Standing on the shoulders of giants..
This markdown file (which is always a work in progress) helps me revise many of the topics that i've covered over the last 12 years in the area of software development. It includes links to some of my favourite articles / resources as well as some short write ups of my own interpretations of many topics / concepts that i've encountered along the way.
Some of my favourite websites / blogs
- https://devchat.tv - Devchat.tv Developer Podcasts
- https://github.com/dypsilon/frontend-dev-bookmarks - Frontend development bookmarks
- https://css-tricks.com/ - CSS Tricks
- https://developer.mozilla.org/en-US/docs/Web - Mozilla Developer Network
- http://www.tutorialspoint.com/ - Tutorialspoint
- https://www.smashingmagazine.com/ - Smashing Magazine
- https://tympanus.net/codrops/ - Tympanus Codrops
- https://www.toptal.com/developers/blog - Toptal
- https://blog.nrwl.io/ - Cutting edge Angular and Node.js Development
- https://egghead.io/ - Egghead (Web development tutorials)
- https://blog.risingstack.com - Risingstack - Node.js Development Blog
- https://flaviocopes.com/ - Flavio Copes (Frontend development).
- https://toddmotto.com/ - Todd Motto (Angular).
- https://johnpapa.net/ - John Papa
- https://angular-university.io/my-courses - Angular University
- https://www.pluralsight.com - Pluralsight
- https://github.com/gothinkster/realworld - Real World apps by Thinkster
- https://dzone.com/ - Dzone - Great articles on devops
- https://auth0.com/blog/ - Auth0 Blog
- https://christianlydemann.com/blog/ - Christian Ludemann Angular Blog
- HTML (Hyper-Text Markup Language)
- CSS (Cascading Style Sheets)
- XML (Extensible Markup Language)
- Fonts / Typography on the Web
- Audio for the web
- Video for the web
- Images on the Web
- Bandwidth Optimization for Web Applications
- Multimedia
- State Management for Web Applications
- Semantic Web Applications - HTML Ontologies / Schemas - Javascript Ontologies / Schemas
- Web Components
- Responsive Web Applications
- IDE (Integrated Development Environments)
- Web Servers
- Cloud Architecture
- Serverless Architecture
- Micro services & Distributed Systems
- Docker and DevOps
- Security
- Node.js
- Typescript
- Angular
- Learning resources
- Other concepts
- Useful Angular Packages and Modules
- Enterprise Angular applications with Nx (I highly recommended this)
- State Management with NgRX for Angular.
- Other state management solutions for Angular
- Angular Module / Folder Organisation Best Practices
- Angular Unit Testing
- Angular End to End Testing
- Angular Documentation Tools
- Angular Reporting Tools
- Progressive Web Applications
- Build Tools for Web Applications
- Browser Build Optimization
- Progressive Browser Functionality
- Version Control
- Continuous Deployment / Integration / Delivery
- Provisioning Tools / Virtualization / Snapshots
- Install Docker and Kitematic
- Helpful Docker commands and code snippets
- Kubernetes Container Orchestration
- Removing friction from the development workflow
- Software Development and Testing Strategies
- Networking
- Databases
- Release Management
- Coding Standards
- Scaling applications for Enterprise use and large traffic
- Software Logging
- Software Monitoring
- Software Message Queuing
- IT Law
- Team Management and Approaches
- ODATA (Open Data Protocol) API Development
- REST (Representational State Transfer) API Development
- JAVA Development
- PHP Development
- Ruby on rails development
- C# Development
- Blockchain Development
- Videos
- Virtual Reality
- How to Close a Port in Windows
- Useful CLI Commands
Organisations
- W3C https://www.w3.org/
- IEEE https://www.ieee.org/
- IETF https://www.ietf.org/
- ICANN https://www.icann.org/
Common Abbreviations
- IAB (Internet Architecture Board)
- IANA (Internet Assigned Numbers Authority)
- ICANN (Internet Corporation for Assigned Names and Numbers)
- IESG (Internet Engineering Steering Group)
- IETF (Internet Engineering Task Force)
- IRTF (Internet Research Task Force)
- ISOC (Internet Society)
- W3C (World Wide Web Consortium)
Protocols and Standards
- HTTP 2 Guide - https://httpd.apache.org/docs/trunk/howto/http2.html
- OSI Model - https://www.webopedia.com/quick_ref/OSI_Layers.asp
- IETF Standards and Guidelines - https://wordtothewise.com/wisewords/internet-protocols-standards/
- FTP - https://tools.ietf.org/html/rfc959
- SMTP – Simple Mail Transfer Protocol - https://tools.ietf.org/html/rfc5321
- MIME – Multipurpose Internet Email Extensions - https://tools.ietf.org/html/rfc2045
- SSL - The Secure Sockers Layer https://tools.ietf.org/html/rfc6101
Markdown reference https://github.com/adam-p/markdown-here/wiki/Markdown-Cheatsheet
Hypertext Markup Language (HTML) is the standard markup language for creating web pages and web applications. With Cascading Style Sheets (CSS) and JavaScript, it forms a triad of cornerstone technologies for the World Wide Web.
- W3C Specification https://www.w3.org/TR/html52/
HTML 5 API Overview (Handy reference) https://platform.html5.org/
"Added in HTML5, the HTML element can be used to draw graphics via scripting in JavaScript. For example, it can be used to draw graphs, make photo compositions, create animations or even do real-time video processing or rendering." by Mozilla Developer Network
https://github.com/raphamorim/awesome-canvas#readme - Curated resource for working with the HTML 5 Canvas Element
Cascading Style Sheets (CSS) is a style sheet language used for describing the presentation of a document written in a markup language like HTML.
- W3C Specifications https://www.w3.org/Style/CSS/specs.en.html
A 2018 Guide to CSS layouts https://www.smashingmagazine.com/2018/05/guide-css-layout/ Browser Media Queries https://developer.mozilla.org/en-US/docs/Web/CSS/Media_Queries/Using_media_queries
Bootstrap https://getbootstrap.com/docs/4.0/getting-started/introduction/ Foundation https://foundation.zurb.com/ Bulma https://bulma.io/ UIkit https://getuikit.com/ Semantic UI https://semantic-ui.com/
A CSS preprocessor is a program that lets you generate CSS from the preprocessor's own unique syntax. There are many CSS preprocessors to choose from, however most CSS preprocessors will add some features that don't exist in pure CSS, such as mixin, nesting selector, inheritance selector, and so on.
https://sass-lang.com/documentation - Documentation https://medium.com/@andrew_barnes/bem-and-sass-a-perfect-match-5e48d9bc3894 - BEM (Block Element Modifier)
http://lesscss.org/features/ - Documentation
Stylus simplifies your CSS Syntax to an indented format with a lot of extra features!
- Optional colons
- Optional semi-colons
- Optional commas
- Optional braces
- Variables
- Interpolation
- Mixins
- Arithmetic
- Type coercion
- Dynamic importing
- Conditionals
- Iteration
- Nested selectors
- Parent referencing
- Variable function calls
- Lexical scoping
- Built-in functions (over 60)
- In-language functions
- Optional compression
- Optional image inlining
- Stylus executable
- Robust error reporting
- Single-line and multi-line comments
- CSS literal for those tricky times
- Character escaping
- TextMate bundle
- BEM (Block Element Modifier) http://getbem.com/introduction/
- ITCSS https://github.com/ahmadajmi/awesome-itcss
Conditional CSS Support Checks https://www.lottejackson.com/learning/supports-will-change-your-life CSS Mixins https://css-tricks.com/custom-user-mixins/
Javascript from scratch https://javascript.info/
https://github.com/wbinnssmith/awesome-promises#readme
https://github.com/standard/awesome-standard#readme
https://github.com/maxogden/maintenance-modules#readme
https://github.com/sindresorhus/awesome-observables#readme
Extensible Markup Language is a markup language that defines a set of rules for encoding documents in a format that is both human-readable and machine-readable. The W3C's XML 1.0 Specification and several other related specifications—all of them free open standards—define XML
A list of popular XML Schemas used on the web https://en.wikipedia.org/wiki/List_of_types_of_XML_schemas
In my opinion the best and most concise article on XML https://www.service-architecture.com/articles/xml/index.html
Mozilla Web Fonts Guide https://developer.mozilla.org/en-US/docs/Learn/CSS/Styling_text/Web_fonts https://github.com/deanhume/typography#readme - Curated list of resources for working with Web Typography
Mozilla Web Audio Guide https://developer.mozilla.org/en-US/docs/Web/API/Web_Audio_API
Mozilla Video Web Guide https://developer.mozilla.org/en-US/docs/Learn/HTML/Multimedia_and_embedding/Video_and_audio_content#Audio_and_video_on_the_web
https://kinsta.com/blog/optimize-images-for-web/ - How to opimize images for the web and performance
PNG (pronounced ping as in ping-pong; for Portable Network Graphics) is a file format for image compression that, in time, is expected to replace the Graphics Interchange Format (GIF) that is widely used on today's Internet.
JPEG is a commonly used method of lossy compression for digital images, particularly for those images produced by digital photography. The degree of compression can be adjusted, allowing a selectable tradeoff between storage size and image quality.
Scalable Vector Graphics (SVG) is an XML-based vector image format for two-dimensional graphics with support for interactivity and animation. The SVG specification is an open standard developed by the World Wide Web Consortium (W3C) since 1999. SVG images and their behaviors are defined in XML text files.
https://github.com/willianjusten/awesome-svg#readme - Curated resources on SVG images for the web.
HTML responsive images https://developer.mozilla.org/en-US/docs/Learn/HTML/Multimedia_and_embedding/Responsive_images
In order to ensure that your application is lightweight and responds quickly to user input, it's important to take a look at how much bandwith your application uses.
A quick way to do this is to open your dev tools and take a look at the total size of all downloaded assets when loading the website.
Setting cache control policies on HTTP response headers can prevent the browser having the re-download the same resource.
Service workers are also useful for defining which assets you would like to cache locally.
