梦泽是一个专注于计算机图形学原理的实验性项目。它的核心目标是完成计算机图形(CG)的相关作业,同时具备良好的可扩展性,以便进行各种图形学实验。
项目使用Vulkan作为后端,通过ImGui实现交互功能,基础应用框架(窗口、输入事件、日志)改自WalnutAppTemplate。来自WalnutAppTemplate的内容全部位于mengze/core。
梦泽使用Vulkan作为图形处理API,但故意不使用Vulkan的标准图形管线。梦泽自定义渲染处理,将渲染结果写入自定义数组交由vulkan显示,而非依赖Vulkan的预设管线。
在根目录依次运行以下命令。要求windows x64平台,vs2022,cmake3.16。
cmake -G "Visual Studio 17 2022" -A x64 -S . -Bbuild/
cmake --build build --config Release --target mengze
.\build\mengze\Release\mengze.exe
多重重要性采样
并行构建BVH
并行渲染,在只使用CPU的情况下,10万面片,10次弹射,1024x1024分辨率每像素采样一次只需要30-40毫秒
三角形求交使用Moller-Trumbore算法
使用累积的方式,每一次采样都可以实时看到效果,且每一帧都有进度显示
可交互,按住鼠标右键可以使用鼠标和Q,W,E,A,S,D键漫游场景,每次转换视角都会重新开始采样,文件中有演示视频。
共实现了四种材质,只有漫反射的Lambertian材质,Phone模型材质,没有漫反射的金属材质和有折射的模拟玻璃的电介质材质。前两者具有和brdf相关的pdf,可以根据pdf采样并调整权重确保收敛。后两者不使用pdf,直接采样光线。
