基于 Spring Boot + React 的现代化个人博客系统
官方qq群 :577040366
次元栈 基于SpringBoot4的全新博客系统
平台核心功能:
- 📝 文章发布与内容管理(CMS)
- 💬 用户互动:评论、点赞
- 🔖 标签分类:支持跨圈层内容组织
- 👥 用户系统:个人主页、文章发布管理系统、RBAC权限系统......
- 📱 响应式前端,支持移动端浏览
- 📦 支持首页、文章页服务端渲染
- ......
| 层级 | 技术选型 |
|---|---|
| 后端 | Java 17+,Spring Boot 4,MySQL5.7+,Redis |
| 前端 | React 19,Vite,Tailwind CSS |
| 构建 | Maven (后端),npm(前端) |
| 部署 | Docker,Linux,Windows |
请移步b站查看部署视频
https://www.bilibili.com/video/BV1qncgzkEHk/
环境要求(给出版本为可用版本,其他版本请自行测试)
OpenJDK版本:17+
Redis版本:5+(可选)
mysql版本:5.7+
解压下载的压缩包
然后进入到目录下执行命令:
注:"--server.port=2223"选项为可选(用于强制指定服务运行端口)
java -jar dimstack-1.0-SNAPSHOT.jar --server.port=2223运行后找到终端输出的地址(如不指定--server.port=2223端口号是随机的)在浏览器打开
进入站点初始化界面,格式如下(域名端口改为自己的,在终端或日志中查看)
http://localhost:2223/init/setup

按照初始化向导的提示填写:管理员用户名、密码、站点运行端口、日志级别、mysql信息以及redis信息等(默认信息不懂的话不要动)
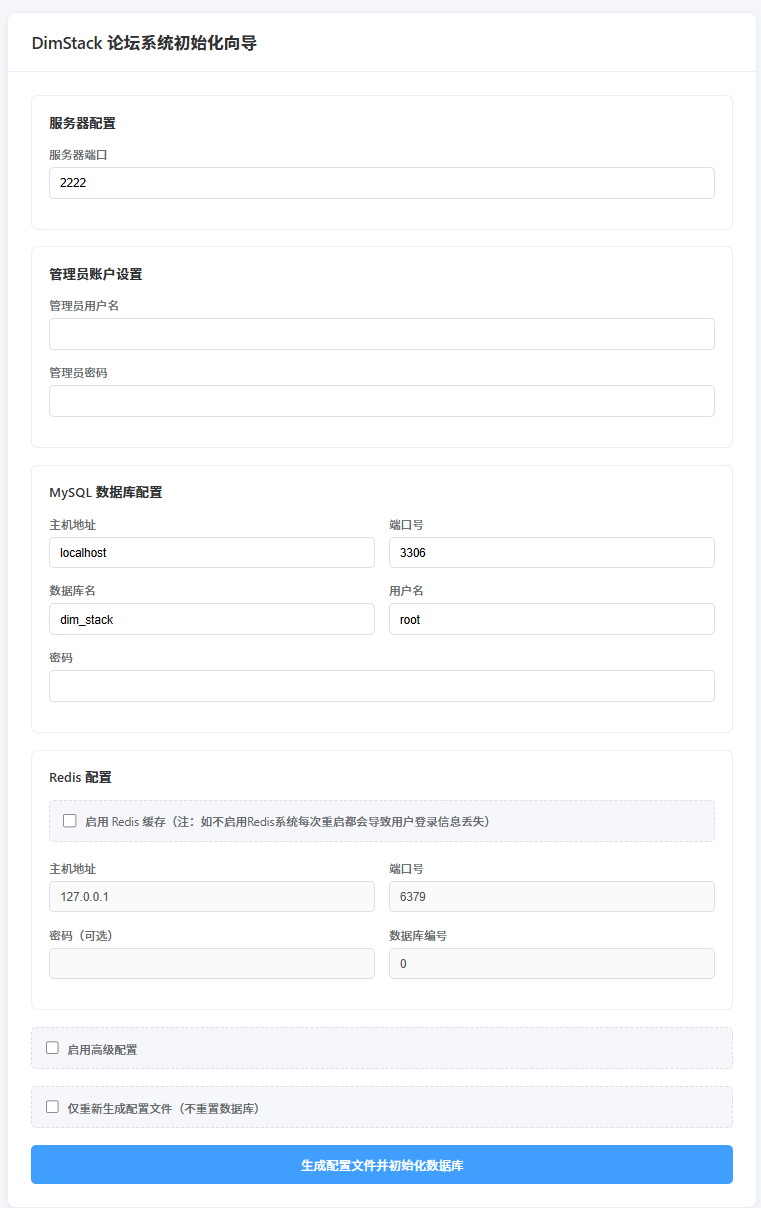
填写完后点击确认(系统会自动按照填写的信息完成初始化,导入sql、配置文件生成等),出现下面界面即为成功,重启即可
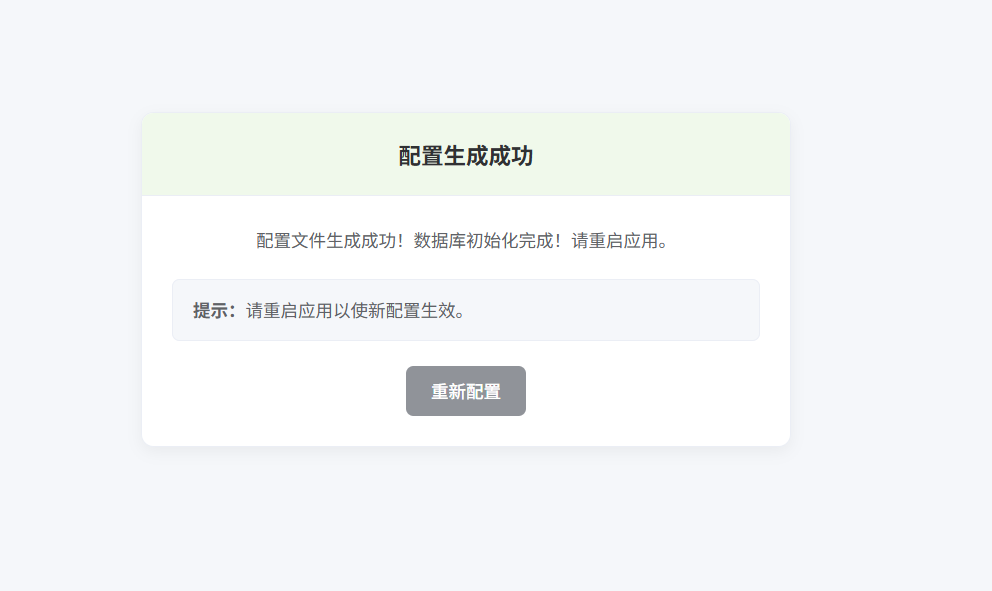
再次运行系统
java -jar dimstack-1.0-SNAPSHOT.jar运行后能看到主页正常加载即为成功
sudo vim /etc/systemd/system/dimstack.service[Unit]
