

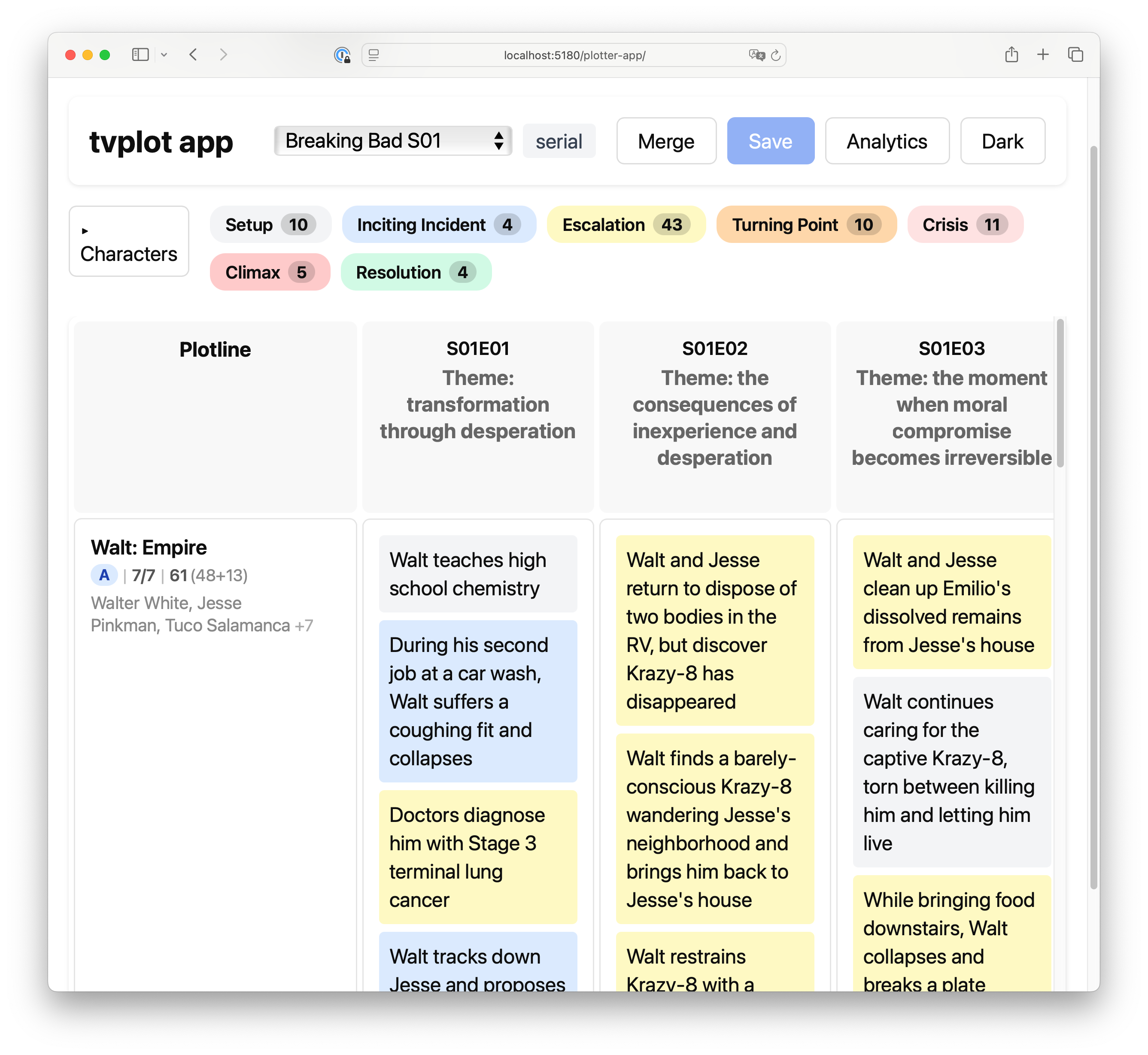
Turn episode synopses into a writers' room corkboard — story engine, plotlines with their story DNA and arcs (see glossary) — in one function call.
For TV researchers, screenwriters, and anyone building narrative analysis tools or a tv series.
