在学习JAVA的过程中深知查询各种碎片知识的痛苦, 在这里把自己学习的知识整理成笔记上传,希望能和大家多多交流,也希望能帮到更多的人。
- heap stack,方法区 , 直接内存, 堆和栈区别
- 内存可见性,重排序,顺序一致性,volatile,锁,final
- 内存分配策略
- 垃圾收集器(GC)
- GC算法
- GC参数
- 对象存活的判定
- OOP
- 对象头
- 即时编译器
- 编译优化
- classloader
- 类加载过程
- 双亲委派(破坏双亲委派)
- 模块化(jboss modules, osgl, jigsaw)
- jps, jstack, jmap, jstat, jconsole, jinfo, jhat, javap, btrace, TProfiler
- String , Integer, Long, Enum, BigDecimal, ThreadLocal, ClassLoader&& URLClassLoader, ArrayList && LinkedList,HashMap && LinkedHashMap && TreeMap && CouncurrenHashMap HashSet && LinkedHashSet && TreeSet , HashTable
-
java四大数据类型分类
-
整形 : byte(字节型), short(短整形) , int(整形) , long(长整形)
-
浮点型 : float(单精度浮点型), double(双精度浮点型)
-
字符型 : char
-
布尔型 : boolean
-
-
占用字节
数据类型 占用字节 默认值 封装类 byte 1 0 Byte -128~ 127(-2的7次方到2的7次方-1) short 2 0 Short -32768~32767(-2的15次方到2的15次方-1) int 4 0 Integer -2147483648~2147483647(-2的31次方到2的31次方-1) long 8 0.0l Long -9223372036854774808~9223372036854774807(-2的63次方到2的63次方-1) float 4 0.0f Float 3.402823e+38~1.401298e-45(e+38 表示乘以10的38次方,而e-45 表示乘以10的负45次方) double 8 0 Double 1.797693e+308~4.9000000e-324(e+38 表示乘以10的38次方,而e-45 表示乘以10的负45次方) char 2 \u0000(空格) Character 通常gbk / gb2312 是两个字节,utf-8 是3个字节。 通常的浮点型数据在不声明的情况下都是double型的,如果要表示一个数据时float 型的,可以在数据后面加上 "F" 。- double 类型比float 类型存储范围更大,精度更高。
- char 有多种初始化方式:
- char ch = 'a'; // 可以是汉字,因为是Unicode编码
- char ch = 1010; // 可以是十进制数、八进制数、十六进制数等等。
- char ch = '\0'; // 可以用字符编码来初始化,如:'\0' 表示结束符,它的ascll码是0,这句话的意思和 ch = 0 是一个意思。
- String.getBytes(encoding) 方法获取的是指定编码的byte数组表示。
- 通常gbk / gb2312 是两个字节,utf-8 是3个字节。如果不指定encoding 则获取系统默认encoding
-
类型转换
除了boolean类型外,其他7种类型都可以进行转换,只是可能会产生精度损失或其他一些变化
double > float > long > int > short > byte : 从左到右从大到小排列
- 自动转换:无需任何操作。
- 强制转换: 需使用转换操作符(type)。
Note : 如果从小转换到大,那么可以直接转换,而从大到小,或char 和其他6种数据类型转换,则必须使用强制转换。-
自动转换 :自动转换时发生扩宽(widening conversion)。因为较大的类型(如int)要保存较小的类型(如byte),内存总是足够的,不需要强制转换。如果将字面值保存到byte、short、char、long的时候,也会自动进行类型转换。注意区别,此时从int(没有带L的整型字面值为int)到byte/short/char也是自动完成的,虽然它们都比int小。在自动类型转化中,除了以下几种情况可能会导致精度损失以外,其他的转换都不能出现精度损失。
》int--> float
》long--> float
》long--> double
》float -->double without strictfp
除了可能的精度损失外,自动转换不会出现任何运行时(run-time)异常。
-
强制类型转换 :如果要把大的转成小的,或者在short与char之间进行转换,就必须强制转换,也被称作缩小转换(narrowing conversion),因为必须显式地使数值更小以适应目标类型。强制转换采用转换操作符()。严格地说,将byte转为char不属于narrowing conversion),因为从byte到char的过程其实是byte-->int-->char,所以widening和narrowing都有。强制转换除了可能的精度损失外,还可能使模(overall magnitude)发生变化。强制转换格式如下:
(target-type) value;
如果整数的值超出了byte所能表示的范围,结果将对byte类型的范围取余数。例如a=256超出了byte的[-128,127]的范围,所以将257除以byte的范围(256)取余数得到b=1;需要注意的是,当a=200时,此时除了256取余数应该为-56,而不是200。