最开始时考虑使用GPU实现,所以所有计算都使用了32位浮点数。遇到了一些精度问题,在有累乘累加的地方考虑了使用数值稳定的算法,多次Bonce的舍入问题通过俄罗斯轮盘赌解决,但仍然存在一些问题。



3092三角形数,BVH构建时间22毫秒。
该场景光源面片数量多,目前的实现方式使用光源重要性采样会严重拖慢性能。
无光源重要性采样:100samples,23秒
多重重要性采样:40samples ,2分6秒
多重重要性采样:100samples,5分17秒
可以看到使用光源重要性采样,时间增加了12倍,但是多重重要性采样的效果也很明显。40个样本的效果远好于不使用光源重要性采样100个样本。
其他场景,加入光源重要性采样对时间的影响不大。


102988三角形数,BVH构建时间31秒
该场景只有Lambertian材质
100samples,38秒
300samples,1分53秒



592188三角形数,BVH构建时间1分10秒
样图的纹理的y轴应该是反的,我在绘制时将其调正。
之前墙壁有不正确的黑影,怀疑是因为32位浮点数精度不够,多次乘法导致舍入,加入俄罗斯轮盘赌之后黑影消失。但窗框有不正常的黑色,目前判断可能是因为三角形太小,而我使用32位浮点数精度太低,导致相交判断错误。因为时间原因没来得及验证和修复。
100samples,5分32秒
300samples,16分40秒
去年作业的场景,上图效果只需要10分钟。

mengze/hidden_surface文件夹下,共有四种实现方式:
Z buffer:基于重心坐标插值的z-buffer算法;Scanline z buffer:课上介绍的扫描线z-buffer算法;Hierarchical z buffer:课上介绍的层次z-buffer算法;Hierarchical z buffer with octree:课上介绍的使用八叉树的层次z-buffer算法