Many forms of downloaded media can be compressed. For more information on compression with HTTP take a look here https://developer.mozilla.org/en-US/docs/Web/HTTP/Compression
Using a build tool like Webpack or Grunt can allow you to combine multiple css, js or other file types into a single file reducing the amount of concurrent requests the browser has to make and can help an initial page request load faster.
Detecting the user's device can be quite useful when it comes to choosing what types of media to download. For example, you can generate different sizes for an image and then serve smaller images for user's on a mobile browser.
https://ffmpeg.org/ - FFmpeg is the leading multimedia framework, able to decode, encode, transcode, mux, demux, stream, filter and play pretty much anything that humans and machines have created. It supports the most obscure ancient formats up to the cutting edge. No matter if they were designed by some standards committee, the community or a corporation. It is also highly portable: FFmpeg compiles, runs, and passes our testing infrastructure FATE across Linux, Mac OS X, Microsoft Windows, the BSDs, Solaris, etc. under a wide variety of build environments, machine architectures, and configurations.
https://imagemagick.org/index.php - Use ImageMagick® to create, edit, compose, or convert bitmap images. It can read and write images in a variety of formats (over 200) including PNG, JPEG, GIF, HEIC, TIFF, DPX, EXR, WebP, Postscript, PDF, and SVG. ImageMagick can resize, flip, mirror, rotate, distort, shear and transform images, adjust image colors, apply various special effects, or draw text, lines, polygons, ellipses and Bézier curves.
Just like the server, the browser can have different types of states to manage...
- Server Response Data
- User information
- User Input
- UI State
- Router / location state
State Management Libraries
- Model our app state
- Update the state
- Read state values
- Monitor changs to the state
The three principles of Redux.
- Single source of truth.
- State is read-only.
- Pure functions update the state
One of the biggest benefits of using state management is that the duplicate dependency injection of data services can be moved out from the components to the state management library implementation.
In Universal (Server side rendered) Angular apps you can prepopulate the store on page load and avoid the many HTTP many requests needed for this logic with an SPA (Single Page Application).
Great developer tools including time travel debugging.
Easier testing of how data retrieved in the client application is used.
Because the state is read only, our components just have to react to state changes. Our components role when using state management is to subscribe to the store and respond appropriately.
A single state tree is a single Javascript object. It is composed / built up using reducers.
It has an initial state. When the application loads.
An example state
const state = {
todos: []
};
Actions have two properties
- Type (usually a string, describing the action).
- Payload (this is optional)
These are dispatched by components in order to update the application state but do not update the state themselves. This gives us an "immutable update pattern" which basically means that we clearly define how data is updated in our client applications.
const action = {
type: 'ADD_TO_DO',
payload: {
label: 'Go for a jog',
complete: false
}
};
These are pure functions (taken from the functional programming methodology) that update the application state. Given the same input they will always have the same output. They don't modify any data outside of their functional scope. This output is typically an updated application state.
This is a pure function. It does not mutate any data outside of it's own scope.
function reducer(state, action) {
switch(action.type) {
case: 'ADD_TO_DO': {
const todo = action.payload;
const todos = [...state.todos, todo],
return [ todos]; // Update the state and pass back
}
}
return state; // Return the passed state by default
}
This would result in the state being updated
const state = {
todos: [
{ labelL 'Go for a jog', complete: false }
]
};
- The state container. Injected into components that need it.
- Components use the store to dispatch events
- Components use the store to subscribe to state updates.
- Handles responsibility of invoking reducers.

"An immutable object is an object that cannot be modified after creation."
Why would we make an object immutable?
- Predictability
- Explicit State Changes
- Performance
- Mutation Tracking
- Undoing state changes
The first reference to the term "Semantic Web" was made by Tim Berners Lee back in 2011 in this publication Google Scholar Link
Wikipedia Article https://en.wikipedia.org/wiki/Semantic_Web
Personal Opinion: I studied this topic as part of my university thesis. I personally believe that the outlined solutions proposed by the W3C however interesting will not be accomodated any time soon by the majority of websites. Because of the flexible nature of HTML, CSS and Javascript coding practices websites will not provide structured markup required for the interopability of websites in this manner.
Content Management Systems,oding Frameworks by be able to incorporate these coding practices in the future and take the manual work of adding context to markup out of the developers workflow.
FOAF (Friend of a friend) http://xmlns.com/foaf/spec/ Open Graph Protocol http://ogp.me/ (Facebook uses this for links) W3C Spec on HTML Microdata https://www.w3.org/TR/microdata/ RDFa (RDFa is an extension to HTML5 that helps you markup things like People, Places, Events, Recipes and Reviews. Search Engines and Web Services use this markup to generate better search listings and give you better visibility on the Web, so that people can find your website more easily) https://rdfa.info/
JSON LD (JSON Linked Data) https://json-ld.org/
An introduction to web components from Mozilla https://developer.mozilla.org/en-US/docs/Web/Web_Components Custom Elements W3C Specification https://www.w3.org/TR/2018/NOTE-custom-elements-20180503/ Polymer (JS Library to create web components) https://www.polymer-project.org/
Shadow DOM refers to the ability of the browser to include a subtree of DOM elements into the rendering of a document, but not into the main document DOM tree.
Shadow DOM W3C Specificatin https://www.w3.org/TR/2018/NOTE-shadow-dom-20180301/
Whilst these frameworks might not follow the official W3C outlines for web components they are the most popular frameworks and libraries that are recognised as using "web components" by the community today.
- Angular
- Vue.js
- React.js
CSS Media Queries - https://css-tricks.com/a-complete-guide-to-css-media-queries/ CSS Flexbox - https://css-tricks.com/snippets/css/a-guide-to-flexbox/
- Check your browser user agent https://www.whatismybrowser.com/detect/what-is-my-user-agent
- Mozilla Developer Network - Browser detection using the user agent https://developer.mozilla.org/en-US/docs/Web/HTTP/Browser_detection_using_the_user_agent
Polyfills allow older browsers to handle HTML, CSS and Javascript features that would typically not be available with your client side code.
Server side detection is a very powerful technique that allows you to detect the users device, browser and browser capabilities before serving any content to their device. This allows you to customize the user experience and cater to any progresive functionality that their device and browser may support.
- Using supported HTML5 API
- Hardware capabilities
- Supported network protocols
- Video, audio
- JAVA
- Optimize the bandwidth used for the website when serving HTML, CSS, Javascript, Images, Fonts etc.
DeviceAtlas https://deviceatlas.com/ Wurfl - http://wurfl.sourceforge.net/ Scientamobile - https://www.scientiamobile.com/
Webtorm Guide https://www.jetbrains.com/help/webstorm/getting-started-with-webstorm.html#ws_getting_started_open_project Use GIT Bash for the terminal in Webstorm https://gist.github.com/sadikaya/f5fa699c435ebfafece2fb7d982bcdb5
Official documentation https://httpd.apache.org/docs/current/ .htcaccess file configuration https://httpd.apache.org/docs/current/howto/htaccess.html
Best documentation on Github: https://github.com/trimstray/nginx-quick-reference
Official documentation https://nginx.org/en/docs/ Third party modules https://www.nginx.com/resources/wiki/modules/
Official website https://www.iis.net/overview Getting started https://docs.microsoft.com/en-gb/iis/get-started/whats-new-in-iis-10-version-1709/new-features-introduced-in-iis-10-1709
- 10 common architectural patterns - 10 Common software architectural patterns in a nutshell.
- reactive design patterns - This website accompanies the book Reactive Design Patterns by Roland Kuhn.
- scalable System Design Patterns - Scalable system design techniques.
- martin fowler - Catalog of Patterns of Enterprise Application Architecture.
- system-design-primer - Design large-scale systems.
- architecting-for-reliability - Architecting for Reliability Part 1/3.
- AWS cloud design patterns - The AWS Cloud Design Patterns (CDP).
- Azure cloud design patterns - Building reliable, scalable, secure applications in the cloud.
- cloud patterns - A community site dedicated to documenting a master patterns catalog.
- cloud computing patterns - Cloud Computing Patterns.
- Google Cloud Solutions - Real business cases solutions with diagrams on GCP.
- serverless architecture - Serverless Architecture: Five Design Patterns.
- solving problems in serverless - Patterns for Solving Problems in Serverless Architectures.
- microservice patterns - A community site dedicated to documenting a master patterns catalog.
- microservices - A pattern language for microservices.
- microservices-anti patterns - Microservices antipatterns and pitfalls.
- 12factor - The twelve-factor methodology.
- microservices-sync-vs-async - Microservices patterns, synchronous and asynchronous.
- message-queues - Comparing-message-queue-architectures.
- enterprise Integration Patterns - Patterns and Best Practices for Enterprise Integration.
- containerspatterns - There are a Thousand Ways to Use Containers.
- container-anti-patterns - 10 containers anti-patterns.
- kubernetes - Kubernetes Production Patterns.
- container-design-patterns - Container Design Patterns for Kubernetes Pods Design.
- pattern-and-anti-pattern-cicd - Pattern and anti-pattern cicd.
- best-practices-for-shell-scripts - Best practices for shell scripts.
- opensecurityarchitecture - Security Architecture Patterns.
- martinfowler - Web-security-basics.
- cloud-security - Cloud security architecture intro.
- owasp - Security by Design Principles.
- azure-security - Azure security best practices and patterns.
- Package Managers (NPM, YARN)
- NVM (Node Version Manager) https://itnext.io/nvm-the-easiest-way-to-switch-node-js-environments-on-your-machine-in-a-flash-17babb7d5f1b
- Open Source Packages https://www.npmjs.com/
- Set up your own private registry https://github.com/verdaccio/verdaccio
- Exporting Modules https://flaviocopes.com/node-export-module/
- Node.js - Why use it? https://thinkmobiles.com/blog/why-use-nodejs/
- Non-blocking IO / Event Loop / nextTick function
- Asynch await
- Streams - https://flaviocopes.com/nodejs-streams/
- Websockets - https://flaviocopes.com/node-websockets/
- Linting - ESLint - https://eslint.org/
- Babel Transpiler https://babeljs.io/ - (Node.js uses ES5, Use ES6 for your app!).