A naive LLM prompt covers 5–12% of a season's source material. tvplot covers 78–91% — by separating what the model looks for (narrative theory) from how it calculates the results (code).
Library / CLI — pip install tvplot, point it at synopsis files, get JSON.
Standalone HTML viewer — one self-contained .html file that runs the whole pipeline in your browser. Type a show name, the viewer asks the LLM for synopses, runs the analysis, and renders the grid. No server, no dependencies — download the file and it works.
pip install tvplot
export ANTHROPIC_API_KEY=sk-ant-…Working on your own series? Point it at your synopses — one .txt file per episode (see Input format):
tvplot run my-series/Want to analyze an existing show? The optional writer extension generates synopses from online sources:
pip install 'tvplot[writer]'
tvplot write-synopses "Mad Men" --season 1
tvplot run mad-men/Generate a standalone HTML viewer alongside the JSON:
tvplot run mad-men/ --html # writes mad-men.json + mad-men.html
tvplot run mad-men/ --html-output viewer.htmlMultiple seasons are supported — plotline continuity is tracked across seasons (see Python API).
Pre-computed results are in examples/results/ — explore the output without spending API credits.
python -m tvplot.html.build --output tvplot.html
open tvplot.htmlThen in the browser:
- Click LLM in the toolbar, paste your Anthropic or OpenAI key, pick an analysis system.
- On the welcome screen, type a show name and season → click Analyze.
- The viewer asks the model for episode synopses, lets you preview/edit them, and runs the pipeline.
- Export the result as JSON, CSV, Final Draft (
.fdx), or PDF.
If the model doesn't know the show, drop your own .txt synopsis files via the + Load button.
One JSON file per season. Each contains:
- Cast — characters with aliases
- Plotlines — with A/B/C ranking, Story DNA (hero, goal, obstacle, stakes), and episode span
- Events — per-episode, assigned to plotlines with episode-level function and season-level arc function
Example: Breaking Bad S01 (truncated)
{
"context": {
"format": "serial",
"story_engine": "A high school teacher builds a drug empire, testing how far he'll go for family and survival"
},
"cast": [
{"id": "walt", "name": "Walter White", "aliases": ["Walt", "Heisenberg", "Mr. White"]},
{"id": "jesse", "name": "Jesse Pinkman", "aliases": ["Jesse"]}
],
"plotlines": [
{
"id": "empire",
"name": "Walt: Empire",
"hero": "walt",
"goal": "build a drug business to secure his family's financial future",
"obstacle": "inexperience with criminal world, violent dealers like Tuco, moral boundaries",
"stakes": "death, loss of family, imprisonment",
"rank": "A",
"span": ["S01E01", "S01E02", "...", "S01E07"]
}
],
"episodes": [
{
"episode": "S01E01",
"theme": "transformation through desperation",
"events": [
{
"event": "During the meth lab raid, Walt spots his former student Jesse escaping through a window",
"plotline_id": "empire",
"function": "inciting_incident",
"plot_fn": "inciting_incident",
"characters": ["walt", "jesse"]
}
]
}
]
}You pick an analysis system with --system (CLI) or the LLM Settings dialog (viewer). Both systems share the same input format and output the same TVPlotlinesResult shape, so the viewer renders either one.
Story DNA — hero, goal, obstacle, stakes — and Freytag's seven dramatic functions. Five LLM passes:
| Pass | Role | Output | Calls |
|---|---|---|---|
| 0 | Context detection | Format (serial/procedural/ensemble), genre, story engine | 1 |
| 1 | Plotline extraction | Cast + plotlines with Story DNA | 3 (majority vote) |
| 2 | Event assignment | Events mapped to plotlines with narrative functions | 1 per episode |
| 3 | Structural review | Verdicts: merge, reassign, create, drop, refunction | 1 |
| 4 | Arc functions | Season-level arc function for each event (per plotline) | 1 per plotline |
Pass 1 runs 3× in parallel and picks the most common plotline set. Pass 3 sees the full picture no earlier pass had and corrects structural problems. Pass 4 assigns arc-level functions — an event that was a climax in episode 3 might be an escalation in the season-long arc.