层次z-buffer实现,可以在200万三角面片的场景中实时漫游。 以下对各个算法的类和设计思路进行介绍。
- 功能说明: Rasterizer类作为面消隐算法的基础,负责处理从世界空间到屏幕空间的顶点映射、处理相机视角和分辨率的实时调整、以及简化的漫反射着色。此类为所有面消隐算法提供了一个共同的框架。
- 性能统计:
vertex_transform_time:从世界空间到屏幕空间的时间rasterization_time:从屏幕空间到完整写入自定义数组的时间,该时间也是用于衡量各个算法效率的时间。
- 虚函数 (子类通过这三个函数实现自己的面消隐算法):
render_triangle():核心方法,用于渲染单个三角形。resize_depth_buffer(width, height):调整深度缓冲区的大小以适应不同的分辨率。reset_depth_buffer():重置深度缓冲区以准备下一帧的渲染。
- 功能说明: 此类负责解析OBJ格式的文件,提供两种输出格式:一种是直接输出三角形,另一种是输出所有顶点和索引。后者用于构建空间分割结构如八叉树,从而优化渲染和查询性能。
扫描线z-buffer算法涉及多个的数据结构,如分类多边形表、分类边表、活化多边形表、活化边对等。这些结构虽然在逻辑上清晰,但对于客户端而言,它们构成了一个相对复杂的心智模型。(客户端在这里指的是使用这些数据结构的类或方法)在实际应用中,客户端通常只关心每条扫描线上的交点位置、相应的深度值及其增量,而不需要深入理解背后的复杂结构。 为了简化这一过程,梦泽对扫描线z-buffer算法中的这些数据结构接口进行了重写。这一改写的目的是将复杂性封装在内部,减少客户端需要处理的信息量。通过这种方式,客户端可以更直接地获取关键信息,如扫描线与多边形的交点、深度值和深度值的增量,而不必关心数据结构的内部工作原理。
