts use W&B plus console logging:
wandb loginTo avoid W&B, change trainer.logger=['console','wandb'] to trainer.logger=['console'] in the target script.
The scripts/Giants/ directory evaluates closed-source or hosted models through OpenRouter-compatible APIs.
pip install openai
export OPENROUTER_API_KEY="sk-or-..."
bash scripts/Giants/eval_gpt4o.sh
bash scripts/Giants/eval_gpt5.sh
bash scripts/Giants/run_all_sokoban.shThe API evaluation writes summaries and episode dumps under exps/giants/.
Remote YAML files contain concrete base_urls used in our internal cluster, for example http://localhost:8036. Reviewers should replace these addresses with their own server addresses.
Health check:
curl -s http://localhost:8036/healthIf a rendering server runs on a separate machine, expose the server port with SSH tunneling or the cluster networking tool available in your environment.
ModuleNotFoundError: hydra,fire, orray: installhydra-core fire ray.python -m atlasva.main_ppocannot find the config: pass--config-path="$(pwd)/atlasva/configs" --config-name=atlasva_multiturn.ModuleNotFoundError: PIL: installPillow.- PrimitiveSkill or Swap fails during
mani_skill/SAPIEN import: check that ManiSkill assets are downloaded and EGL/Vulkan/GLVND files are available on the host or inside the container. - Remote training hangs at environment creation: check
base_urls, firewall rules, andcurl http://<host>:<port>/health. - Hugging Face downloads are slow or unavailable: set
QWEN25_VL_3B_LOCAL_PATHto a local model directory. - W&B is unavailable: change
trainer.loggerto console-only in the script.
For a lightweight artifact check:
- Install the environment.
- Run the smoke tests.
- Start one Navigation or PrimitiveSkill server.
- Edit the relevant YAML
base_urlstolocalhost. - Launch the corresponding
_Localor remote training script with reducedtrainer.total_training_stepsand smallern_envs.
For full reproduction, use the scripts listed above without reducing the training steps.
Our work builds upon VAGEN, and we sincerely appreciate the authors for their outstanding contributions.