- Semantic Versioning https://flaviocopes.com/npm-semantic-versioning/
- Package-lock.json - https://flaviocopes.com/package-lock-json/
- Functional programming: https://medium.freecodecamp.org/an-introduction-to-functional-programming-style-in-javascript-71fcc050f064 (Pure, impure functions)
NPX is great. It simplifies how you can run node package binaries inside your project. It is now included with NPM by default.
https://blog.npmjs.org/post/162869356040/introducing-npx-an-npm-package-runner - An introduction
The most popular Node.js module for creating REST API https://expressjs.com/
https://expressjs.com/en/guide/using-middleware.html - Express.js Middleware.
Express.js middleware functions are functions that have access to the request object (req), the response object (res), and the next middleware function in the application’s request-response cycle. The next middleware function is commonly denoted by a variable named next.
This is my favourite Node.js framework at the moment.
If you're a React or Angular developer today using Typescript, this framework will be quite intuitive.
Nest.js is a backend framework that allows you to develop scalable APIs or any other type of backend service you require. It is built on top of Express.js but allows for a more structured enterprise-grade codebase using Typescript. You can switch out express for another type of middleware for better performance e.g. fastify.
Nest comes with it's own monorepo architecture so there's no need for NX.
Best using NX for a full stack project with both Angular / Vue / React AND Nest.js.
$ npm i -g @nest/cli
$ nest new <your_project_name>
$ nest generate applicationnest infoExample Output
_ _ _ ___ _____ _____ _ _____
| \ | | | | |_ |/ ___|/ __ \| | |_ _|
| \| | ___ ___ | |_ | |\ `--. | / \/| | | |
| . ` | / _ \/ __|| __| | | `--. \| | | | | |
| |\ || __/\__ \| |_ /\__/ //\__/ /| \__/\| |_____| |_
\_| \_/ \___||___/ \__|\____/ \____/ \____/\_____/\___/
[System Information]
OS Version : Windows 10
NodeJS Version : v10.16.0
NPM Version : 6.11.3
[Nest CLI]
Nest CLI Version : 7.5.1
[Nest Platform Information]
platform-express version : 7.0.0
common version : 7.0.0
core version : 7.0.0Use the nest CLI to add dependencies as it will allow you to choose which apps and modules to add it to.
$ nest add <npm-module-name>nest updateYou can preview the changes made which each of these commands by appending --dry-run
$ nest generate application <your_app_name>
$ nest generate class <path/your_class_name>
$ nest generate configuration
$ nest generate controller <path/your_controller_name>
$ nest generate decorator <path/your_decorator_name>
$ nest generate filter <path/your_filter_name>
$ nest generate gateway <path/your_gateway_name>
$ nest generate guard <path/your_guard_name>
$ nest generate interceptor <path/your_interceptor_name>
$ nest generate interface <path/your_interface_name>
$ nest generate middleware <path/your_middleware_name>
$ nest generate module <path/your_module_name>
$ nest generate pipe <path/your_pipe_name>
$ nest generate provider <path/your_provider_name>
$ nest generate resolver <path/your_resolver_name>
$ nest generate service <path/your_service_name>
$ nest generate library <path/your_library_name>
$ nest generate sub-app <sub_app_name>
$ nest generate resource <path/resource_name># development
$ nest start <app_name> --watch
# production mode
$ nest build <app_name> (Generates native Javascript for Node.js)
$ node dist/<app_name> main.jsRun all tests to make sure that no shared modules are broken between projects.
# unit tests
$ npm run test
# API Integration Tests
$ npm run test:e2e
# test coverage
$ npm run test:covNodemon enables live reloading within your application. It will watch your source files for changes and trigger a rebuild / reload of your code when necessary.
Creating and Subscribing to Observables with RXJS. Click here
Subjects (BehaviourSubject, ReplaySubject, Asynch) with RXJS. Click here
Operators with RXJS Click here
- MomentJS - Functional utility library
- MomentJS - Date Utility Library
- Axios - Promise based HTTP client for the browser and node.js
- Cors - Express.js middleware to allow cross origin resource sharing
- Body-Parser - Express.js request body parsing middleware to parse your API requests
- Morgan - Express.js middleware to log incoming API requests.
- PassportJS - Node and Express.js middleware for all of your authentication needs. Both JWT and OAuth.
- Passport-Local - Username and password authentication strategy for Passport and Node.js.
- Passport-JWT - Passport.js authentication using JSON Web Tokens
- Raven - A standalone (Node.js) client for Sentry (Sentry is error reporting software).
- Joi - Out of the box object schema validation. Useful for your data models and validating different types of data automatically.
- Http-Status - Utility to interact with HTTP status code in Node.js
- Lint-Staged - CLI Tool. Run linters on git staged files.
- Husky - GIT Hooks simplified.
- Prettier - CLI Tool. Prettier is an opinionated code formatter.
- Eslint Config Prettier - ESLint rule template.
- Istanbul - Code coverage Tools
- Mocha - Unit Test Framework
- Chai - JS Assertion Library
- Supertest - Test your API Endpoints with Node.js code.
- NPS - NPS is a package that solves the problem of large and complicated NPM scripts by allowing you to move your scripts to a package-scripts.js file. Because this file is a JavaScript file, you can do a lot more with your project scripts.
- Mongoose - MongoDB Object Modelling for Node.js.
Distributed file system that seeks to connect all computing devices with the same system of files https://ipfs.io/
Purely functional Javascript utility Library
https://github.com/ramda/ramda
- Official Handbook https://www.typescriptlang.org/docs/handbook/basic-types.html
- DefinitelyTyped (The repository for high quality) https://github.com/DefinitelyTyped/DefinitelyTyped
- https://www.npmjs.com/package/swagger-ts-generator
- https://www.npmjs.com/package/swagger-ts-generator (Generate Types from your swagger documentation)
TSLint https://palantir.github.io/tslint/ TSLint formatters https://palantir.github.io/tslint/formatters/ AirBNB TSLint (Just extend this in your TSLint configuration to use it in your project, you can override and customize these settings) https://www.npmjs.com/package/tslint-config-airbnb
- Official Angular Documentation https://angular.io/docs
- Awesome Angular https://github.com/gdi2290/awesome-angular
- NX (Nrwl extensions for Angular) https://nrwl.io/nx (Build out your Enterprise Angular applications for modularity and with a smarter Angular CLI. I highly recommend this).
- Angular Console https://angularconsole.com/ (GUI for the Angular CLI, good for getting further context on many commonly run commands).
- Hot Module Replacement with Angular - https://medium.com/wizardnet972/hot-module-replacement-with-angular-cli-5fc7a3ae4a9c
- Deploying Angular Applications to a serverless environment https://medium.com/@maciejtreder/angular-serverless-a713e86ea07a
- Angular Universal (Server Side Rendering) https://angular.io/guide/universal
- Bundle size budget warnings for your builds https://github.com/angular/angular-cli/blob/master/docs/documentation/stories/budgets.md
- https://christianlydemann.com/the-ten-commandments-of-angular-development/#two - The Ten Commandments of Angular Development
https://ultimatecourses.com/angular - My most recommended course. https://www.tutorialspoint.com/angular6 - A useful overview of coure Angular concepts.
Angular HTTP Interceptors are useful for modifying network requests and responses as they are send and received.
This can be particularly useful for authentication when an authorization token needs to be added to the headers of a request sent to an API.
Official documentation https://angular.io/guide/http#intercepting-requests-and-responses
Tip: Always check the component / module dependencies to avoid bloating the size of your static build files.
- https://github.com/NetanelBasal/ngx-auto-unsubscribe - Angular Observable Unsubscribe
- https://material.angular.io/cdk/layout/overview - Angular CDK - Subscribe to events based on screen viewports / media queries.
- https://github.com/ngrx/platform/tree/master/docs/entity - Streamline development of your model based reducers and selectors with NgRX. (Good reference here https://blog.angular-university.io/ngrx-entity/#operationssupportedbythengrxentityadapter)
- https://www.npmjs.com/package/ngrx-store-freeze - Prevents mutations on Angular Router with NgRX
- https://github.com/Asymmetrik/ngx-leaflet - Themed Google Map Components
- https://murhafsousli.github.io/ngx-gallery/#/lightbox - Image Lightbox Component
- https://murhafsousli.github.io/ngx-gallery/#/gallery - Image Gallery Component
- https://github.com/MurhafSousli/ngx-teximate - Angular Text Animation plugins for your components.
- https://www.npmjs.com/package/ngx-quill - Rich text editor component with code snippet themes and plugins.
- https://www.npmjs.com/package/ngx-moment - MomentJS Angular Pipes.
- https://github.com/atularen/ngx-monaco-editor (Browser-based code editor for Microsoft. Angular component.)
- https://manfredsteyer.github.io/angular-oauth2-oidc/docs/ - Excellent module for providing OAuth Authentication.
- https://hackafro.github.io/angular-epic-spinners/ - Spinner Components
- https://valor-software.com/ngx-bootstrap/#/ - Ngx Bootstrap - Angular 4 Bootstrap components.
- https://valor-software.com/ng2-dragula/ - Drag and drop components.
- https://github.com/evanplaice/ng2-markdown - Markdown component.
- https://valor-software.com/ng2-file-upload/ - File upload components.
- https://github.com/travelist/angular2-fontawesome - Angular components for font awesome (not really needed as font awesome is easy).
- https://github.com/VadimDez/ng2-pdf-viewer - PDF viewer components.
- https://github.com/vladotesanovic/ngSemantic - Semantic UI CSS Framework ported to Angular components.
- https://github.com/BottleRocketStudios/ng-momentum - Ng Momentum - Interesting perspective on Angular Schematics for code generation in your app.
Nx is brilliant. It is built on top of the Angular CLI so it will feel quite familiar to other developers hat have used it before.
All of the existing Angular CLI commands will work but NX offers more functionality.
