This repository contains a machine learning model used for sound source separation. Model uses Visual and audio features to separate different audio sources from single duet video. Model has similar structure to the model introduced in paper https://arxiv.org/pdf/1804.03160.pdf.
This project was done as a part of a bachelor's thesis which studies the modern approach for sound source separation.
Following the instructions below allows user to run the model on wanted data. Data used in the study was the dataset downloadable from https://github.com/roudimit/MUSIC_dataset.
- Anaconda or another virtual environment manager.
- Some video data which has a singular music/sound source (preferable the same data used in the study)
- Python libraries in requirements.txt file
Clone the repository to your local computer and then set up desired settings from arguments.py.
Before training the networks, data needs to be stored and the path to data defined. Train the audio model with command "python main.py" and setting "trainAudio" has to be True. If only visual network training desired, "trainAudio" must be False and "trainFrame" must be True.
After the networks has been trained, you can evaluate the model with setting "evalCombined" being True and then running the main script. To evaluate the performance on duet videos, run script with setting "evalDuet" being True.
Model outputs two spectrograms that can be formed back to a separated audio track. For training, two videos are combined and their mixture is used to train the model and as an output, the two videos' audios are separated from the mixture. As for using the model on duet audio, the input is a video with two instruments playing and the output is each instrument track separately.
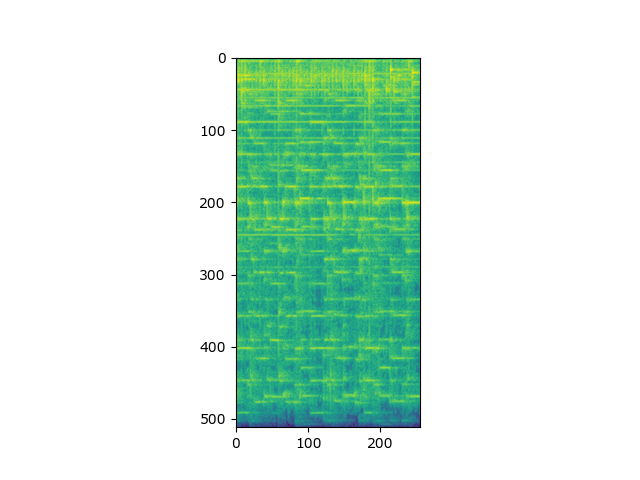
Example training sample output:
Input audio mixture spectogram:
Instrument 1 Frame:

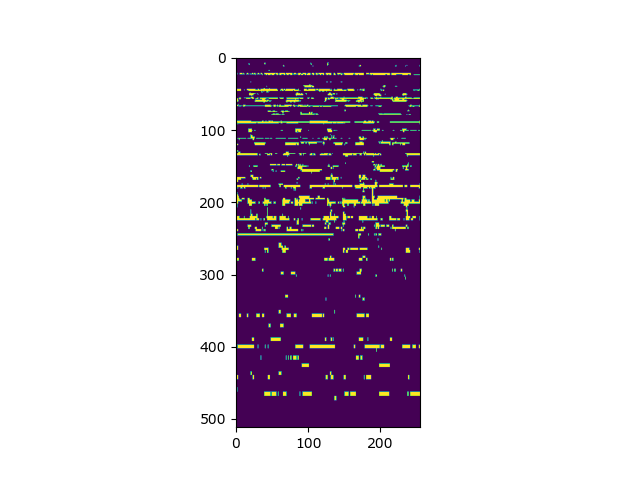
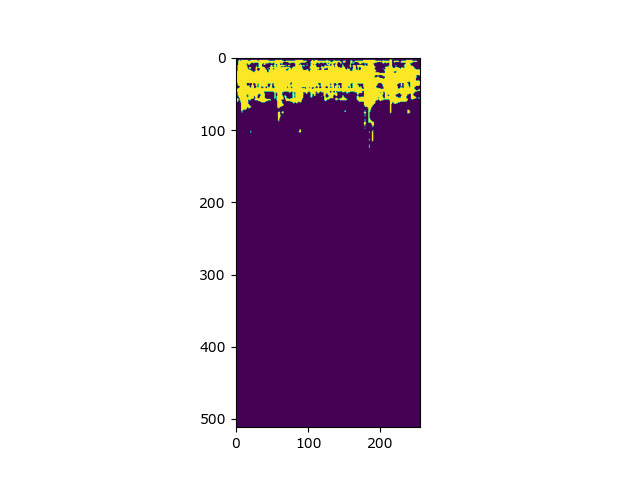
Instrument 1 Ground Truth Audio Spectrogram Binary Mask:
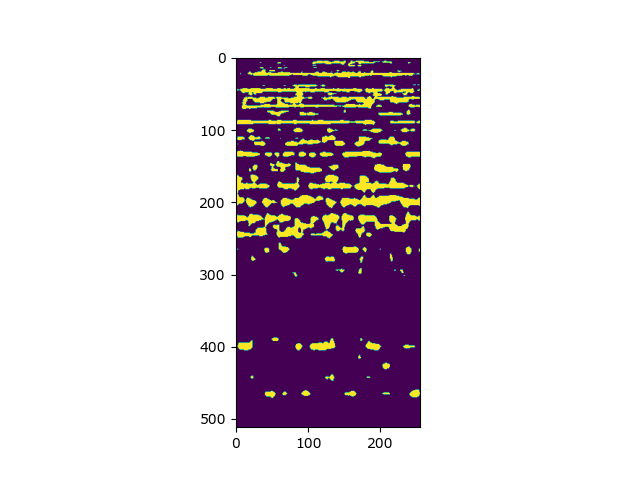
Instrument 1 Predicted Audio Spectrogram Binary Mask:
Instrument 2 Frame:

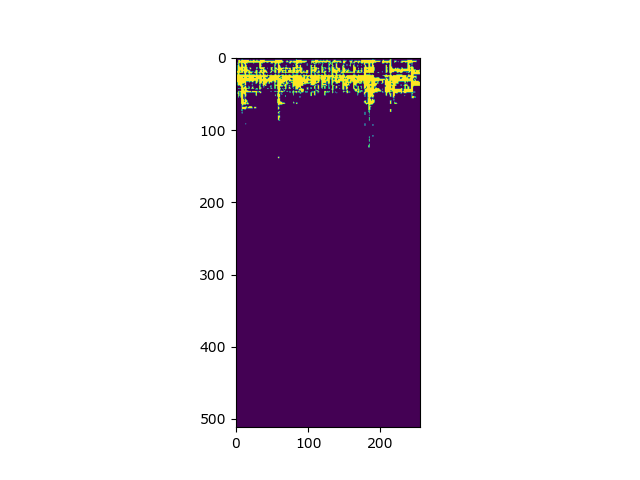
Instrument 2 Ground Truth Audio Spectrogram Binary Mask:
Instrument 2 Predicted Audio Spectrogram Binary Mask:
Two duet outputs:

Petteri Nuotiomaa Github:Notsk1
As mentioned before, the techniques used were inspired from many sources, but most prominently from the paper https://arxiv.org/pdf/1804.03160.pdf.