只有一个公开函数:find_intersections。给定扫描线会返回扫描线与该多边形的交点的x值,左端点的深度值,以及深度值增量。相当于ppt中存放投影多边形边界与扫描线相交的边对的活化边表。其内部会存放斜率等信息用于增量更新。因为都是三角形,只有三条边,可以快速处理交点,所以不再区分多边形和边队。
相当于分类边表和分类多边形表,仅有一个公开函数,接受三角形,将三角形处理成Polygon放入其中,并可以在之后通过y轴坐标值快速索引Polygon。
活化多边形表。与PolygonStorage使用链表维护当前活跃的Polygon。
利用以上结构实现了具体的render_triangle方法。提供两个额外的统计量:find_intersections_time累计每一帧Polygon用于寻找交点的时间,construct_time 用于统计构造PolygonStorage的时间(即计算斜率、屏幕方程、增量等的时间)
我所实现的层次z-buffer没有使用四叉树,而是通过对坐标进行位运算快速定位所处的层级和坐标。光栅化使用了重心坐标插值,并优化了插值的数值计算。 使用插值的原因有两个,一是使用层次z-buffer本来就要求多边形的轴对齐边界,二是使用优化后的插值算法在现代cpu上速度比扫描线算法快很多。 关于八叉树,为了实现实时交互,我构建的是世界空间的八叉树,这样就只需要构建一次。在每一帧都将八叉树转换到屏幕空间进行剔除。