Bal's three layers, Greimas's actant model (subject/object/helper/opponent/power/receiver), Bremond's narrative cycle, Labov's reportability. Six LLM passes:
| Pass | Role | Output | Calls |
|---|---|---|---|
| 1 context | Format, story schema, breach, protagonists | Show-level context | 1 |
| 2 fabula | Per-episode events as state transitions, with stable ids | Bare events + cast | 1 per episode |
| 3 actants | Plotlines via the actant model (anti-subject test) | Plotlines | 1 |
| 4 story | Per-event episode function and direction; theme | Story-level event tags | 1 per episode |
| 5 arc | Season arc function, drive vs texture, MRE per plotline | Season-level event tags | 1 per plotline |
| 6 review | Verdicts and ranks | Structural corrections | 1 |
The actant fields (who_chases, what_they_chase, stands_in_the_way, who_wins_if_it_works) map onto the same hero / goal / obstacle / stakes slots, so existing tools that consume TVPlotlinesResult see no schema change.
The schema document at docs/layered-schema.md describes a richer base + layers JSON form for keeping multiple systems' analyses of the same season side by side.
The writer extension collects raw episode data from online sources, then rewrites each episode into a full synopsis via LLM — ensuring every sentence is a beat (conflict or change), with explicit causality and character names.
Tested with Claude Sonnet (default). OpenAI and Ollama supported for both pipelines and both analysis systems. Ollama defaults to Qwen 2.5 14B — chosen to run on CPU without a GPU. Quality is noticeably lower than cloud models but works for experimentation.
One .txt file per episode. Include S01E01, S01E02, etc. in the filename. Each file is a plain-text synopsis — 150–500 words covering the main events.
breaking-bad/
├── S01E01.txt
├── S01E02.txt
└── S01E07.txt
The folder name becomes the show title. Override with --show:
tvplot run got/ --show "Game of Thrones"from tvplot import get_plotlines
s01 = get_plotlines("Breaking Bad", season=1, episodes=season_1_synopses)
s02 = get_plotlines("Breaking Bad", season=2, episodes=season_2_synopses, prior=s01)
# Or pick the analysis system explicitly
result = get_plotlines(
"Mad Men", season=1, episodes=synopses, system="narratology",
)Pass prior to track plotline continuity across seasons.
tvplot run breaking-bad/ # Anthropic (default)
tvplot run breaking-bad/ --provider openai # OpenAI
tvplot run breaking-bad/ --provider ollama # Ollama (local, free)
tvplot run breaking-bad/ --system narratology # narratology pipelineSee docs/api.md for full API reference.
- Plotline — a narrative thread across episodes (e.g. "Walt: Empire")
- Story DNA — hero, goal, obstacle, stakes (hollywood) ↔ subject, object, opponent, receiver (narratology)
- A/B/C ranking — plotline weight (A = main, B = secondary, C = tertiary, runner = minor thread)
- Format — procedural (House), serial (Breaking Bad), hybrid (X-Files), ensemble (Game of Thrones)
- Story engine — one sentence capturing the show's core dramatic mechanism
- Function — episode-level role in a plotline arc (setup, inciting_incident, escalation, turning_point, crisis, climax, resolution; narratology adds
recognition) - Arc function — season-level role of the same event
tvplot calls either Claude (Anthropic) or GPT (OpenAI) — you pick one per run — to produce its analyses. If your application surfaces this library's output to end users, you're responsible for disclosing the AI involvement to them (EU AI Act Art. 50; Anthropic AUP; OpenAI Usage Policies). The standalone HTML viewer shipped here carries that notice in its footer.
docs/ai-disclosure.md— what gets sent where, and to whom. Alpine Animation (Switzerland) publishes the library and collects no data; your API key and inputs travel directly from your machine to the LLM vendor you pick.docs/methodology.md— plain-language description of how the pipeline decides, what it can't do, and where to find the code for each step.
Outputs are AI-generated and can contain hallucinations. Treat them as a starting point for your own analysis, not a verified source.
@software{tvplot2026,
author = {Vashko, N.},
title = {tvplot: LLM-Driven Plotline Extraction from Episode Synopses},
year = {2026},
url = {https://github.com/BirdInTheTree/tvplot}
}MIT