Insertion of duplicated Data #1621
Description
Hi.
I have a cluster of 4 machines with clickhouse installed and I want to do a Replicated and distributed table between them. I want to execute a query in all the machines so I did the next configuration:
- 4 shards
- 2 replicas by shard

So the config file is:
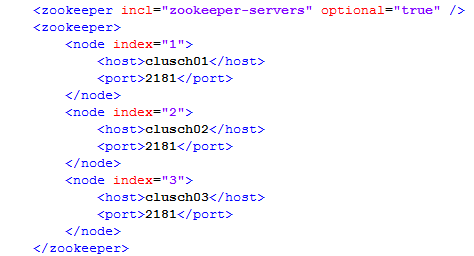
I have a cluster of zookeepers installed in three of the machines:
**CREATION MERGETREE TABLE
This is the creation of the table that I run in all the servers**
CREATE TABLE TEST_DB.Test_Table (
Md5 FixedString(32),
InsertionDate Date,
EventDatetime DateTime,
Field1 UInt8,
Field2 UInt8
) ENGINE = MergeTree(InsertionDate, (Md5, InsertionDate), 8192)
And in the clusch04, I create the distributed Table.
CREATE TABLE TEST_DB.Test_Table_dist AS Test_Table ENGINE = Distributed(tlevents, TEST_DB, Test_Table, rand())
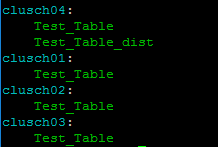
As Result, I have this:
INSERTION DATA:
I have a file with 100 unique rows that I going to Insert with the clickhouse-client.
wc –l TestFile.txt
100 202 7299 TestFile.txt
And I import the file with the clickhouse-client to the distributed table
clickhouse-client --database="TEST_DB" --query="INSERT INTO TEST_DB.Test_Table_dist FORMAT CSV" < TestFile.txt
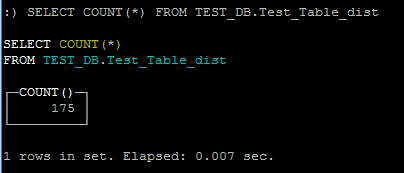
If I do a COUNT(*) on the Distributed Table:
If I do a COUNT(*) on the MergeTree Table:
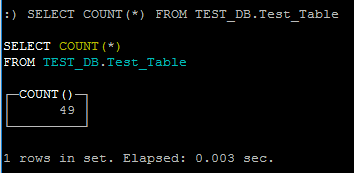
Why If I inserted 100 rows now I have 175 rows inserted??
If I do the query in all the servers:
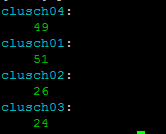
- Is the data really Replicated? How can I check this?
- It seems that the data is well distributed
- But, I have duplicated data. I have 100 rows but the client insert 175 rows!!!
Do I have an error?? Where? In the configuration?? Is there any error in clickhouse?
If you need more information, do not hesitate to tell me.
Regards.