将浮点类型赋给整数类型的时候,会发生截尾(truncation)。也就是把小数的部分去掉,只留下整数部分。此时如果整数超出目标类型范围,一样将对目标类型的范围取余数。
-
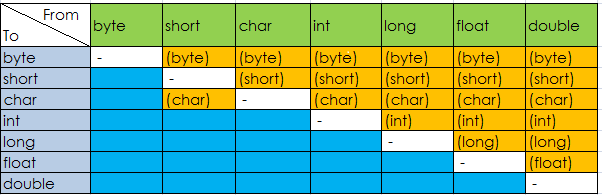
7中基本类型转换总结如下图
蓝色代表可以自动转换, 黄色代表需要强制转换
-
赋值及表达式中的类型转换
-
字面值赋值
在使用字面值对整数赋值的过程中,可以将int literal赋值给byte short char int,只要不超出范围。这个过程中的类型转换时自动完成的,但是如果你试图将long literal赋给byte,即使没有超出范围,也必须进行强制类型转换。例如 byte b = 10L;是错的,要进行强制转换。
-
表达式中的自动类型提升
除了赋值以外,表达式计算过程中也可能发生一些类型转换。在表达式中,类型提升规则如下:
-
所有byte/short/char都被提升为int。
-
如果有一个操作数为long,整个表达式提升为long。float和double情况也一样。
-
-
-
String , StringBuffer和StringBuilder
-
区别 :
- 三者都是final类, 都不允许被继承。
- String类是immutable的,长度不可改变。但是StringBuffer和StringBuilder长度是可变的
- StringBuffer是线程安全的, StringBuilder是线程不安全的
-
String和StringBuffer区别
-
String是immutable的对象,所以每次对String进行改变的时候都会生成一个新的String对象,然后将指针指向新的String对象,所以如果要经常改变字符串的话不要使用String,因为每次生成对象都会对系统性能产生影响,特别是当内存中引用的对象多了以后,JVM的GC就会开始工作,性能就会降低;
-
使用StringBuffer类时,每次都会对StringBuffer对象本身进行操作,而不是生成新的对象并改变对象引用,所以多数情况下推荐使用StringBuffer,特别是字符串对象经常要改变的情况;
-
在某些情况下,String对象的字符串拼接其实是被Java Compiler编译成了StringBuffer对象的拼接,所以这些时候String对象的速度并不会比StringBuffer对象慢,例如:
String s1 = “This is only a” + “ simple” + “ test”; StringBuffer Sb = new StringBuilder(“This is only a”).append(“ simple”).append(“ test”);
生成 String s1对象的速度并不比 StringBuffer慢。其实在Java Compiler里,自动做了如下转换:
// Java Compiler直接把上述第一条语句编译为: String s2 = “This is only a”; String s3 = “ simple”; String s4 = “ test”; String s1 = s2 + s3 + s4;
这时候,Java Compiler会规规矩矩的按照原来的方式去做,
String的concatenation(即+)操作利用了StringBuilder(或StringBuffer)的append方法实现,此时,对于上述情况,若s2,s3,s4采用String定义,拼接时需要额外创建一个StringBuffer(或StringBuilder),之后将StringBuffer转换为String;若采用StringBuffer(或StringBuilder),则不需额外创建StringBuffer -
StringBuilder(单线程使用,线程不安全)
StringBuilder是5.0新增的,此类提供一个与 StringBuffer 兼容的 API,但不保证同步。该类被设计用作 StringBuffer 的一个简易替换,用在字符串缓冲区被单个线程使用的时候(这种情况很普遍)。如果可能,建议优先采用该类,因为在大多数实现中,它比 StringBuffer 要快。两者的方法基本相同
-
-
使用技巧
- 基本原则:如果要操作少量的数据,用String ;单线程操作大量数据,用StringBuilder ;多线程操作大量数据,用StringBuffer。
- 不要使用String类的”+”来进行频繁的拼接,因为那样的性能极差的,应该使用StringBuffer或StringBuilder类,这在Java的优化上是一条比较重要的原则
- StringBuilder一般使用在方法内部来完成类似”+”功能,因为是线程不安全的,所以用完以后可以丢弃。StringBuffer主要用在全局变量中
- 相同情况下使用 StirngBuilder 相比使用 StringBuffer 仅能获得 10%~15% 左右的性能提升,但却要冒多线程不安全的风险。而在现实的模块化编程中,负责某一模块的程序员不一定能清晰地判断该模块是否会放入多线程的环境中运行,
因此:除非确定系统的瓶颈是在 StringBuffer 上,并且确定你的模块不会运行在多线程模式下,才可以采用StringBuilder;否则还是用StringBuffer
-
-
JDK6 和7中substring的原理和区别
先了解substring()的作用
// 截取字符串并返回其[beginIndex,endIndex-1]范围内的内容 substring(int beginIndex, int endIndex) String x = "abcdef"; x = x.substring(1,3); System.out.println(x); //bc
调用substring时候发生了什么呢?