Description=DimStack Application Service
After=network.target
[Service]
User=root
Group=root
WorkingDirectory=/root/dimstack
ExecStart=/usr/bin/java -jar /root/dimstack/dimstack-1.0-SNAPSHOT.jar
# 如果启用此配置会导致系统的自动重启出现故障,所以默认注释
#Restart=on-failure
#RestartSec=5
StandardOutput=journal
StandardError=journal
SyslogIdentifier=dimstack
# 可选:设置 JVM 参数(此处开启)
Environment="JAVA_OPTS=-Xms512m -Xmx1g"
[Install]
WantedBy=multi-user.target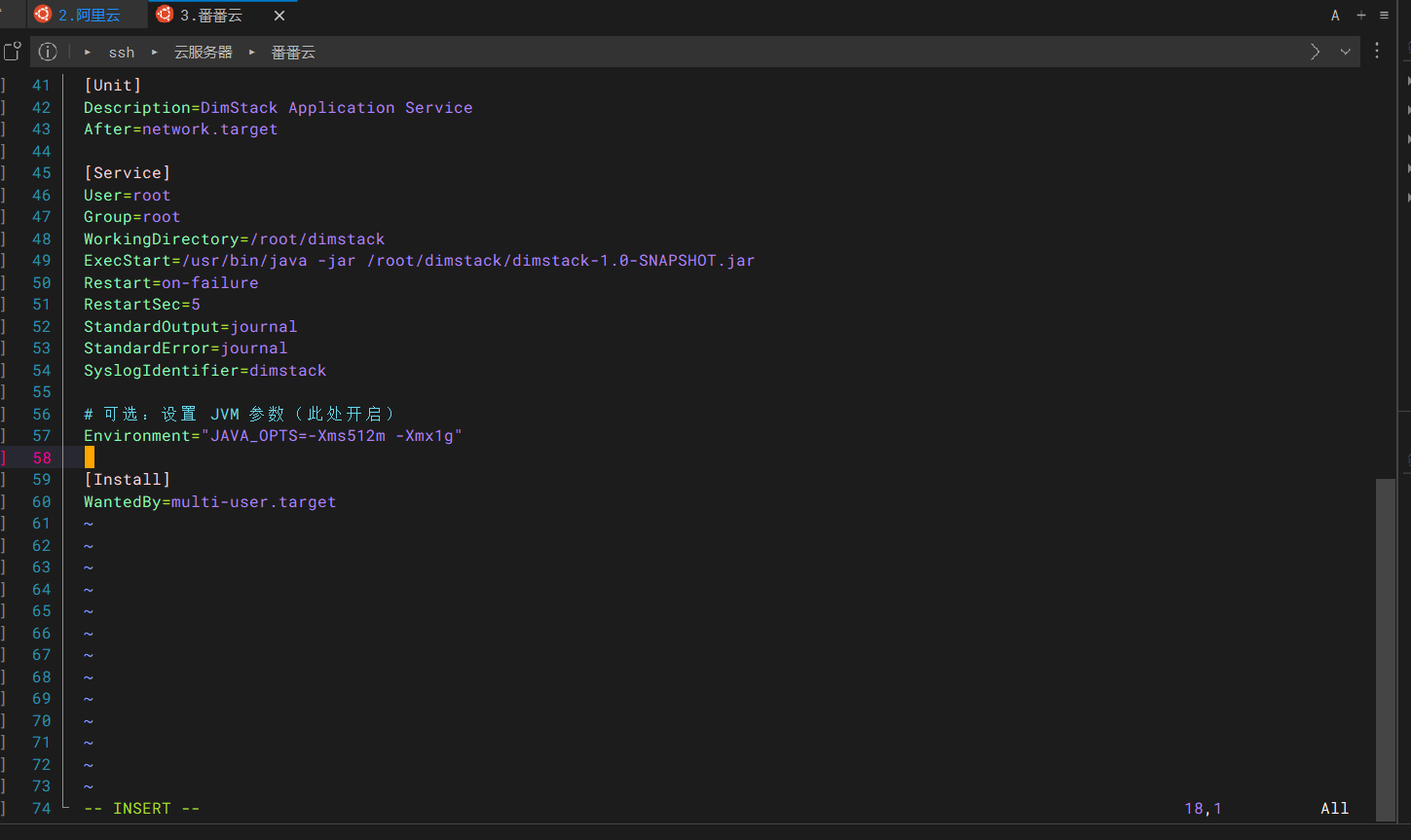
systemctl daemon-reload 
sudo systemctl start dimstack