It allows you to manage your application with a more advanced CLI tool that automates more than the standard Angular CLI.
It provides a framework for Enterprise Angular development that avoids complications with managing shared libraries and avoiding unecessary pipelines.
It also helps developers to see where they can avoid code duplication, increase modularity and avoid introducing breaking changes.
- Extra Code Generation
- Workspace Management
- NgRx State Management Code Generation
- Data Persistence Management
- Linters
- Code Formatting
- UpgradeModule and dowgradeModule helpers
- Vulnerability scanning
Find out more at https://nrwl.io/nx/overview
<project-root-directory>
apps/
website1.com/
src/
website2.com
src/
libs/
website1.com/
src/
website2.com/
src/
ui-component-library
src/
data-services
src/
- You now don't need separate GIT repos!
- Our applications are independenly deployable!
- You can clearly see how your applications and shared node modules relate to each other!
- No more CI/CD Pipelines for every shared library we create!
- We can clearly see when things break for ANY application!
- No GIT submodules :)
- No cloning different GIT repos to see how a shared library works (easier to keep everything on context).
Each library has an index.ts fie so we can use shared modules in our repo as if they we normal NPM modules. For example we won't need to do this
import { CustomModule } from '@ourorgansiation/custom/src/custom.module'
We can still do this..
import { CustomModule } from '@ourorgansiation/custom'
https://auth0.com/blog/create-custom-schematics-with-nx/ - Creating custom schemantics with Nx https://www.youtube.com/watch?v=bMkKz8AedHc - Supercharging the Angular CLI with Nx by James Henry https://blog.nrwl.io/building-full-stack-applications-using-angular-cli-and-nx-5eff205248f1 - Creating
Angular schematics are a very interesting topic for me personally. Enterprise developers can use Angular Schematics to streamline code generation in projects. The Angular CLI comes when many code generation commands which is powerful for scaffolding applications. These in themselves are Angular Schematics and you can roll your own for your projects or enterprise workspaces. Add Nx to the mix and developers can automate much of their development workflow.
- Library generation
- Component generation
- Unit Test Generation
Whatever you want form your code structure really..
- Enforcing design patterns
- Enforcing modularity of code
- Enforcing naming conventions
https://auth0.com/blog/create-custom-schematics-with-nx/
- Use the Angular console app (other developers can learn more quickly this way) https://angularconsole.com/
A comprehensive list of commands can be found here https://github.com/nrwl/nx-examples (Highly recommended)
NgRX at it's core is made up of NgRX Store and Effects. It utilizes the popular Rx.js library and it's observable design pattern to provide a Redux architecture for state management in Angular.
- NgRX Store on Github https://github.com/ngrx/store
- NgRx Effects https://github.com/ngrx/effects
- NgRX best practice patterns https://angularcamp.org/files/State_Management_Patterns_and_Best%20Practices_with_NgRx.pdf
There are other libraries than can be used with NgRX but they are optional.
Note: Code scaffolding for NgRX can be achived with NX Angular Schemantics but it is important to understand how the Redux pattern and NgRX specifcally work with Angular.
Official documentation https://ngrx.io/guide/store
Inspired by the Redux architecture NgRX Store using RXJS Observables to provide state management in Angular.
- Single source of truth
- Testability
- Performance Benefits (one-way data flow. No unexpected events in your components around data management).
- Root and feature module support (eager ad laxy loaded modules).
This is probably the toughest part about NgRX in general but they are well worth implementing
A very basic component implementation interacting with the store would look something like this..
import { Store } from '@ngrx/store'
// other imports
export class YourCustomComponent implements OnInit {
constructor(private store: Store<fromStore.ToDosState>) {
}
ngOnInit() {
this.store.select<>('todos').subscribe() // etc
}
};
You can however define functions in your store that care of all of the logic for navigating the state and getting the data your are looking for. These can be imported and used to select data specifically from your store. Your component can then store the observables and use asynch in your components to handle changes to the state reactively.
You can use a naming convention for observables that are stored on your component. Typically using the $ at the end of the variables name is a good idea.
import { Store } from '@ngrx/store'
// other imports
export class YourCustomComponent implements OnInit {
todos$: Observable<ToDo[]>
constructor(private store: Store<fromStore.ToDosState>) {
}
ngOnInit() {
this.todos$ = this.store.select>(fromStore.getAllToDos)
}
};
Then in your HTML for the component
<div *ngIf="!((todos$ | async)?.length)">
These are currently no to do items
</div>
<to-do-item *ngFor="let todo of (todos$ | async)" [todo]="todo"></to-do-item>
This observables and async approach makes your components implement a reactive architecture.
Official doccuentation https://ngrx.io/guide/effects
- Listen for ngrx/store actions that are dispatched
- Isolate side effects from components
- Communicate outside of Angular (Handle API calls, websockets etc)
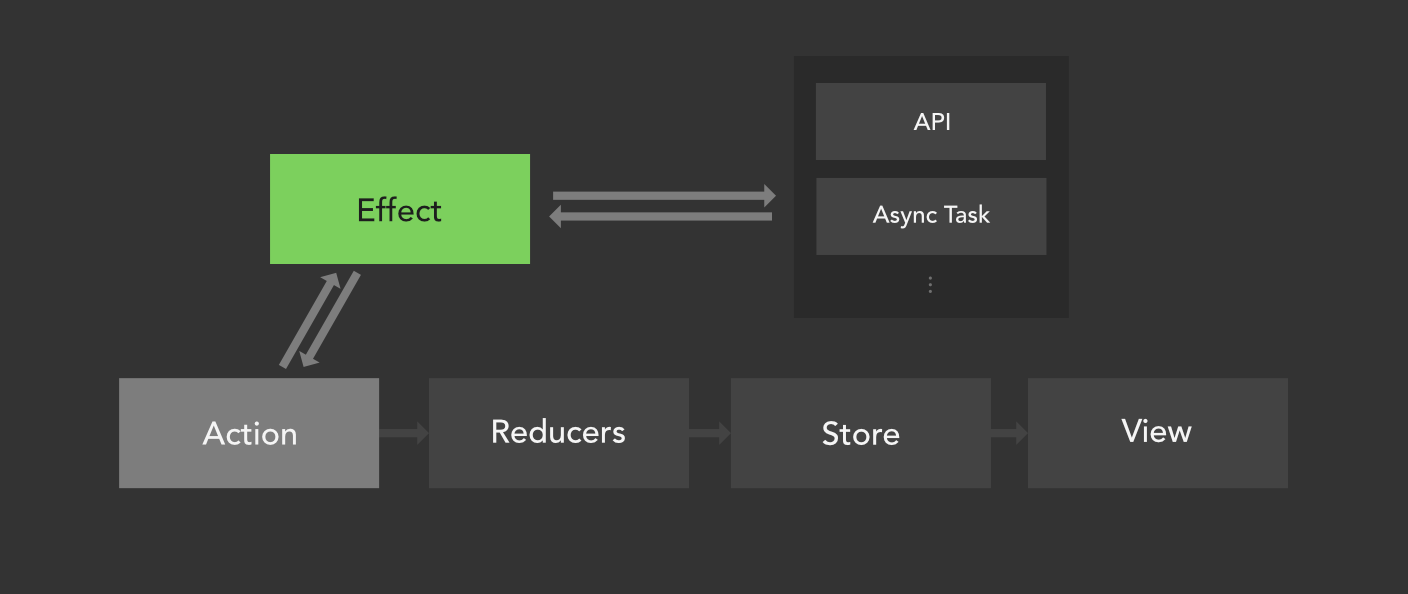
Because reducers are pure functions these are not ideal places to put API calls
If an effect fetches data from an external source then it will dispatch an action of it's own with a reducer handling it and updating the state
Effects don't perform service calls themselves. They will typically offload that work to an Angular service.
This pattern is purely optional but once implemented provides a much cleaner implementation with NgRX on the component level.
I haven't used this approach myself yet but would like to. I'm curious about how it effects testing.
Its also supported by Nx Angular Schematics!
https://medium.com/@thomasburleson_11450/ngrx-facades-better-state-management-82a04b9a1e39
A great tutorial https://blog.angular-university.io/ngrx-entity/#operationssupportedbythengrxentityadapter
Can be used with NgRX Schematics and provides..
- Entity State adapter for managing record collections by ID reference.
- Entity provides an API to manipulate and query entity collections.
- Reduces boilerplate for creating reducers that manage a collection of models.
- Provides performant CRUD operations for managing entity collections.
- Extensible type-safe adapters for selecting entity information.
This will allow you see every single action and state change in your app.
It really showcases how reactive your application is when built using the redux pattern.
You can also step back in time to an older state to debug issues with your application by dragging the slider.
It will also visualize your state tree in an easy to understand way if you index your data with the entities approach outlined above.
You can download the extension here http://extension.remotedev.io/
This allows us to integrate our router state to the redux store in our application which is quite useful for even more debugging with our dev tools. It also makes our application more reactive.
** I will be providing a link here to my own reference Angular application with state management **
- State Management with Angular requires a lot of extra code. This can be generated automatically though with the CLI once NgRX schematics have been added to your project https://ngrx.io/guide/schematics . It's even better using NX https://nrwl.io/nx/guide-setting-up-ngrx
- Implement container components for each feature (these are basically the top most parent components for each module).
- Hook up your router to the state
- Make both your routing and store actions resource based (from the API down to the store for consistency, bespoke functionality can be implemented at the component level).
- Keep your stores inside of the relevant modules only. This will allow you to keep your feature implementations modular.
- Optimize your folder structure with index.ts files wherever possible to avoid too many imports.
NgXS - https://ngxs.gitbook.io/ngxs Akkita - https://blog.angularindepth.com/state-management-in-angular-using-akita-82f117d282dd Mobx - https://mobx.js.org/getting-started.html - can be plugged into Angular https://github.com/mobxjs/mobx-angular
https://blog.singular.uk/why-i-prefer-ngxs-over-ngrx-df727cd868b5 - A comparison between NgXS and NgRX
This is a controversial topic depending on which developers / teams and organisations you ask.
