Parallel and more aggressive strided assigner#2660
Parallel and more aggressive strided assigner#2660JohanMabille merged 33 commits intoxtensor-stack:masterfrom
Conversation
|
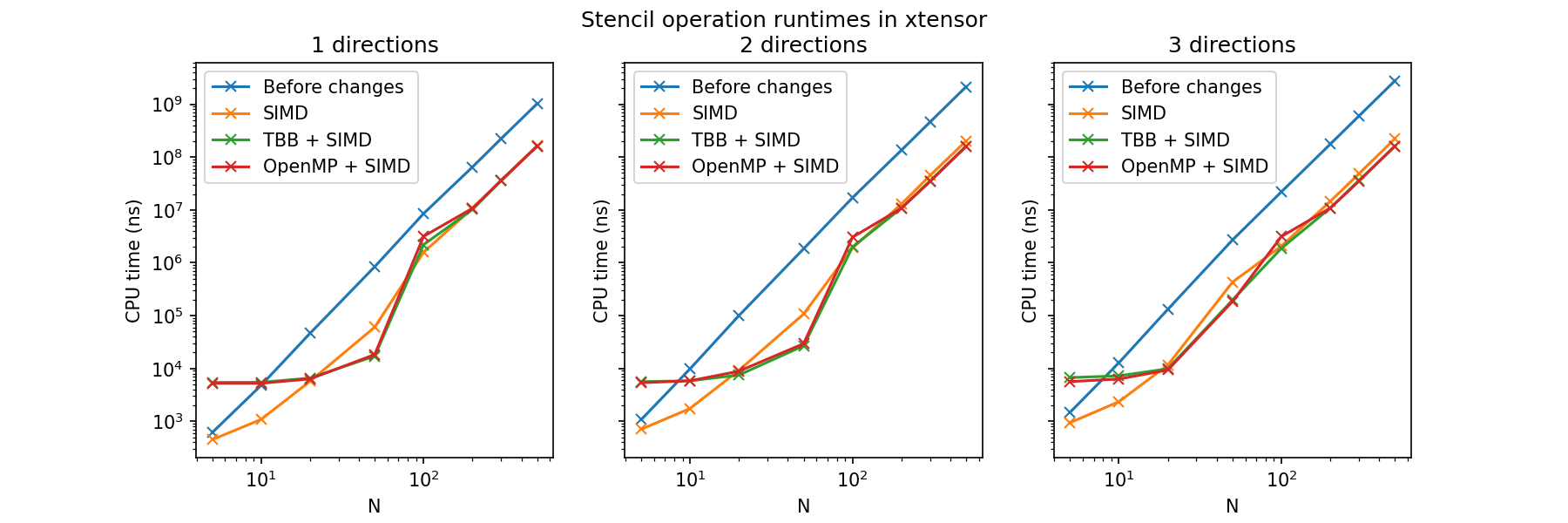
Wow, very impressive work. Quick question regarding the benchmarks -- is the CPU(new) single threaded or multithreaded using OpenMP / TBB? |
|
Thank you :) |
|
Thanks @ewoudwempe for picking up my work and feeding it back to xtensor. I am really happy to see this landing in xtensor. Apparently you also solved the remaining issue that the strided assigner is properly picked for 'xview' stencils. This issue kept me back from working on a PR. In particular, the xview degraded the layout to dynamic for sub-volumes that are not contiguous in all dimensions, though the strided assigner just requires the first dimension to be contiguous. Good work, and the benchmarks might look even better on HPC hardware with multiple memory controllers and NUMA's first-touch policy (if initialized properly). |
|
I just scrolled passed this. Very impressive! A preliminary huge thanks for taking the effort! |
|
Wow very impressive, thanks for the hard work! I will review it in the next few days, hopefully we can get it in the next release! |
|
If we don't manage to review this before next Friday, please ping us. Indeed it would be nice to get it in the next release. |
|
Thanks, I'd be happy to see this in soon as well! |
 JohanMabille
left a comment
JohanMabille
left a comment
There was a problem hiding this comment.
Really neat implementation, thanks for this. I think we could mutualise the parts of the code about the index minpulation (we do similar things in the stepper tools, but a bit differently), but this should be done in a dedicated PR.
Checklist
Description
I needed some faster strided assigner, and continued the work of @starboerg, who made a first working version (for OPENMP) in
#1973. I fixed a few bugs, made it work a bit more generally, and furthermore refactored things to make it testable. @starboerg made a first the initial working version (for OPENMP), thanks! @starboerg, I haven't asked, but hope you're okay with this PR as well.
The major changes
Can you let me know what needs to be done for this to be merged?
Some quick benchmarks of doing stencil-like operators are (run
benchmark/benchmark_xtensor --benchmark_filter=stencil_)