因为String是不可变的,当使用x.substring(1,3)对x赋值的时候,它会指向一个全新的字符串
然而,这个图不是完全正确的表示堆中发生的事情。
因为在jdk6 和 jdk7中调用substring时发生的事情并不一样-
jdk 6 中的 substring
String是通过字符数组实现的。在jdk 6 中,String类包含三个成员变量:
char value[], int offset,int count。他们分别用来存储真正的字符数组,数组的第一个位置索引以及字符串中包含的字符个数。当调用substring方法的时候,会创建一个新的string对象,但是这个string的值仍然指向堆中的同一个字符数组。这两个对象中只有count和offset 的值是不同的。
下面的是JDK 6 中的源代码
//JDK 6 String(int offset, int count, char value[]) { this.value = value; this.offset = offset; this.count = count; } public String substring(int beginIndex, int endIndex) { //check boundary return new String(offset + beginIndex, endIndex - beginIndex, value); }
Note: 为什么在JDK7中要对这个函数进行修改呢?因为JDK6中的substring会导致下面的问题:
/* 如果你有一个很长很长的字符串,但是当你使用substring进行切割的时候你只需要很短的一段。这可能导致性能问题,因为你需要的只是一小段字符序列,但是你却引用了整个字符串(因为这个非常长的字符数组一直在被引用,所以无法被回收,就可能导致内存泄露)。在JDK 6中,一般用以下方式来解决该问题,原理其实就是生成一个新的字符串并引用他。 */ x = x.substring(x, y) + ""
-
jdk 7 中的 substring
上面提到的问题,在jdk 7中得到解决。在jdk 7 中,substring方法会在堆内存中创建一个新的数组。
JDK7中的源码如下:
//JDK 7 public String(char value[], int offset, int count) { //check boundary this.value = Arrays.copyOfRange(value, offset, offset + count); } public String substring(int beginIndex, int endIndex) { //check boundary int subLen = endIndex - beginIndex; return new String(value, beginIndex, subLen); }
-
-
replaceFirst,replaceAll, replace的区别
- replace(String target, String replacement) ,用replacement替换所有的target,两个参数都是字符串。
- replaceAll(String regex, String replacement) ,用replacement替换所有的regex匹配项,regex很明显是个正则表达式,replacement是字符串。
- replaceFirst(String regex, String replacement) ,基本和replaceAll相同,区别是只替换第一个匹配项.
**总结 : **
-
相同点 : replace和replaceAll都是全部替换,即把源字符串中的某一字符或字符串全部换成指定的字符或字符串,
-
不同点 :
-
replace替换的只能是**
字符或字符串**形式, -
replaceAll和replaceFirst()是基于**
规则表达式(正则表达式)**的替换 -
replaceAll是替换所有的,而replaceFirst()仅替换第一次出现的.