sudo systemctl status dimstack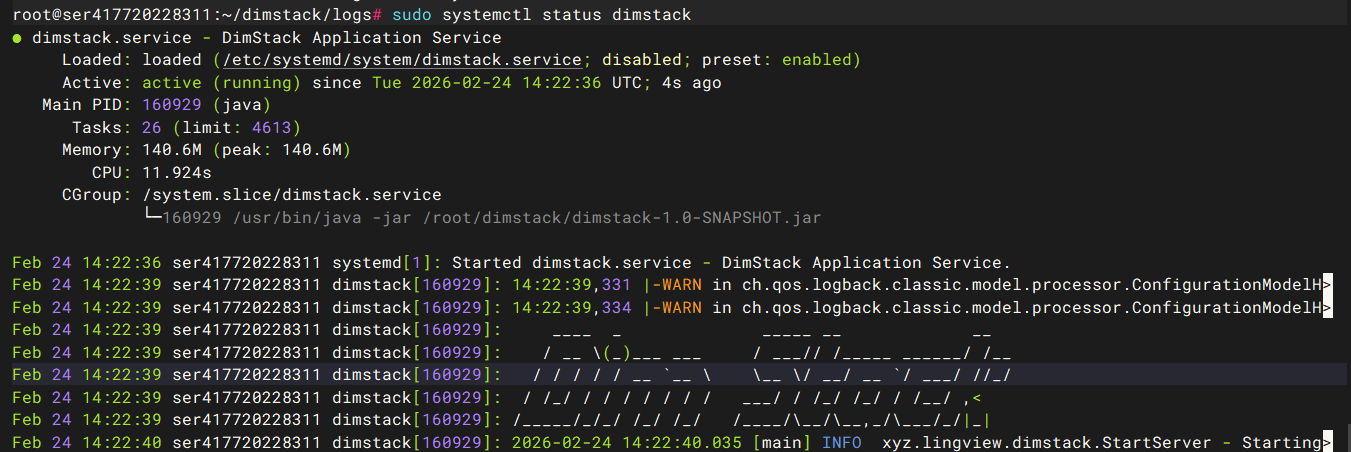

注:v84以下的版本没有一键更新系统,所以需要手动完整数据库更新
注:如果是如下版本的升级需要手动执行数据库升级脚本(如果数据库不是默认名请将USE dim_stack;修改为对应的数据库名)
v54->v55+
v64->v65+
v77->v84+
上述版本请到数据库更新脚本目录中下载对应的升级脚本
注:mysql5的兼容更新脚本只支持到5.7,其他版本请自行处理(建议数据库尽快升级至mysql8+)(v82+版本已逐步放弃mysql5.x支持,所以mysql5版本的系统请不要升级)
文章内容页已支持SSR并且适配主流搜索引擎,使用动态生成的 robots.txt 以及 sitemap.xml
- 针对搜索引擎 User-Agent 自动返回服务器渲染的 HTML。
- SSR 页面包含:
<title>:文章标题<meta name="description">:文章摘要<meta name="keywords">:文章标签- 文章内容和发布时间
- ......
