When digging into #80, I decided to see how GLM implemented vector normalization. Turns out their approach is pretty clever:
v * inversesqrt(dot(v, v));
This avoids both an actual square root and a division by exploiting the fact that inverse square roots are cheap and that dot(v, v) gives you the magnitude of the vector squared.
I ran some quickbench benchmarks with the following results:
No optimization
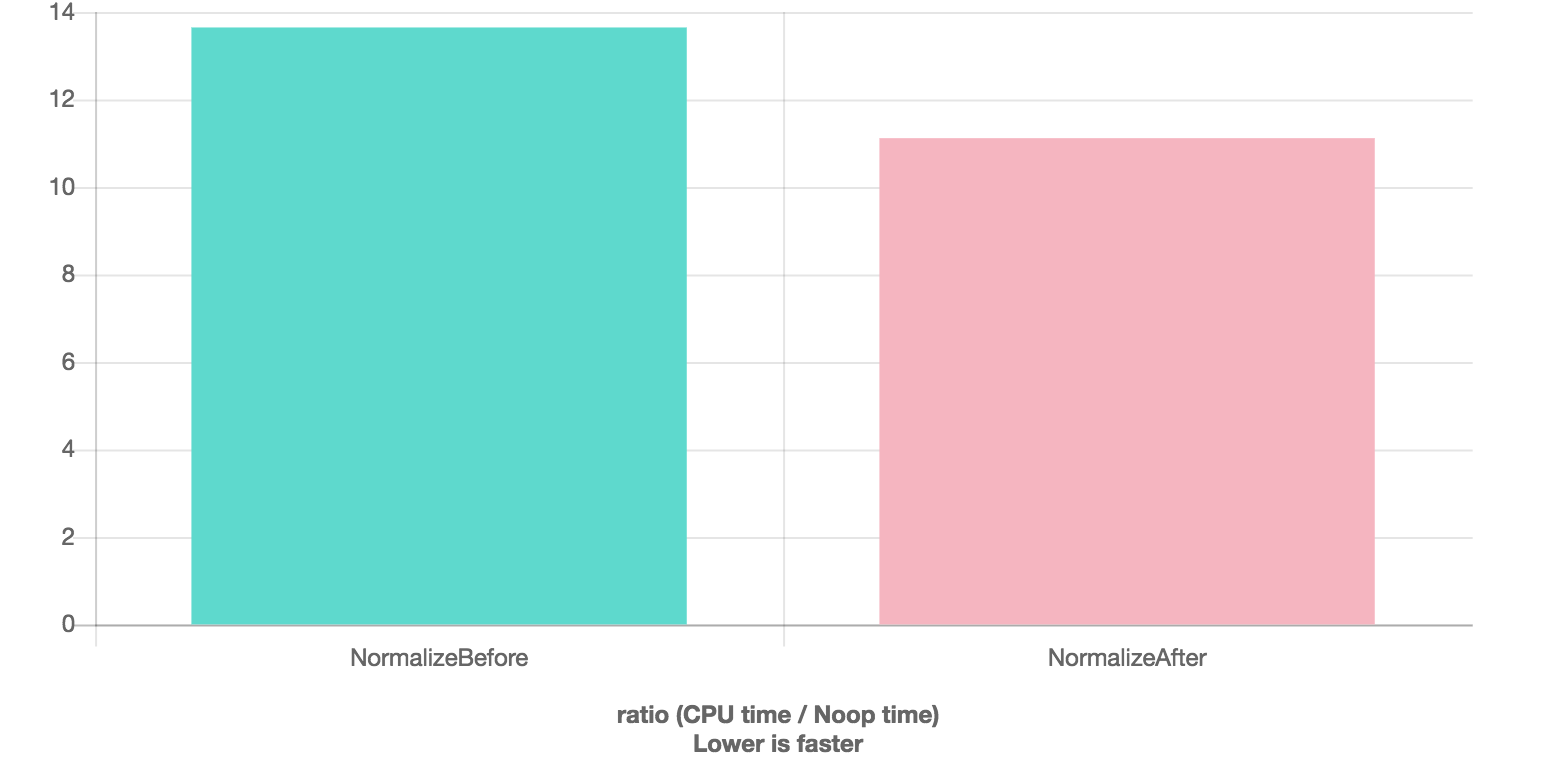
-O1

-O3
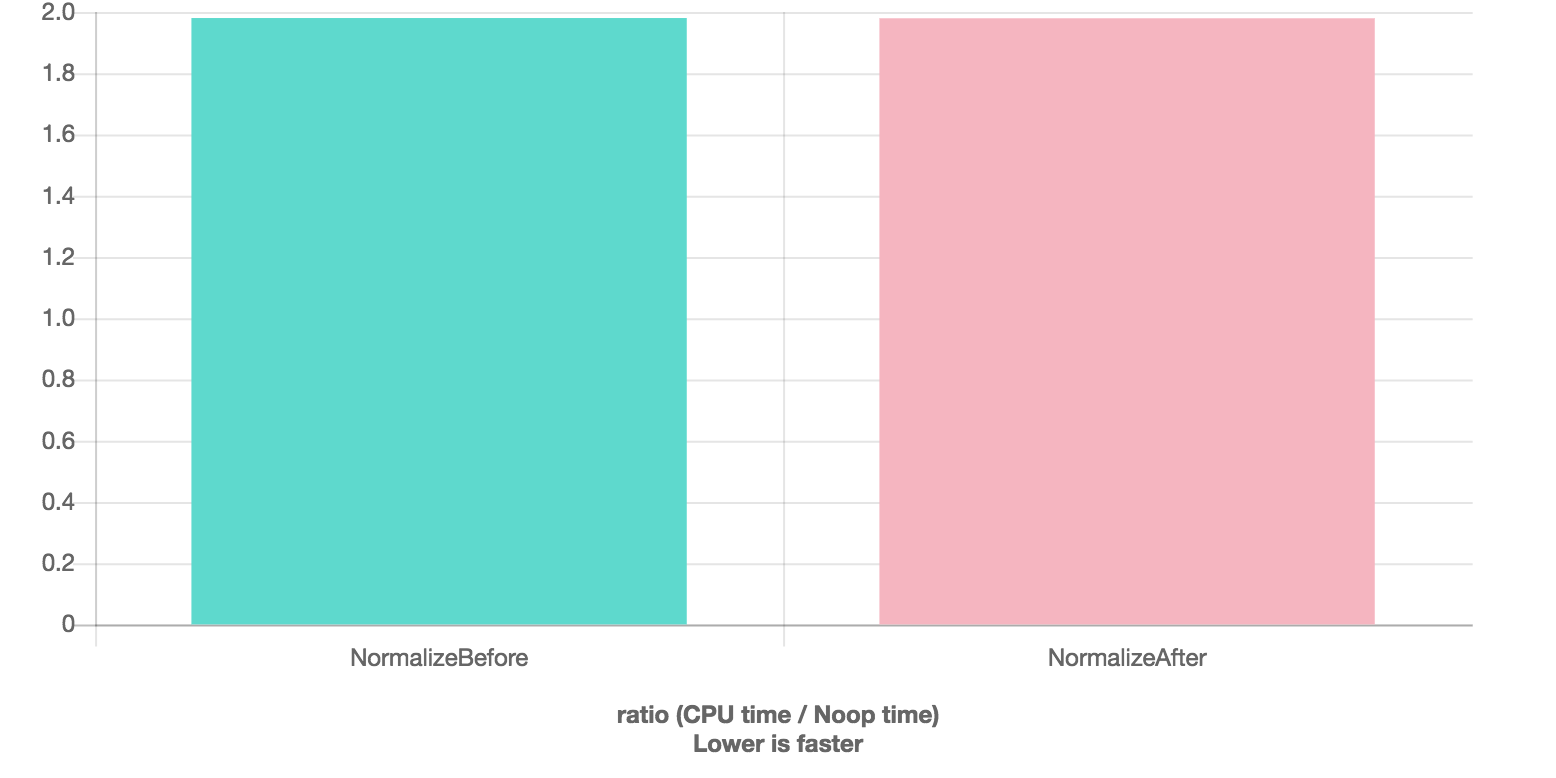
This is a pretty nice speedup for unoptimized builds (about 25%) and it could really help performance on processor architectures that hate square roots and divisions. (See concerns in #80.) So, we should probably do this.
When digging into #80, I decided to see how GLM implemented vector normalization. Turns out their approach is pretty clever:
This avoids both an actual square root and a division by exploiting the fact that inverse square roots are cheap and that
dot(v, v)gives you the magnitude of the vector squared.I ran some quickbench benchmarks with the following results:
No optimization
-O1
-O3
This is a pretty nice speedup for unoptimized builds (about 25%) and it could really help performance on processor architectures that hate square roots and divisions. (See concerns in #80.) So, we should probably do this.