-
另外,如果replaceAll()和replaceFirst()所用的参数据不是基于正则表达式(即参数也是string)的,则与replace()替换字符串的效果是一样的,即这两者也支持字符串的操作;
-
执行了替换操作后,源字符串的内容是没有发生改变的,需要再一次赋值给源数据
String a = "Hello"; a.replace("e","f"); System.out.println(a);// Hello a=a.replace("e","f"); System.out.println(a); // Hfllo
-
下面是这三种函数的各种使用案例,可以帮助理解上面提到的工作原理
String src = "ab43a2c43d"; System.out.println(src.replace("3","f"));//=>ab4f2c4fd. System.out.println(src.replace('3','f'));//=>ab4f2c4fd. System.out.println(src.replaceAll("\\d","f"));//=>abffafcffd. System.out.println(src.replaceAll("3","f"));//=>ab4fa2c4fd. System.out.println(src.replaceFirst("\\d","f"));//=>abf32c43d System.out.println(src.replaceFirst("3","f"));//=>ab4fa2c43d. System.out.println(src); //=>ab43a2c43d // 下面尝试用上面的三种方式将字符串中的a替换成\a System.out.println("abac".replace("a", "\\a")); //\ab\ac System.out.println("abac".replaceAll("a", "\\a")); //abac System.out.println("abac".replaceFirst("a", "\\a")); //abac System.out.println("abac".replaceAll("a", "\\\\a")); //\ab\ac System.out.println("abac".replaceFirst("a", "\\\\a")); //\abac // 如何将字符串中的""替换成"\": String a ="H\\llo"; System.out.println(a); //=>H\llo,因为是转义字符 System.out.println(a.replace("\\","\\\\")); //=>H\\llo System.out.println(a.replaceAll("\\\\","\\\\\\\\")); //=>H\\llo
原因 :
''在java中是一个转义字符,所以需要用两个代表一个。例如System.out.println( "\" ) ;只打印出一个""。但是''也是正则表达式中的转义字符(replaceAll 的参数就是正则表达式),需要用两个代表一个。所以:\\被java转换成\,\又被正则表达式转换成\。 CODE: \\\\ Java: \\ Regex: \将字符串中的'/'替换成''的几种方式:
String msgIn = "a/b"; String msgOut; msgOut= msgIn.replaceAll("/", "\\\\"); msgOut= msgIn.replace("/", "\\"); msgOut= msgIn.replace('/', '\\');
-
-
String 对 '+'的重载
- String对象是只读的,所要指向它的任何引用都不可能改变它的值, so不会对其他引用产生什么卵影响.
- 用于String类中的”+” / “+=” 是Java中仅有的两个重载过的操作符,而java并不允许我们重载任何操作符;
/* 下面的代码,可能会这么工作: String有append方法,然后返回一个新的String对象的引用,以包含连接后的字符串,然后再append , 再创建新对象. 这种方式当然行得通,但是为了生成最终的String,次方式会产生一堆需要垃圾回收的中间对象.然后发现其性能略lowBi.那么编译器真的会这样做吗? */ public class StringTest { public static void main(String[] args) { String a = "abc"; String b = "123" + a + "def" + 777; System.out.println(b); } } /* 通过反编译上面这个类, 可以发现编译器会先引用StringBuilder并为String中的每个 “+” 进行一次append操作,最后调用toString()方法返回一个String并保存 */
- 如果在循环里使用“+”操作符会发生什么呢
/* 反编译下面的代码会发现,每一次循环,编译器都会生成一个新的StringBuilder,然后调用append方法区进行字符串拼接,最后再返回一个String。 */ String str = ""; for(int i = 0; i < num; i++) { str += "a"; } /* 如果反编译下面这个类, 编译器只会生成一次StringBuilder, 然后一直调用append方法,不会每次循环都生成新的StringBuilder */ StringBuilder a = new StringBuilder(); for(int i = 0; i < 10; i++) { a.append(i); //只有String能"+" }
-
String.valueOf和Integer.toString的区别
- Integer.toString() : 返回指定整数的有符号位的String对象,以10进制字符串形式返回
//源码实现 public static String toString(int i) { //等于最小值直接返回最小值字符串,避免getChars方法遇到最小值发生错误 if (i == Integer.MIN_VALUE) return "-2147483648"; //判断i的位数,若位负数增加1位用来保存符号位 int size = (i < 0) ? stringSize(-i) + 1 : stringSize(i); char[] buf = new char[size]; //将i转换位buf符号数组 getChars(i, size, buf); //因为buf数组是在方法内部生成,其他地方不会有其引用, //所以直接将其引用给String内部的value保存,用来初始化String return new String(buf, true); }
- String.valueOf()
/* 不同于Integer.toString(int),valueof有大量的重载方法 */ // 将对象转换成String类型 public static String valueOf(Object obj) { //可以看出这里调用对象的toString(),所以写对象时,最好重写其toString()方法。 //而且如果对象为null, 返回的是字符串"null", 而不是null object return (obj == null) ? "null" : obj.toString(); } //将字符转换成String类型 /* 这里先将字符转换成字符数组,可能好奇String(data,true)这个构造方法与上面的String(data)有什么不同,String(data, true)构造方法将引用传递给了String内部的value用来创建字符串,data在方法内部创建没有其他引用,所以可以直接传递,节约内存空间。 */ public static String valueOf(char c) { char data[] = {c}; return new String(data, true); } //将int类型转换成String类型 public static String valueOf(int i) { return Integer.toString(i); }
综上所述,可以看出String的valueof方法是将各种类型转换成String,内部重载了不同类型转String的处理,所以推荐使用valueof方法。
-
字符串的不可变性
上面提到过String是不可变得(immutable), 但是究竟为什么是不可变的?这么设计的好处是什么呢?