I've personally learned over time that as long as the structure is modular, maintainable and as intuitive as possible for everyone then that's the best compromise.
Official documentation https://karma-runner.github.io/latest/index.html
Karma comes with Angular for your unit tests by default and many coverage and reporting tools are available.
You can also choose to run your unit tests with ChromeHeadless to avoid spinning up a new browser window every time.
Official documentation https://jestjs.io/docs/en/getting-started
Replacing the default karma unit test suite wih Jest can result in many benefits for your application.
https://www.xfive.co/blog/testing-angular-faster-jest/
- Faster (does not require a browser to run the tests)
- Easier to debug as the error messages are less verbose
- The browser is mocked and the tests run in JSDOM instead (much, much faster!)
- https://github.com/jest-community/jest-extended (Additional assertations)
- https://github.com/mattphillips/jest-chain (Chain your assertions for less code)
- https://github.com/Hargne/jest-html-reporter - HTML Test Results Report
- https://github.com/marak/Faker.js/ - Generate fake data for spies and mocks.
Behaviour-Driven Development (BDD) is a collaborative approach to software development that bridges the communication gap between business and IT. BDD helps teams communicate requirements with more precision, discover defects early and produce software that remains maintainable over time.
https://dev.to/fzwael/bdd-with-angular-and-cucumberjs-p8
https://www.cypress.io/ - Official website https://chrome.google.com/webstore/detail/cypress-scenario-recorder/fmpgoobcionmfneadjapdabmjfkmfekb?hl=en - Useful Chrome Extension for generating script.
Provides
- Time Travel
- Debuggability
- Automatic Waiting
- Spies, Stubs, and Clocks
- Network Traffic Control
- Consistent Results
- Screenshots and Videos
https://blog.nrwl.io/nrwl-nx-7-0-better-e2e-testing-with-cypress-1b88336bef5e - Better E2E Testing with Cypress
https://storybook.js.org/docs/react/get-started/introduction
Storybook allows for a more collaborative approach to developing UI components with React, Vue and Angular.
QA, Developers and UX Teams can use it to develop more robust components that are more general and reusable across business logic and specific use cases.
https://compodoc.app/ - Excellent Angular project documentation tool
To use source-map-explorer, first install it globally using your favorite package manager:
npm install -g source-map-explorer
yarn global add source-map-explorer
And then build your angular application with –source-map flag set to true:
ng build --source-map=true --prod
And finally run it on one or more of your generated bundles. For instance, main bundle:
npx source-map-explorer dist/main.xxx.bundle.js
https://www.youtube.com/watch?v=7aY9BoMEpG8 - Video from Google developers
The Angular CLI uses webpack in the background to build your application.
You can analyze the static files in your build for a breakdown of exactly what dependencies you have included.

To get started with this tool, install is a dev dependency in your project using your favorite package manager:
npm i webpack-bundle-analyzer --save-dev
yarn add webpack-bundle-analyzer –dev
Then, build your application with –stats-json flag:
ng build --prod --stats-json
And finally, run Webpack Bundle Analyzer against the generated stats.json file located under dist/app-name for angular 6, and dist for angular 5 and below:
npx webpack-bundle-analyzer dist/APP-NAME/stats.json
Your app name can be found inside your angular.json configuration file.
You can use this to monitor the code quality of the typescript in your application.
It is highly custmizable with it's set of rules and you can even use other organisation's code standards.
For more information visit the official website https://palantir.github.io/tslint/
A fantastic code coverage reporting tool. Official documentation can be found here https://istanbul.js.org/
This is quite useful for vizualizing your E2E Test Results. It can also display screenshots for debugging.
https://github.com/etxebe/protractor-html-reporter
Note: You will need HTTPS on your website to fully utilise this browser feature.
https://developer.mozilla.org/en-US/docs/Web/API/Service_Worker_API - Mozilla Service Worker API Guide.
Use a service worker instead :)
The role of a build tool in web applications is take the source development assets for your application and produce optimized assets that will be used to run your application.
This can include tasks such as
- Copy, deleting files
- Merging files
- Compiling code
- Optimizing code
- Removing spaces
- Producing index files
- Optimizing images, fonts other assets.
- Any other tasks you wish to automate with your application setup.
Javascript Task runner with an impressive list of plugins https://gruntjs.com/
Another Javascript build tool for automating common tasks https://gulpjs.com/
Angular uses webpack.
- Semantic browser applications: Schema generation.
- Optimizing Images (PNG, SVG,)
- Optimizing fonts
- Minification of files
- Concatenation of files
- WEBRTC https://webrtc.org/
- Web Assembly https://webassembly.org/
- WebGL https://developer.mozilla.org/en-US/docs/Web/API/WebGL_API/Tutorial/Getting_started_with_WebGL
Develop applications for native operating systems with HTML, CSS and Javascript https://cordova.apache.org/
Develop desktop applications with HTML, CSS and Javascript https://electronjs.org/
- Nativescript
Lets you call all Node.js modules directly from DOM and enables a new way of writing applications with all Web technologies.
Source / Version Control allows developers to share and track each individual change to a codebase.
It allows developers to work on the same piece of code and can automate much of the tedious aspects of resolving these conflicts.
https://www.mercurial-scm.org/
https://subversion.apache.org/
How merkle trees work https://en.wikipedia.org/wiki/Merkle_tree
Continuous deployment is a strategy for software releases wherein any code commit that passes the automated testing phase is automatically released into the production environment, making changes that are visible to the software's users.
Continuous Integration (CI) is a development practice where developers integrate code into a shared repository frequently, preferably several times a day. Each integration can then be verified by an automated build and automated tests. While automated testing is not strictly part of CI it is typically implied.
Continuous delivery (CD) is a software engineering approach in which teams produce software in short cycles, ensuring that the software can be reliably released at any time and, when releasing the software, doing so manually. It aims at building, testing, and releasing software with greater speed and frequency. The approach helps reduce the cost, time, and risk of delivering changes by allowing for more incremental updates to applications in production. A straightforward and repeatable deployment process is important for continuous delivery.
https://azure.microsoft.com/en-gb/services/ - Overview of products and solutions
https://cloud.google.com/products/ - Overview of products and solutions
This can be as simple as having a development, QA, UAT and production server but there are many different configurations that can be useful depending on your project.
Storing sensitive information in your GIT repository makes you vulnerable to unauthorised access.
Because of this it is more useful to have these values parameterised and injected later by your hosting provider or pipeline configuration.
Environment variables can be used for database credentials, secret keys or any other type of private key / password values.
It also allows for a more synchronised approach when having to update these values later on as the values can be changed in one place instead of across multiple servers in the case of scaled applications.
Verdaccio (NPM Registry) JAVA - Maven Gradle repositories.
- CodeClimate
- Coveralls
- Travis Ci
- Circle Ci
- Greenkeeper
- https://semaphoreci.com/ - Semaphore CI
- https://jenkins.io/ - Jenkins
- https://azure.microsoft.com/en-gb/solutions/architecture/azure-devops-continuous-integration-and-continuous-deployment-for-azure-web-apps/ - Microsoft Azure CI/CD
- https://cloud.google.com/cloud-build/ - Google Cloud Build
- https://aws.amazon.com/ - Amazon Web Services
https://www.netlify.com/ - All-in-one platform for automating modern web projects.
Virtual environments are extremely useful for ensuring that you have a consistent OS and dependency layer for your development and deployment environments.
It takes away the time consuming tasks of provisioning each individual environment and list of dependencies when scaling too.
For developers it can also keep the list of running processed on their local machines free of any bloat from previous projects.
https://www.vagrantup.com/intro
Simple, intituive virtual environments (they use more disk space however).
https://www.docker.com/why-docker
Container based approach. Lightweight environments.
- Download and Install Docker Desktop for Windows
https://download.docker.com/win/stable/Docker%20Desktop%20Installer.exe
- Download and install AWS CLI tool
https://s3.amazonaws.com/aws-cli/AWSCLI64PY3.msi
on your terminal type
aws configure
Access Key Id -
<your key>
Secret Access Key -<your secret>
Region -eu-west-1
Format -json
That should save your credentials on ~/.aws/credentials and config files consecutively.
Now you can login onto AWS ECR services
$(aws ecr get-login --no-include-email)
- Run docker compose to spawn each service
docker-compose up -d
This should download images from ECR repository and start services consecutively. If you have Kitematic installed you'll be able to see the logs of each container and your App should start at 127.0.0.1:8080
- Install https://www.docker.com/products/docker-desktop
- Use the Native Docker GUI (Docker Desktop)
- Install Kitematic (optional but recommended)
- Official download (latest): https://github.com/docker/kitematic/releases
https://hub.docker.com/search?q=&type=image - Search for a docker image
docker build -t <image-name> <whatever-custom-container-name>/.
Run
docker-compose up -d
and in Kitematic, view the logs for your custom container.