DepthMipmap类提供多层级z-buffer结构,主要功能由两个方法实现。 update_depth方法更新所有层级的深度值,会提前退出避免无效更新。 is_occluded方法传入屏幕空间的边界顶点以及一个深度值,判断整个多边形是否被遮挡。
OctreeNode 是一个用于构建八叉树的类,包含空间边界(通过 BoundingBox 定义)、存储的三角形索引(triangle_indices),以及最多8个子节点。
主要操作有三个:
- 插入操作 (
insert): 将三角形索引加入节点,如果节点超载,则触发细分。 - 细分操作 (
subdivide): 当节点中的三角形数量超过设定阈值时,节点会分裂成8个子节点,以更细致地管理空间。 - 计算边界盒 (
compute_triangle_bounding_box): 为节点中的三角形计算边界盒,用于空间定位和管理。
遍历并检查所有三角形,构造世界空间的八叉树。
普通模式和完整模式的层次z-buffer共用同一个Rasterizer类,因为他们使用相同的DepthMipmap,只不过后者多一个基于八叉树的剔除。
- 性能统计:
octree_construct_time:构造八叉树的时间octree_to_screen_space_time:将八叉树转换到屏幕空间的时间
按住鼠标右键可以使用鼠标和Q,W,E,A,S,D键漫游场景。可以实时更换不同的方法,特殊的方法会有一些特殊的统计量,如八叉树构造时间。
所有窗口可以进行任意docking。
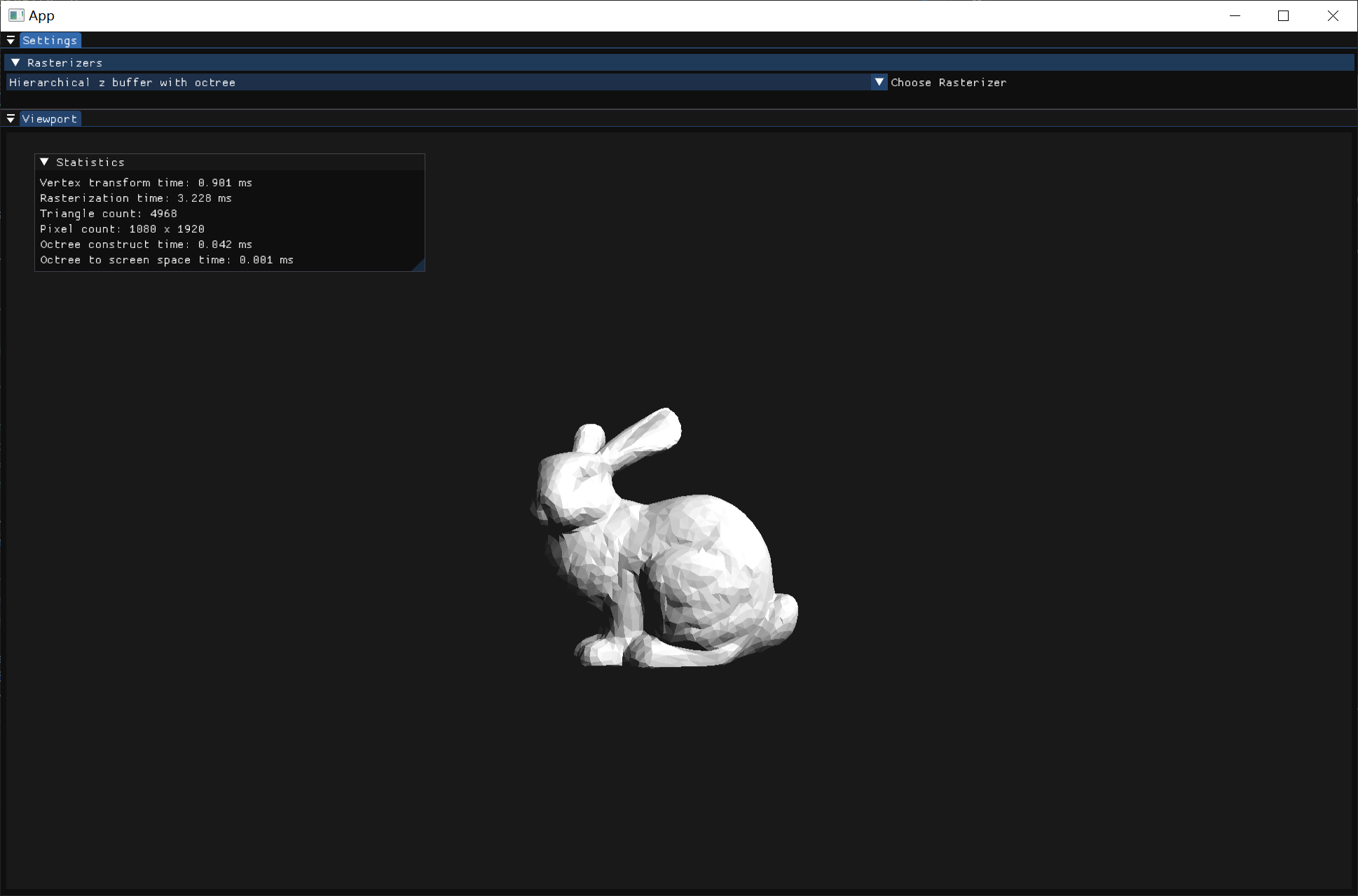
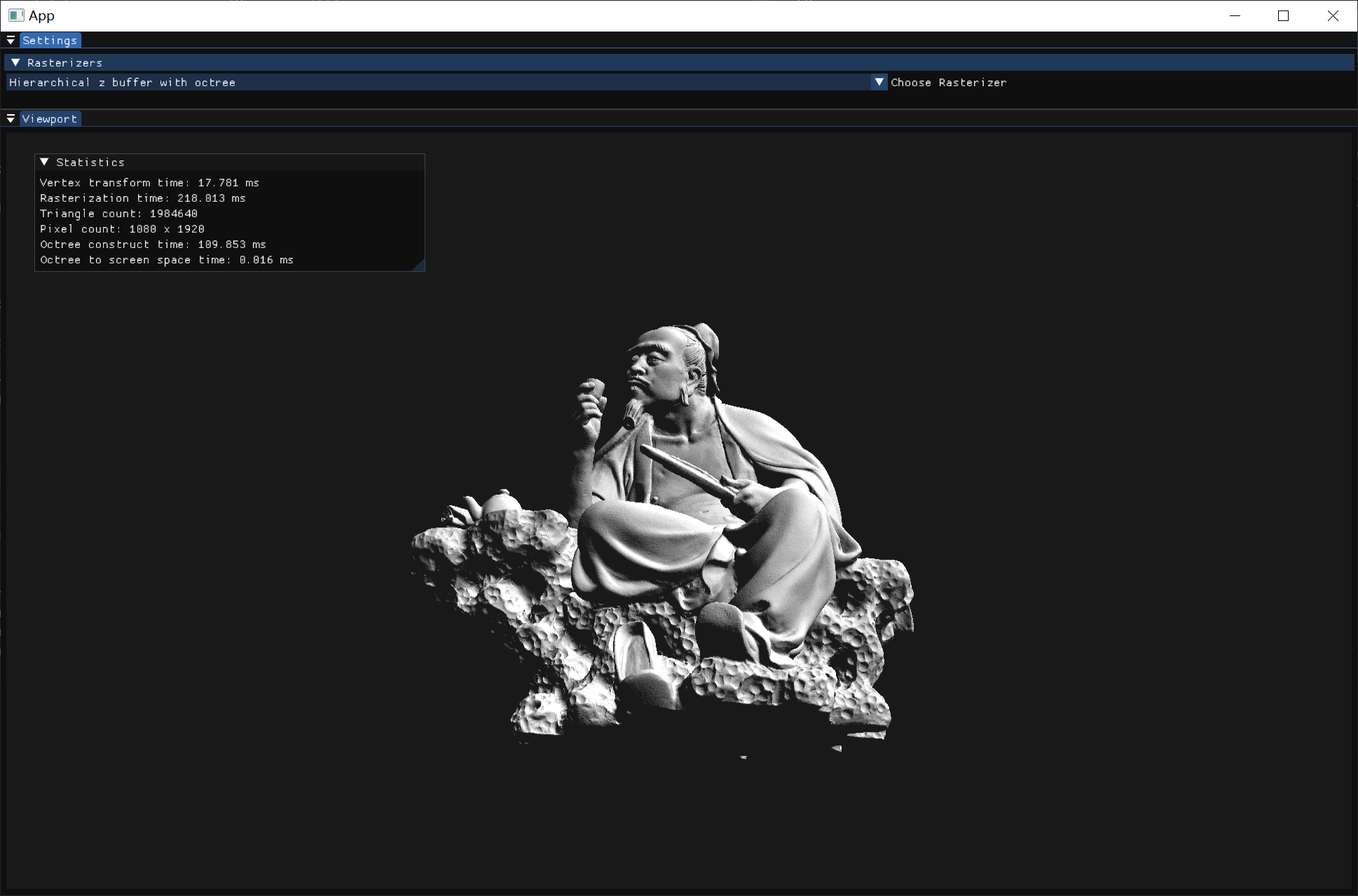
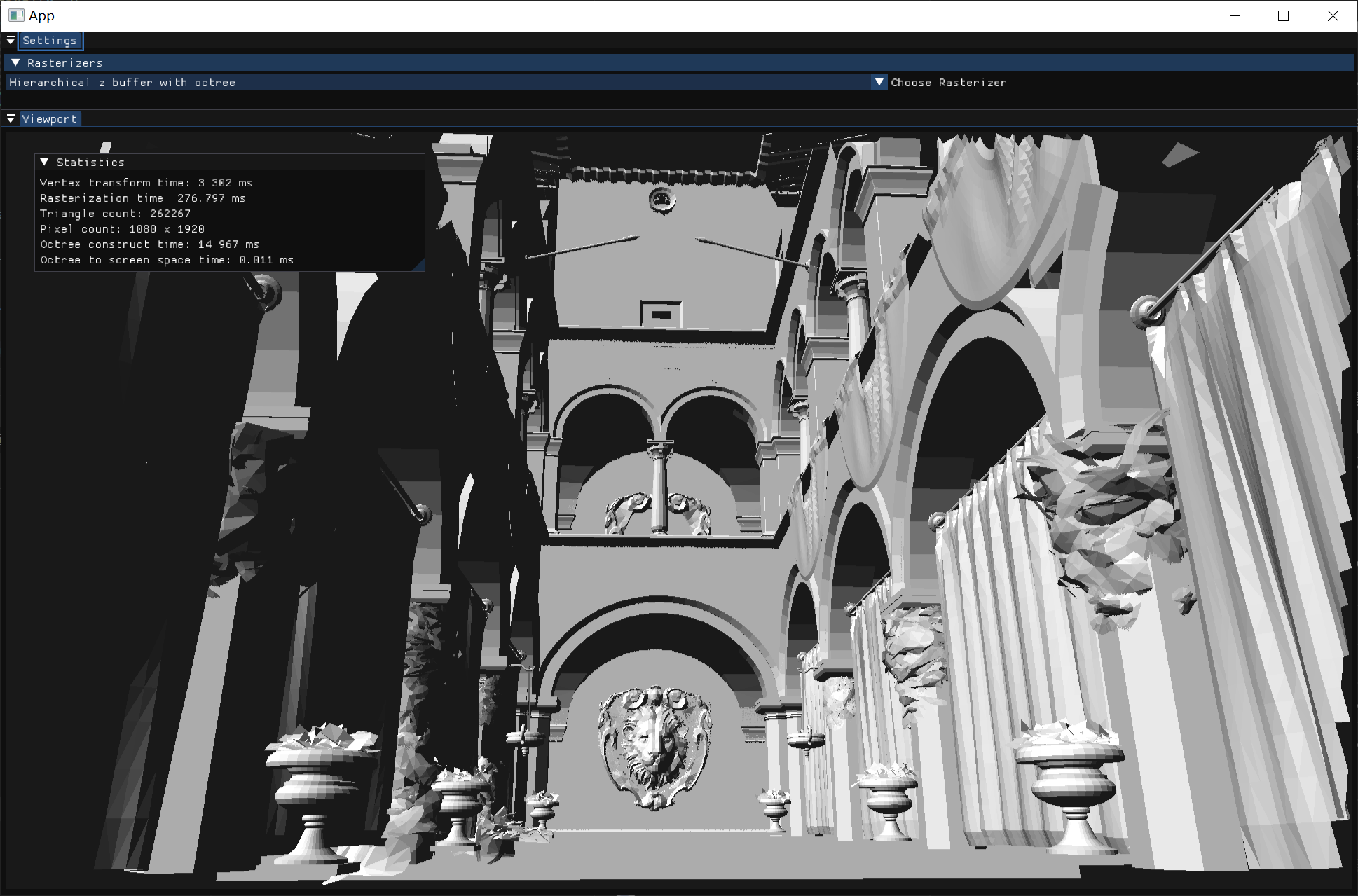