-
为什么不可变
- 首先,String是由char[]数组实现的, 直接上源码
public final class String implements java.io.Serializable, Comparable<String>, CharSequence { /** The value is used for character storage. */ private final char value[]; }
在程序内部这个数组被声明为private的,同时是个final的。 Private可以保证value数组不被调用者访问到,final可以确保数组的地址是不变的
// 注意: 声明数组为final的时仅仅可以保证数组的地址是不变的,并不能保证数组里面的值不变。 //看下面这个例子 public void tet(){ char[] arr = {'a', 'b'}; final char[] arr1 = {'1', '2'}; arr1 = arr; arr1[0]='0'; }
由上面的例子可以看出,String是不会被外部修改的,因为不可被继承,但是如果内部修改的话还是无法保证是immutable的,那么内部又是如何实现保证不会被改变的呢?
首先:我们知道String是一个引用类型,如果对它本身进行修改是不需要返回的,通过观察源码可以发现,任何写操作都会返回一个新的String对象。例如replace方法
public String replace(char oldChar, char newChar) { if (oldChar != newChar) { int len = value.length; int i = -1; char[] val = value; /* avoid getfield opcode */ while (++i < len) { if (val[i] == oldChar) { break; } } if (i < len) { char buf[] = new char[len]; for (int j = 0; j < i; j++) { buf[j] = val[j]; } while (i < len) { char c = val[i]; buf[i] = (c == oldChar) ? newChar : c; i++; } return new String(buf, true); } } return this; }
从上面的代码可以看出,在内部,任何对String的改变都会返回一个新的String对象, 巧妙的实现了String不可变的原理。
-
String类被声明成final的意义
类被声明为final的时候,这个类是不可以为继承的,这样就不能修改这个类里面的方法实现。 比方说如果String类可以被继承。那么我们就可以写一个方法去改变value数组,比如:
//改变value数组 public void setChar(char c , int index){ value[index] = c; } //或者直接去改变String对象: public static StringBuilder append(StringBuilder stringBuilder){ return stringBuilder.append("122"); }
-
String 为什么要设计成immutable,不可变的好处是什么?