Pull an image from the repo
docker pull <image>
This will run a container based on its image. If no entrypoint is determined it should redirect to its terminal. When running containers add tag "--name" for easy access and identification. Also adding a tag "--rm" it removes it from a dangling list once exited.
docker run -it <image:tag>
To overwrite a default entrypoint of a container
docker run -it --entrypoint bash <image:tag>
List all running containers, add "-a" to list all containers including the stopped ones
docker ps
Stop all containers
docker stop $(docker ps -a -q)
Remove all containers
docker rm -f $(docker ps -a -q)
Remove container by container ID
docker rm -f $(sudo docker ps --before="container_id_here" -q)
This works only on a running container, the reason is beacuse containers are supposed to be immutable.
docker exec -it $(docker container ls | grep '<seach_term>' | awk '{print $1}') sh
winpty docker exec -it $(docker container ls | grep '<seach_term>' | awk '{print $1}') sh
docker rm $(docker ps -q -f status=exited) # remove all exited containers
docker images | grep "search_term_here"
docker rmi -f image_id_here # remove image(s)
docker rmi -f $(docker images -q) # remove ALL images!!!
docker rmi -f $(docker images | grep "^<none>" | awk '{print $3}') # remove all <none> images
docker rmi -f $(docker images | grep 'search_term_here' | awk '{print $1}') # i.e. 2 days ago
docker rmi -f $(docker images | grep 'search_1\|search_2' | awk '{print $1}')
docker images && docker ps -a
docker ps -a --no-trunc | grep "search_term_here" | awk "{print $1}" | xargs -r --no-run-if-empty docker stop && \
docker ps -a --no-trunc | grep "search_term_here" | awk "{print $1}" | xargs -r --no-run-if-empty docker rm && \
docker images --no-trunc | grep "search_term_here" | awk "{print $3}" | xargs -r --no-run-if-empty docker rmi
docker ps --filter 'status=Exited' -a | xargs docker stop docker images --filter "dangling=true" -q | xargs docker rmi
docker volume rm $(docker volume ls -qf dangling=true)
docker network rm $(docker network ls -q)
docker pull ubuntu:latest
docker run -i -t ubuntu /bin/bash # drops you into new container as root
https://docs.docker.com/installation/ubuntulinux/#ubuntu-trusty-1404-lts-64-bit
http://www.centurylinklabs.com/15-quick-docker-tips/
https://gist.github.com/RuslanHamidullin/94d95328a7360d843e52
PM2 or Process Manager 2, is an Open Source, production Node.js process manager helping Developers and Devops manage Node.js applications in production environment. In comparison with other process manager like Supervisord, Forever, Systemd, some key features of PM2 are automatic application load balancing, declarative application configuration, deployment system and monitoring.
pm2 start app.js --name my-api # Name process
pm2 start app.js -i 0 # Will start maximum processes with LB depending on available CPUs
pm2 start app.js -i max # Same as above, but deprecated.
pm2 scale app +3 # Scales `app` up by 3 workers
pm2 scale app 2 # Scales `app` up or down to 2 workers total
pm2 list # Display all processes status
pm2 jlist # Print process list in raw JSON
pm2 prettylist # Print process list in beautified JSON
pm2 describe 0 # Display all informations about a specific process
pm2 monit # Monitor all processes
pm2 logs [--raw] # Display all processes logs in streaming
pm2 flush # Empty all log files
pm2 reloadLogs # Reload all logs
pm2 stop all # Stop all processes
pm2 restart all # Restart all processes
pm2 reload all # Will 0s downtime reload (for NETWORKED apps)
pm2 stop 0 # Stop specific process id
pm2 restart 0 # Restart specific process id
pm2 delete 0 # Will remove process from pm2 list
pm2 delete all # Will remove all processes from pm2 list
pm2 reset <process> # Reset meta data (restarted time...)
pm2 updatePM2 # Update in memory pm2
pm2 ping # Ensure pm2 daemon has been launched
pm2 sendSignal SIGUSR2 my-app # Send system signal to script
pm2 start app.js --no-daemon
pm2 start app.js --no-vizion
pm2 start app.js --no-autorestart
https://kubernetes.io/docs/home/ - Kubernetes Documentation
https://github.com/semantic-release/semantic-release
https://github.com/semantic-release/changelog - Useful NPM library that works with the conventional commit to gather commits and generate changelogs for each release.
https://www.teamgantt.com/guide-to-project-management/taming-scope-creep
- Rigor and formality
- Separation of concerns
- Modularity and decomposition
- Abstraction
- Anticipation of change
- Generality
- Incremental Development
- Reliability
https://facebook.github.io/flux/docs/overview.html#content - Flux Architecture
https://thevaluable.dev/dry-principle-cost-benefit-example/
https://microservices.io/presentations/index.html - Avoid the monolith
https://www.tutorialspoint.com/functional_programming/functional_programming_introduction.htm
https://medium.com/@kevalpatel2106/what-is-reactive-programming-da37c1611382
https://www.tutorialspoint.com/software_testing_dictionary/unit_testing.htm
https://www.tutorialspoint.com/software_testing_dictionary/load_testing.htm
https://www.educba.com/code-coverage/
https://softwaretestingfundamentals.com/integration-testing/
https://www.agilealliance.org/glossary/bdd/
https://www.guru99.com/end-to-end-testing.html
https://medium.com/mindorks/solid-principles-explained-with-examples-79d1ce114ace
S - Single Responsibility Principle (known as SRP) O - Open/Closed Principle L - Liskov’s Substitution Principle I - Interface Segregation Principle D - Dependency Inversion Principle
https://www.browserstack.com/cross-browser-testing

The OSI Model (Open Systems Interconnection Model) is a conceptual framework used to describe the functions of a networking system. The OSI model characterizes computing functions into a universal set of rules and requirements in order to support interoperability between different products and software. In the OSI reference model, the communications between a computing system are split into seven different abstraction layers: Physical, Data Link, Network, Transport, Session, Presentation, and Application.
Created at a time when network computing was in its infancy, the OSI was published in 1984 by the International Organization for Standardization (ISO). Though it does not always map directly to specific systems, the OSI Model is still used today as a means to describe Network Architecture.
The lowest layer of the OSI Model is concerned with electrically or optically transmitting raw unstructured data bits across the network from the physical layer of the sending device to the physical layer of the receiving device. It can include specifications such as voltages, pin layout, cabling, and radio frequencies. At the physical layer, one might find “physical” resources such as network hubs, cabling, repeaters, network adapters or modems.
At the data link layer, directly connected nodes are used to perform node-to-node data transfer where data is packaged into frames. The data link layer also corrects errors that may have occurred at the physical layer.
The data link layer encompasses two sub-layers of its own. The first, media access control (MAC), provides flow control and multiplexing for device transmissions over a network. The second, the logical link control (LLC), provides flow and error control over the physical medium as well as identifies line protocols.
The network layer is responsible for receiving frames from the data link layer, and delivering them to their intended destinations among based on the addresses contained inside the frame. The network layer finds the destination by using logical addresses, such as IP (internet protocol). At this layer, routers are a crucial component used to quite literally route information where it needs to go between networks.
The transport layer manages the delivery and error checking of data packets. It regulates the size, sequencing, and ultimately the transfer of data between systems and hosts. One of the most common examples of the transport layer is TCP or the Transmission Control Protocol.
The session layer controls the conversations between different computers. A session or connection between machines is set up, managed, and termined at layer 5. Session layer services also include authentication and reconnections.
The presentation layer formats or translates data for the application layer based on the syntax or semantics that the application accepts. Because of this, it at times also called the syntax layer. This layer can also handle the encryption and decryption required by the application layer.
At this layer, both the end user and the application layer interact directly with the software application. This layer sees network services provided to end-user applications such as a web browser or Office 365. The application layer identifies communication partners, resource availability, and synchronizes communication.
https://developer.mozilla.org/en-US/docs/Web/HTTP
Most computer programs run procedures, or sets of instructions, using the computer's CPU. In other words, the instructions are processed locally on the same computer that the software is running from. Remote procedure calls, however, run procedures on other machines or devices connected to a network. Once the instructions have been run, the results of the procedure are usually returned to the local computer.
For example, a computer without a hard drive may use an RPC to access data from a network file system (NFS). When printing to a network printer, a computer might use an RPC to tell the printer what documents to print. A client system connected to a database server may execute an RPC to process data on the server.
Remote procedure calls are based on the client-server model, where multiple client computers may connect to a server and retrieve data from it. RPCs are typically written in a standard format, such as XML, so that the procedures can be understood by multiple computer platforms. For example, an XML-RPC sent by a Windows computer could be recognized by a Macintosh or Unix-based system
RDBMS are more widely known and understood than their NoSQL cousins. Relational databases emerged in the 70’s to store data according to a schema that allows data to be displayed as tables with rows and columns. Think of a relational database as a collection of tables, each with a schema that represents the fixed attributes and data types that the items in the table will have. RDBMS all provide functionality for reading, creating, updating, and deleting data, typically by means of Structured Query Language (SQL) statements.
The tables in a relational database have keys associated with them, which are used to identify specific columns or rows of a table and facilitate faster access to a particular table, row, or column of interest.
Data integrity is of particular concern in relational databases, and RDBMS use a number of constraints to ensure that the data contained in your tables is reliable and accurate.
While there are many relational databases, over time these have become the most popular:
- Oracle - Oracle Database (commonly referred to as Oracle RDBMS or simply as Oracle) is a multi-model database management system produced and marketed by Oracle Corporation.
- MySQL - MySQL is an open source RDBMS based on Structured Query Language (SQL). MySQL runs on virtually all platforms, including Linux, UNIX, and Windows.
- Microsoft SQL Server - Microsoft SQL Server is an RDBMS, that supports a wide variety of transaction processing, business intelligence and analytics applications in corporate IT environments.
- PostgreSQL - PostgreSQL, often simply Postgres, is an object-relational database management system (ORDBMS) with an emphasis on extensibility and standards compliance.
- DB2 - DB2 is an RDBMS designed to store, analyze and retrieve data efficiently.
- Relational databases are well-documented and mature technologies, and RDBMS are sold and maintained by a number of established corporations.
- SQL standards are well-defined and commonly accepted.
- A large pool of qualified developers have experience with SQL and RDBMS.
- All RDBMS are ACID-compliant, meaning they satisfy the requirements of Atomicity, Consistency, Isolation, and Durability.
- RDBMSes don’t work well — or at all — with unstructured or semi-structured data, due to schema and type constraints. This makes them ill-suited for large analytics or IoT event loads.
- The tables in your relational database will not necessarily map one-to-one with an object or class representing the same data.
- When migrating one RDBMS to another, schemas and types must generally be identical between source and destination tables for migration to work (schema constraint). For many of the same reasons, extremely complex datasets or those containing variable-length records are generally difficult to handle with an RDBMS schema.
NoSQL databases emerged as a popular alternative to relational databases as web applications became increasingly complex. NoSQL/Non-relational databases can take a variety of forms. However, the critical difference between NoSQL and relational databases is that RDBMS schemas rigidly define how all data inserted into the database must be typed and composed, whereas NoSQL databases can be schema agnostic, allowing unstructured and semi-structured data to be stored and manipulated.