- 普通用户访问则返回 SPA 首页,保持 React 的交互体验。
- 支持主流搜索引擎爬虫:
- Googlebot、Bingbot、Baiduspider、DuckDuckBot、Sogou、360Spider 等
支持动态生成 Sitemap 和 Robots.txt,智能处理反向代理头
针对Google、Bing等主流搜索引擎的爬虫进行了独立优化(未覆盖百度,百度爬虫仅能获取基础信息)
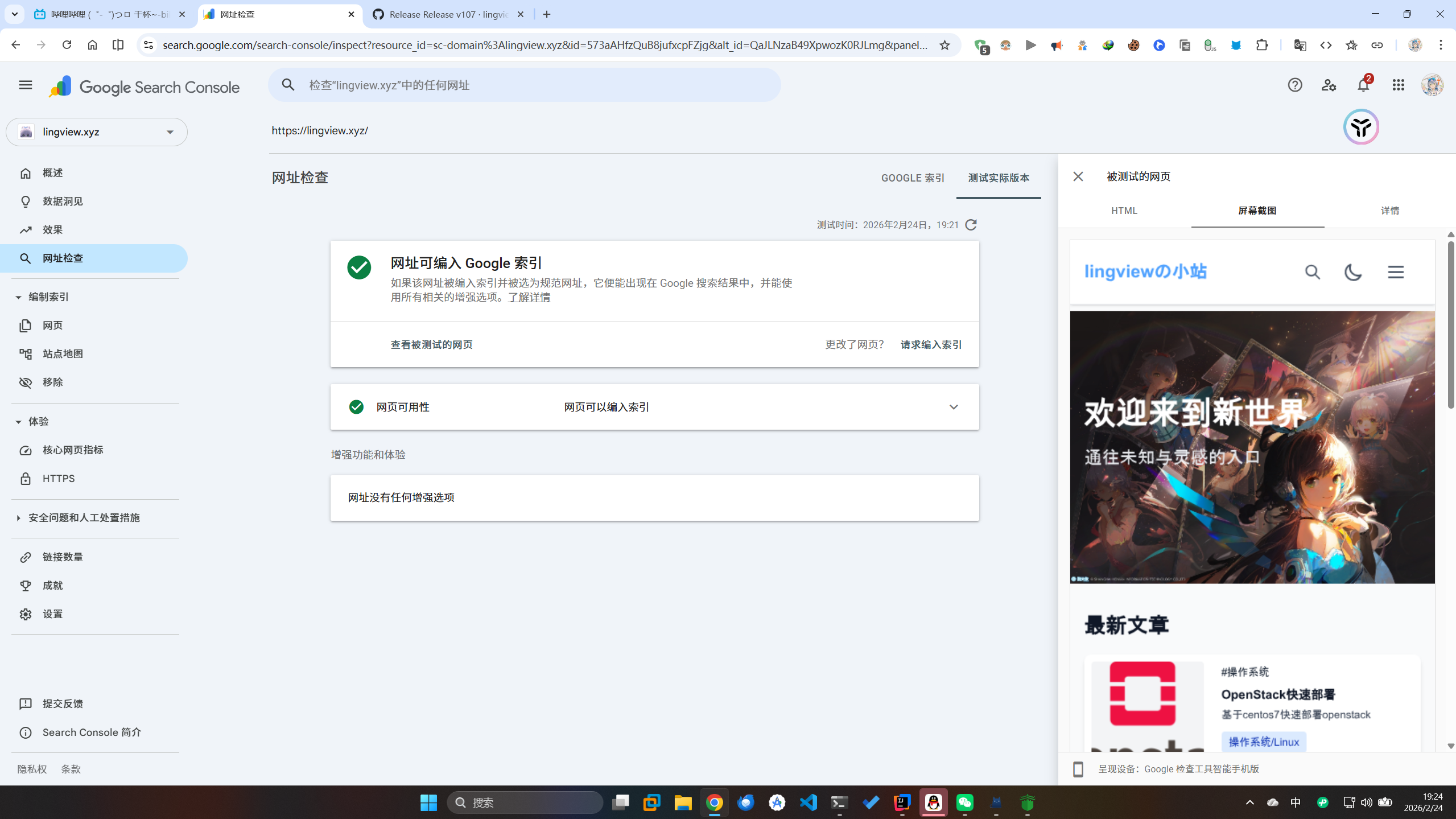
文章内容可以被大部分网页AI直接读取(密码文章无法读取)


感谢所有参与本项目的贡献者(按字母顺序排列):
- @bytegeek - 渗透测试
- @dear-sk - 系统测试
- @Denghls - 需求分析
- @hanbingniao - 系统测试
- @kongcangyimama - 主题设计
- @lingview - 系统开发
- @q1uf3ng - 渗透测试
- @YeFeng0712 - 需求分析
- @yukifia - 需求分析
- 感谢所有为本项目贡献代码、提出问题和提供反馈的开发者。
- 感谢开源社区持续的支持与贡献。
如果你在本项目中做出了贡献,请提交 PR 将你的名字加入到致谢名单中!