-
大多数HashMap和HashSet的键值对类型都喜欢使用String,直接上代码
public void test() { Set<StringBuilder> set = new HashSet<StringBuilder>(); // StringBuilder类型的变量分别指向堆上的"a" 和"ab", StringBuilder stringBuilder = new StringBuilder("a"); StringBuilder stringBuilder1 = new StringBuilder("ab"); //将这两个变量放进HashSet中 set.add(stringBuilder); set.add(stringBuilder1); //创建一个新的StringBuilder stringBuilder2变量指向 stringBuilder 所在的地址 StringBuilder stringBuilder2 = stringBuilder; //在stringBuilder2上追加一个字符串"b", // 注意:由于StringBuilder是可变的,此时会改变stringBuilder的值 //此时会导致Set上出现两个相等的值(会指向堆上相同的地址),从而破坏了HashSet的键值唯一性 stringBuilder2.append("b"); set.add(stringBuilder2); }
由上代码可知,String的不可变性是很有必要的。
-
String的不可变性确保了线程安全。在并发场景下,对共享资源的写操作会引发静态条件,只有对资源进行写操作才引发资源状态的不一致,而不可变对象不可写,因此是线程安全的
-
**总结 : **综上,String不可变的原因:
- 防止被外部改变:
- 类设计为final的,确保类不被继承,方法不被覆盖
- 内部实现上用的是private final的数组
- 内部实现上避免改变原字符串:
- 任何对String的写操作都不是在原来的字符串上进行的修改,而是创建的新对象
- 保证线程安全
- 在使用String作为HashMap和HashSet的key时,可以确保键值唯一性
String类通过将类设置为final来确保类不会被继承,从而可以保证方法不被覆盖,因此确保了String类的所有方法都唯一被SUN的工程师设计和控制。我们在使用的过程中需要注意,千万不要用可变类型做HashMap和HashSet键值,在使用自定义的对象作为键值的时候,一定要重写HashCode和Equals方法。 -



- Integer的缓存机制
- transient : 可以防止特定的属性被序列化可以那个属性上加上这个关键字
- instanceof : 判断这个变量所属的实例对象
- volatile : 当有多个线程需要异步改变同一个变量的值时,就在那个变量前加上这个关键字
- synchronized :
- final :
- static :
- super :
- this :
-
阅读源代码
-
常用集合类的使用
-
ArrayList和LinkedList和Vector的区别
-
ArrayList : 动态数组,
查询效率高, 是Array的复杂版本, 动态的增加和减少元素,当有更多的元素加入到ArrayList中时,其大小会动态的增长。 可以使用get/set方法直接访问其中的元素,因为ArrayList的本质是一个数组。当扩容时, 一次增长50%。 -
Vector :
线程安全, 和ArrayList基本相似,区别是Vector是同步(synchronized)类。因此开销就比ArrayList要大。当扩容时, 一次扩大一倍。注意: 默认情况下ArrayList和Vector的初始容量都是10,所以如果可以预估数据量的话,分配一个较大的初始值属于最佳实践,这样可以减少调整大小的开销 -
LinkedList : 是一个双向链表,
增加删除效率高,在添加和删除元素时具有比ArrayList更好的性能,但是在查询数据时没有ArrayList 快(在数据量很大的时候)。 LinkedList还实现了Queue接口,该接口比List提供了更多的方法,例如offer(), peek(), poll()等
-
-
SynchronizedList 和Vector的区别
- Vector使用了同步方法, vector就是锁定的this对象,无法指定特定的锁定对象
- SynchronizedList同步代码块(里面嵌套了ArrayList的代码),SynchronizedList可以指定锁定的对象。
- 在使用SynchronizedList进行遍历的时候要手动加锁。
- SynchronizedList有很好的扩展和兼容功能。他可以将所有的List的子类转成线程安全的类。
-
HashMap,HashTable,concurrentHashMap 区别
- 线程安全性 : HashTable线程安全, HashMap线程不安全。concurrentHashMap是HashMap线程安全的的实现方法,将HashMap分割,对局部加锁
- HashTable不允许NULL key 和null value, HashMap允许。
- HashMap比Hashtable快,concurrentHashMap效率比HashTable要高,所以HashTable淘汰了
HashMap和ConCurrentHashMap的对比:- ConcurrentHashMap对整个桶数组进行了分割分段(Segment),然后在每一个分段上都用lock锁进行保护,相对于HashTable的syn关键字锁的粒度更精细了一些,并发性能更好。
- 而HashMap没有锁机制,不是线程安全的。
- HashMap的键值对允许有null,但是ConCurrentHashMap都不允许
-