Note that some products may fall into more than one category. For example, Couchbase is both a document database and a key-value store.
Key-Value Stores, such as Redis and Amazon DynamoDB, are extremely simple database management systems that store only key-value pairs and provide basic functionality for retrieving the value associated with a known key.
The simplicity of key-value stores makes these database management systems particularly well-suited to embedded databases, where the stored data is not particularly complex and speed is of paramount importance.
Wide Column Stores, such as Cassandra, Scylla, and HBase, are schema-agnostic systems that enable users to store data in column families or tables, a single row of which can be thought of as a record — a multi-dimensional key-value store.
These solutions are designed with the goal of scaling well enough to manage petabytes of data across as many as thousands of commodity servers in a massive, distributed system.
Although technically schema-free, wide column stores like Scylla and Cassandra use an SQL variant called CQL for data definition and manipulation, making them straightforward to those already familiar with RDBMS.
Document Stores, including MongoDB and Couchbase, are schema-free systems that store data in the form of JSON documents. Document stores are similar to key-value or wide column stores, but the document name is the key and the contents of the document, whatever they are, are the value.
In a document store, individual records do not require a uniform structure, can contain many different value types, and can be nested. This flexibility makes them particularly well-suited to manage semi-structured data across distributed systems.
Graph Databases, such as Neo4J and Datastax Enterprise Graph, represent data as a network of related nodes or objects in order to facilitate data visualizations and graph analytics.
A node or object in a graph database contains free-form data that is connected by relationships and grouped according to labels. Graph-Oriented Database Management Systems (DBMS) software is designed with an emphasis on illustrating connections between data points.
As a result, graph databases are typically used when analysis of the relationships between heterogeneous data points is the end goal of the system, such as in fraud prevention, advanced enterprise operations, or Facebook’s original friends graph.
Search Engines, such as Elasticsearch, Splunk, and Solr, store data using schema-free JSON documents. They are similar to document stores, but with a greater emphasis on making your unstructured or semi-structured data easily accessible via text-based searches with strings of varying complexity.
Since there are so many types and varied applications of NoSQL databases, it’s hard to nail these down, but generally:
- Schema-free data models are more flexible and easier to administer.
- NoSQL databases are generally more horizontally scalable and fault-tolerant.
- Data can easily be distributed across different nodes. To improve availability and/or partition tolerance, you can choose that data on some nodes be "eventually consistent".
These are also dependent on the database type.
- NoSQL databases are generally less widely adopted and mature than RDBMS solutions, so specific expertise is often required.
- There are a range of formats and constraints specific to each database type.
Which database is right for you?

- If ACID (Atomicity, Durability, Consistency, and Durability) compliance is your first priority, consider using RDBMS.
- If you have a massively distributed system and can settle for eventual consistency on some nodes/partitions, you might consider a wide column store such as Cassandra or Scylla.
- If your input data is particularly heterogeneous and difficult to encapsulate according to a normalization schema, consider using a NoSQL DBMS.
- If your goal is to scale vertically, consider an RDBMS; conversely, if you want to scale horizontally, a NoSQL DBMS may be preferable.
ACID properties are an important concept for databases. The acronym stands for Atomicity, Consistency, Isolation, and Durability.
The phrase "all or nothing" succinctly describes the first ACID property of atomicity. When an update occurs to a database, either all or none of the update becomes available to anyone beyond the user or application performing the update. This update to the database is called a transaction and it either commits or aborts. This means that only a fragment of the update cannot be placed into the database, should a problem occur with either the hardware or the software involved. Features to consider for atomicity:
a transaction is a unit of operation - either all the transaction's actions are completed or none are atomicity is maintained in the presence of deadlocks atomicity is maintained in the presence of database software failures atomicity is maintained in the presence of application software failures atomicity is maintained in the presence of CPU failures atomicity is maintained in the presence of disk failures atomicity can be turned off at the system level atomicity can be turned off at the session level
Consistency is the ACID property that ensures that any changes to values in an instance are consistent with changes to other values in the same instance. A consistency constraint is a predicate on data which serves as a precondition, post-condition, and transformation condition on any transaction.
The isolation portion of the ACID Properties is needed when there are concurrent transactions. Concurrent transactions are transactions that occur at the same time, such as shared multiple users accessing shared objects. This situation is illustrated at the top of the figure as activities occurring over time. The safeguards used by a DBMS to prevent conflicts between concurrent transactions are a concept referred to as isolation.
As an example, if two people are updating the same catalog item, it's not acceptable for one person's changes to be "clobbered" when the second person saves a different set of changes. Both users should be able to work in isolation, working as though he or she is the only user. Each set of changes must be isolated from those of the other users.
An important point in understanding isolation through transactions is serializability. Transactions are serializable when the effect on the database is the same whether the transactions are executed in serial order or in an interleaved fashion. The effect on the DBMS is that the transactions may execute in serial order based on consistency and isolation requirements. It is important to note that a serialized execution does not imply the first transactions will automatically be the ones that will terminate before other transactions in the serial order.
######## Degrees of isolation:
- degree 0 - a transaction does not overwrite data updated by another user or process ("dirty data") of other transactions
- degree 1 - degree 0 plus a transaction does not commit any writes until it completes all its writes (until the end of transaction)
- degree 2 - degree 1 plus a transaction does not read dirty data from other transactions
- degree 3 - degree 2 plus other transactions do not dirty data read by a transaction before the transaction commits
Maintaining updates of committed transactions is critical. These updates must never be lost. The ACID property of durability addresses this need. Durability refers to the ability of the system to recover committed transaction updates if either the system or the storage media fails.
######## Features to consider for durability:
- recovery to the most recent successful commit after a database software failure
- recovery to the most recent successful commit after an application software failure
- recovery to the most recent successful commit after a CPU failure
- recovery to the most recent successful backup after a disk failure
- recovery to the most recent successful commit after a data disk failure
Concurrency control and locking is the mechanism used by DBMSs for the sharing of data. Atomicity, consistency, and isolation are achieved through concurrency control and locking.
While many people may be reading the same data item at the same time, it is usually necessary to ensure that only one application at a time can change a data item. Locking is a way to do this. Because of locking, all changes to a particular data item will be made in the correct order in a transaction.
The amount of data that can be locked with the single instance or groups of instances defines the granularity of the lock.
- Page Locking
- Cluster Locking
- Class or Table Locking
- Object or Instance Locking
Page locking (or page-level locking) concurrency control involves all the data on a specific page being locked. A page is a common unit of storage in computer systems and is used by all types of DBMSs. Locking for objects is on the left and page locking for relational tuples is on the right. If the concept of pages is new to you, just think of a page as a unit of space on the disk where multiple data instances are stored.
Cluster locking or container locking for concurrency control means all data clustered together (on a page or multiple pages) will be locked simultaneously. This applies only to clusters of objects in ODBMSs (Object database management systems).
Class or table locking means that all instances of either a class or table are locked.
Instance locking locks a single relational tuple in an RDBMS or a single object in an ODBMS
Database normalization is process used to organize a database into tables and columns. The idea is that a table should be about a specific topic and that only those columns which support that topic are included. For example, a spreadsheet containing information about sales people and customers serves several purposes:
- Identify sales people in your organization
- List all customers your company calls upon to sell product
- Identify which sales people call on specific customers.
By limiting a table to one purpose you reduce the number of duplicate data that is contained within your database, which helps eliminate some issues stemming from database modifications.
To assist in achieving these objectives, some rules for database table organization have been developed. The stages of organization are called normal forms in database normalisation; there are three normal forms / rules most databases adhere to using.
As tables satisfy each successive database normalization form, they become less prone to database modification anomalies and more focused toward a sole purpose or topic.
There are three main reasons to normalize a database.
- 1NF - minimize duplicate data
- 2NF - minimize or avoid data modification issues
- 3NF - simplify queries.
There are several additional forms, such as BCNF, but I consider those advanced, and not too necessary to learn in the beginning.
The forms are progressive, meaning that to qualify for 3rd normal form a table must first satisfy the rules for 2nd normal form, and 2nd normal form must adhere to those for 1st normal form. Before we discuss the various forms and rules in detail, let’s summarize the various forms:
First Normal Form – The information is stored in a relational table and each column contains atomic values, and there are not repeating groups of columns. Second Normal Form – The table is in first normal form and all the columns depend on the table’s primary key. Third Normal Form – the table is in second normal form and all of its columns are not transitively dependent on the primary key.
Official documentation https://dev.mysql.com/doc/
MySQL Workbench
Official documentation https://docs.microsoft.com/en-us/sql/sql-server/sql-server-technical-documentation?view=sql-server-2017
Official documentation https://www.postgresql.org/docs/manuals/
Create user with global privileges
CREATE USER test ENCRYPTED PASSWORD 'password';
GRANT CONNECT ON SCHEMA "your-schema" TO test;
GRANT USAGE ON SCHEMA "your-schema" TO test;
GRANT CREATE ON SCHEMA "your-schema" TO test;
GRANT EXECUTE ON ALL FUNCTIONS IN SCHEMA "your-schema" TO test;
GRANT SELECT ON ALL SEQUENCES IN SCHEMA "your-schema" TO test;
GRANT ALL PRIVILEGES ON ALL TABLES IN SCHEMA your-schema TO test;
Per table
GRANT ALL PRIVILEGES ON TABLE your-table TO test;
Privileges Description SELECT Ability to execute SELECT operators for a table. INSERT Ability to execute INSERT operators for a table. UPDATE Ability to execute UPDATE operators for a table. DELETE Ability to execute DELETE operators for a table. TRUNCATE Ability to execute TRUNCATE operators on a table. REFERENCES Ability to create external keys (requires privileges for both parent and child tables). TRIGGER Ability to create triggers for a table. CREATE Ability to perform CREATE TABLE operators. ALL Provides all privileges.