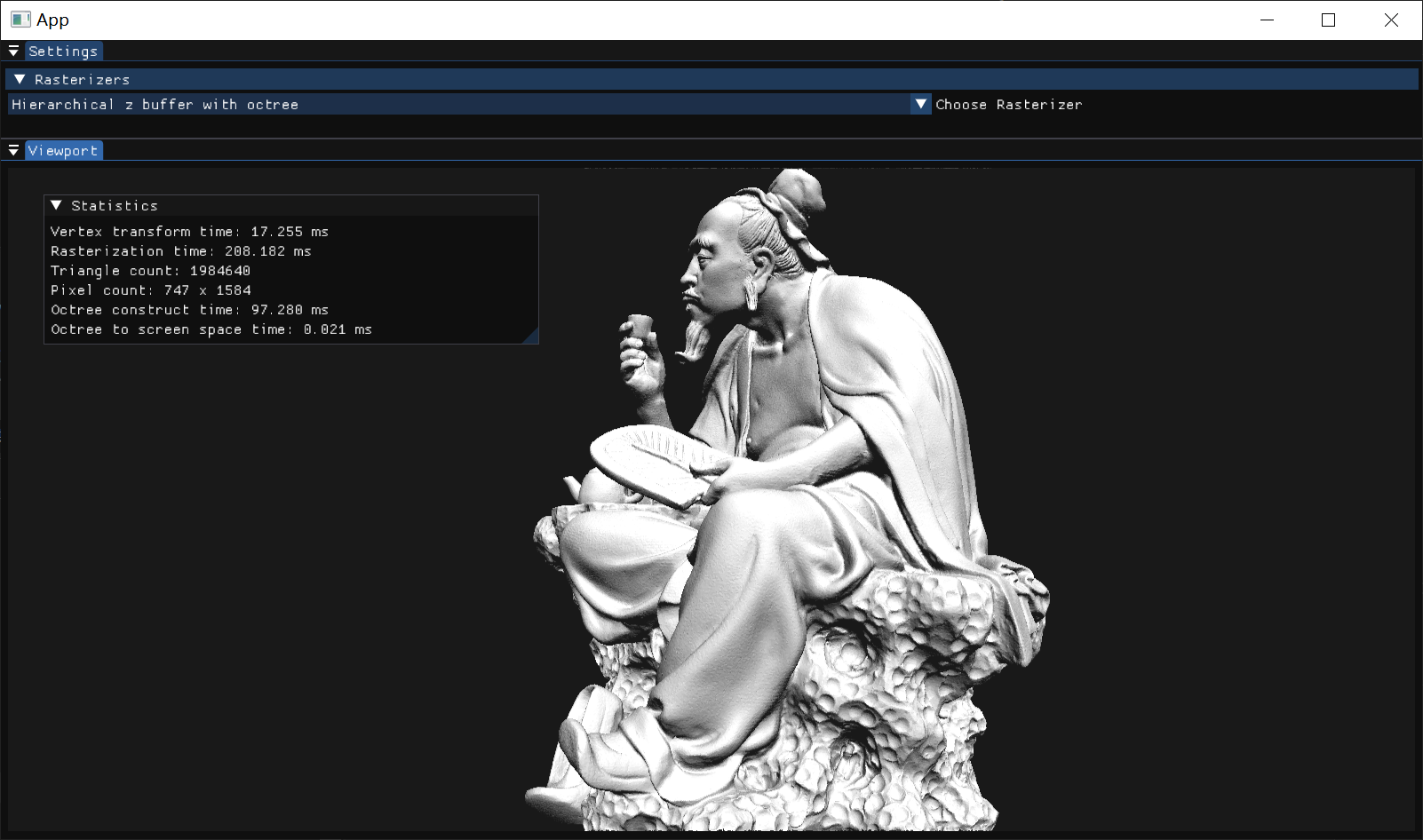
| 三角形:4968 | 三角形:1984640 | 三角形:262267,少量遮挡 | 三角形:262267,大面积遮挡 | |
|---|---|---|---|---|
| 扫描线 z-buffer | 7.6ms | 720ms | 337ms | 145ms |
| 层次 z-buffer 普通模式 | 3.2ms | 260ms | 202ms | 76ms |
| 层次 z-buffer 完整模式 | 3.2ms | 218ms | 276ms | 96ms |
| Z buffer | 2.5ms | 190ms | 132ms | 72ms |
注:三角形数太多后时间变化幅度较大,以上数据是取下四分位数。 由于我使用的光栅化方式非常高效,查询层次深度的时间常数远大于光栅化的时间常数,而深度mipmap的实现也比较高效,遍历八叉树的时间常数又远大于查询深度mipmap。所以不使用任何其他结构的z-buffer算法总是最快的。
| 少量遮挡 | 大面积遮挡 | |
|---|---|---|
| 扫描线 z-buffer | 2.6 x baseline | 2.0 x baseline |
| 层次 z-buffer 普通模式 | 1.5 x baseline | 1.1 x baseline |
| 层次 z-buffer 完整模式 | 2.1 x baseline | 1.3 x baseline |
不过,将最优实现的时间作为baseline分析最后两列,当遮挡关系复杂时,层次z-buffer有非常可观的加速。
而完整模式的层次z-buffer在三角形面片数量最多时,也最接近baseline,即1.1 x baseline。