不同版本的JDK中HashMap的实现区别和原因
-
apache集合处理工具类的使用
-
Java 8 中stream相关用法
-
枚举的用法
-
枚举与单例
-
Enum类
- IO流详解
- bio,nio和aio的区别,用法及原理
- netty
- 反射与工厂模式
- java.lang.reflect.*
- 什么是序列化与反序列化,
- 为什么序列化
- 序列化底层原理
- 序列化与单例模式
- protobuf
- 为什么说序列化不安全
- 元注解
- 自定义注解
- Java中常用注解使用
- 注解与反射的结合
- 什么是Java消息服务
- JMS消息传送模型
- java.lang.management.*
- javax.management
- 泛型与集成
- 类型排除
- 泛型中的K, T, V, E, Object等的含义是什么
- 泛型各种用法
- Junit
- Mock
- mockito
- 内存数据库(h2)
- java.lang.util.regex.*
- commons.lang
- commons.*
- guava-lnetty
- 异常类型
- 正确处理异常
- 自定义异常
- 时区
- 时令
- java中时间的API
- 解决乱码问题
- 常用编码方式
- java中语法糖原理
- 解语法糖
- 学会使用Thread, Runnable, Callable, ReentrantLock, ReentrantReadWriteLock, Atomic*, Semaphore,CountDownLatch, CouncurrenHashMap, Executors
- 自己设计线程池
- submit() 和execute()
- 死锁
- 如何排查死锁
- Java线程调度
- 线程安全和内存模型的关系
- CAS
- 乐观锁与悲观锁
- 数据库相关锁机制
- 分布式锁
- 偏向锁
- 轻量级锁
- 重量级锁
- monitor
- 锁优化,锁消除,锁粗化
- 自旋锁, 可重入锁,阻塞锁,死锁
- 死锁相关
- volatile
- happens-before
- 编译器指令重排和CPU指令重排
- volatile
- synchronized
- synchronized如何实现的
- synchronized和lock之间的关系
- 不使用synchronized和lock如何实现一个线程安全的单例
- sleep和wait
- wait和notify
- ThreadLocal
- 写一个死锁的程序
- 写代码解决生产者消费者问题
- 守护线程
- 守护线程和非守护线程的区别以及用法
- 用位运算实现加减乘除和取余
- 单例
- 策略
- 工厂模式
- 适配器模式
- 责任链
- 三次握手与四次关闭
- 流量控制与拥塞控制
- OSI七层模型
- tcp粘包与拆包
- cookie被禁用时如何实现session
- 实现客户端缓存功能,支持返回304
- 实现可并发下载一个文件
- 使用线程池处理客户端请求
- 使用nio处理客户端请求
- 支持简单的rewrite规则
- 上述功能在实现的时候需要满足
开闭原则
- Springboot的starter原理
- 自己实现一个starter
- lambda表达式
- Stream API
- Jigsaw
- Jshell
- Reactive
- Streams
-
局部变量类型推断
-
GC的并行Full GC
-
ThreadLocal握手机制
- 线程Dump
- 内存Dump
- GC情况
- 分析死锁
- 分析内存泄漏
- HeapOurOfMemory , Young OutOfMemory, MethodArea OutOfMemory,
- ConstantPool OutOfMemory, DirectMemory OutOfMemory,
- Stack OutOfMemory, Stack overflow
- 内存溢出
- 线程死锁
- 类加载冲突
- 当一个java程序响应很慢时如何查找问题
- 当一个java程序频繁FullGC时如何解决问题
- 如何查看垃圾回收日志
- 当一个Java应用类发生OutOfMemory时该如何解决
- 如何判断是否出现死锁
- 如何判断是否存在内存泄漏
- 如何查看执行计划
- 如何根据执行计划进行sql优化
- sql优化
- 事务
- 事务的隔离级别
- 事务能不能实现锁的功能
- 数据库锁
- 行锁
- 表锁
- 使用数据库实现乐观锁
- 数据库主备搭建
- binlog
- 内存数据库 h2
- 常用的nosql数据库
- redis
- memcached
- MongoDB
- 分别使用数据库锁,nosql实现分布式锁
- 性能调优
- 基本概念
- 常见用法
- 在linux上部署solr,solrcloud,新增, 删除,查询索引
- 在linux上部署Storm,用zookeeper做协调,运行storm hello world,local和remote模式运行调试storm topology
- HDFS
- MapReduce
- XSS的防御
- SQL注入
- XML 注入
- CRLF注入
- MD5,SHA1, DES, AES,RSA,DSA
- memcached为什么可以导致DDOS攻击
- 什么是反射性DDOS
- 2PC,3PC,CAP,BASE,可靠消息最终一致性,最大努力通知, TCC
- 服务注册, 服务发现,服务治理
- 怎样打造一个分布式数据库
- 什么时候需要分布式数据库
- mycat, otter, HBase
- mfs, fastdfs
- 缓存一致性,缓存命中率,缓存冗余
- 数据一致性
- ActiveMQ
- CPU, 内存, 磁盘I/O ,网络I/O等
- 进程监控,语义监控 , 机器资源监控,数据波动
- 日志,埋点