Official documentation https://docs.mongodb.com
Official documentation https://redis.io/documentation
Official documentation http://cassandra.apache.org/doc/latest/
Official Documentation http://docs.couchdb.org/en/stable/
The best guide to GIT Flow (in my opinion of course) https://www.atlassian.com/git/tutorials/comparing-workflows/gitflow-workflow
Commitzen CLI https://github.com/commitizen/cz-cli
Semantic versioning guide https://semver.org/ NPM Semantic versioning guide https://docs.npmjs.com/about-semantic-versioning
https://www.npmjs.com/package/semantic-release - Automate how your NPM package.json file versions are incremented when releasing a package.
- Google HTML and CSS Code Standards https://google.github.io/styleguide/htmlcssguide.htmlRDFa is an extension to HTML5 that helps you markup things like People, Places, Events, Recipes and Reviews. Search Engines and Web Services use this markup to generate better search listings and give you better visibility on the Web, so that people can find your website more easily.
You may face dozens of different issues when it comes to scaling. A few general sources of your problems may be related to:
- Limited physical resources like memory, CPUs, etc.,
- Wrong memory management
- Inefficient database engine
- The complicated database schema, bad indexing
- Poorly performed database queries
- Wrong server configuration
- App server limitations
- Overall spaghetti code
- Inefficient caching
- Lack of monitoring tools
- Too many external dependencies
- Improper background jobs design
https://www.scalyr.com/blog/horizontal-scalability-software/
https://www.ibm.com/developerworks/aix/tutorials/clustering/clustering.html
https://www.ibm.com/cloud/learn/load-balancing
- Official website https://www.docker.com/
- Docker Hub https://hub.docker.com/
https://docs.docker.com/engine/swarm/ - Docker Swarm Documentation
- Docker Desktop https://www.docker.com/products/docker-desktop
- Kitematic (Simple to use GUI tool to provision docker containers on your desktop). https://kitematic.com/
- Kubernetes https://kubernetes.io/
TBW
TBW
TBW
TBW
TBW
TBW
TBW
TBW
TBW
PCI ( Payment Card Industry) Compliance https://www.pcicomplianceguide.org/faq/
Software license guide https://choosealicense.com/licenses/
Scrum.org Guide https://www.scrumguides.org/scrum-guide.html Scrum at Scale Guide https://www.scrumatscale.com/scrum-at-scale-guide-read-online/
Product Owner Role https://www.mountaingoatsoftware.com/agile/scrum/roles/product-owner Scrum Master Role https://www.mountaingoatsoftware.com/agile/scrum/roles/scrummaster Scrum Team Role https://www.mountaingoatsoftware.com/agile/scrum/roles/team
Principles of LEAN Development https://leankit.com/learn/lean/principles-of-lean-development/
The LEAN Startup by Eric Ries http://theleanstartup.com/
https://www.blueprintsys.com/agile-development-101/agile-methodologies - A guide to Agile Methodologies
https://www.techopedia.com/definition/3791/extreme-programming-xp
- JIRA https://www.atlassian.com/software/jira
- JIRA Ops https://www.atlassian.com/software/jira/ops
- Confluence https://www.atlassian.com/software/confluence
- TeamCITY https://www.jetbrains.com/teamcity/
- TFS (Microsoft Team Services) (Now Azure Devops Server) https://azure.microsoft.com/en-us/services/devops/server/
- Lists, boards and cards https://trello.com/
OData Standard https://www.odata.org/documentation/
Funnily enough the Wikipedia page for REST provides a great overview https://en.wikipedia.org/wiki/Representational_state_transfer
Standard HTTP Methods https://cloud.google.com/apis/design/standard_methods Resource oriented design https://cloud.google.com/apis/design/resources
JSON Web Token (JWT) is an open standard (RFC 7519) that defines a compact and self-contained way for securely transmitting information between parties as a JSON object. This information can be verified and trusted because it is digitally signed. JWTs can be signed using a secret (with the HMAC algorithm) or a public/private key pair using RSA or ECDSA.
Cross-site Scripting (XSS) attacks: Storing tokens in either local or session storage can lead to XSS attacks. Because of this, it’s a good idea to store tokens in a cookie with httpOnly and secure flags.
OAuth 2.0 is the industry-standard protocol for authorization. OAuth 2.0 supersedes the work done on the original OAuth protocol created in 2006. OAuth 2.0 focuses on client developer simplicity while providing specific authorization flows for web applications, desktop applications, mobile phones, and living room devices. This specification and its extensions are being developed within the IETF OAuth Working Group.
https://spring.io/understanding/HATEOAS
Swagger (Self documenting your API) https://swagger.io/
JAVA Spring Framework https://spring.io/ Pivotal Cloud Foundry (Manage your project, develop, builkd test deploy) https://pivotal.io/platform , https://pivotal.io/learn
Awesome PHP https://github.com/ziadoz/awesome-php (Comprehensive .NET Development Bookmarks)
Official documentation http://php.net/manual/en/ Composer (The best PHP package manager for dependency management) https://getcomposer.org/ Laravel (One of the best PHP Frameworks) - https://laravel.com/ Eloquent ORM - https://laravel.com/docs/8.x/eloquent Artisan console https://laravel.com/docs/8.x/artisan Symfony (Also one of the best PHP Frameworks) - https://symfony.com/ Silex - Lightweight PHP Framework https://silex.symfony.com/ Wordpress Codex - Build your applications on top of wordpress with custom themes, plugins etc - https://codex.wordpress.org/
Official documentation https://guides.rubyonrails.org/
Awesome .NET https://github.com/quozd/awesome-dotnet (Comprehensive .NET Development Bookmarks)
NuGet package manager https://www.nuget.org/ .NET Entity Framework https://docs.microsoft.com/en-us/ef/ Azure devops (Will succeed Nuget private servers) https://azure.microsoft.com/en-gb/services/devops/
The blockchain is now used in most industries to improve trust and transparency as well as provide an immutable record of distributed data.
Many people have heard of bitcoin but distributed ledger technology provides potentially more valuable technologies.
- Peer to peer cash (Everyone becomes their own bank)
- Programmable money and universal cash without government inflation.
- Automated brokering
- Removal of third party intermediaries
- Distributed organisations with no central control
- Truly consensus based platform
- Uncensorable data
How blockchain is alredy taking over (Coldfusion) https://www.youtube.com/watch?v=kP6EezXJKNM How big is Bitcoin? https://www.youtube.com/watch?v=zrY3i85W5tU
Bitcoin whitepaper https://bitcoin.org/bitcoin.pdf
EOS Developers Portal https://developers.eos.io/
Web3 API https://github.com/ethereum/wiki/wiki/JavaScript-API
Truffle https://github.com/trufflesuite/truffle Ganache https://truffleframework.com/ganache
https://storj.io/ - Distributed data storage with clients earning tokens for the storage they provide.
https://aframe.io/ - Aframe WebVR Specification https://webvr.info/ WebVR Experiments https://experiments.withgoogle.com/collection/webvr
To close a port in Windows, you need to find the process ID of the application or service that opened the connection. Then, you can terminate the process or configure the application or service.
netstat -ano | find ":3306" TCP [::]:3306 [::]:0 LISTENING 33208
Use the process ID from the previous step to identify the application or service that owns that process.
tasklist /F /PID 33208 Image Name PID Services mysqld.exe 33208 N/A
If the application is not needed, use the process ID from the second step to terminate the process.
taskkill /F /PID 33208 SUCCESS: The process with PID 33208 has been terminated.
verify that the process is killed.
netstat -ano | find ":3306"
TBW
TBW
https://github.com/vinta/awesome-python - A curated list of awesome Python frameworks, libraries, software and resources.
User Guide https://pip.pypa.io/en/stable/user_guide/
https://docs.djangoproject.com/en/3.0/
https://flask.palletsprojects.com/en/1.1.x/
https://github.com/davedoesdev/python-jwt - Generate JSON Web Tokens for Authentication https://github.com/jazzband/django-oauth-toolkit - Handle authentication using OAuth 2
You can get to know the OS architecture by running the below simple command.
wmic os get OSArchitecture
systeminfo | findstr /C:"Install Date"
Stop-Process -Name ApplicationName
Stop-process -Name Chrome
Stop-process -Id processId
wmic useraccount where name='loginId' set PasswordRequired=false
wmic useraccount set PasswordRequired=false
wmic useraccount where name='test1' set PasswordRequired=true
netsh interface set interface name="Local Area Connection" admin=DISABLED
Do you want to change the look of Windows command prompt by changing background color? Windows command prompt has default color settings of black background and white foreground(text). This post explains you how to to change background/foreground colors using ‘color’ command.
‘Color’ command uses below codes to represent various colors.
0 = Black 8 = Gray
1 = Blue 9 = Light Blue
2 = Green A = Light Green
3 = Aqua B = Light Aqua
4 = Red C = Light Red
5 = Purple D = Light Purple
6 = Yellow E = Light Yellow
7 = White F = Bright White
Once you decide on which colors to use, just input the codes to the command. For example, if you want to use white background with Light blue for text, you should run the below command.
color 79
If you have a WiFi connection, how do you find out if your computer is connected to WiFi or not? The command netsh interface is used to find your WiFi connection status from command prompt.
Execute the below command to know WiFi connection status
netsh interface show interface | findstr /C:"Wireless" /C:"Name"
Example on my Windows 7 computer
C:\>netsh interface show interface | findstr /C:"Wireless" /C:"Name"
Admin State State Type Interface Name
Enabled Connected Dedicated Wireless Network Connection
As you can see, the command shows that Wifi connection is connected when we ran the command.
If the computer has WiFi enabled, but not connected to any network, then the command output would be like below.
C:\>netsh interface show interface | findstr /C:"Wireless" /C:"Name"
Admin State State Type Interface Name
Enabled Disconnected Dedicated Wireless Network Connection
If the Wifi is disabled, then the output would be
C:\>netsh interface show interface | findstr /C:"Wireless" /C:"Name"
Admin State State Type Interface Name
Disabled Disconnected Dedicated Wireless Network Connection
This command helps to know the status manually. However if we want to know the status in a script, we would need to refine the command further.