
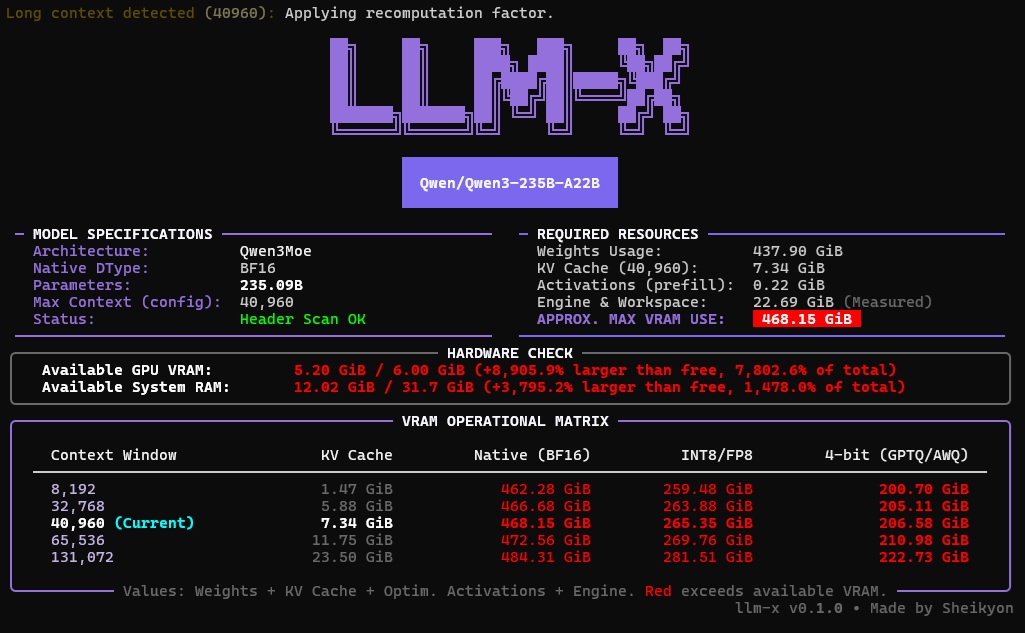
LLM-X is a CLI-first library designed to provide highly-precise, hardware-aware metrics for large language model inference requirements. It supports a wide range of architectures via SafeTensors and Hugging Face integration.
- Memory Deficit/Surplus Analysis:
- Calculate as a percentage memory deficits (when memory is not sufficient for inference) and memory surpluses (when memory is sufficient for inference), also considering that memory in use by the operating system and other processes.
- Example: A +480.7% deficit alert immediately informs the user that the model is nearly 5x larger than the available GPU memory. In the absence of an available or detected GPU, the user will be informed that the deficit is not in VRAM but in RAM.
- Dynamic Overhead Awareness:
- Through
psutiland NVML (nvidia-ml-py), LLM-X determines whether the model can fit in GPU memory (VRAM) or system memory (RAM).
- Through
- Resources Required According to Quantization Levels
- LLM-X offers a comparative matrix with the resources required for inference according to different levels of quantization and context windows.
Since it is a native Python library, it can be easily installed via PyPI using pip.
pip install llm-x-py
It can also be installed by cloning this repository and installing it locally.
git clone https://github.com/Sheikyon/LLM-X.gitcd LLM-Xpip install .
-
Core Estimation (
--model-src,-m)- Model Sources
- Local: Absolute paths or
.for the current directory. - Remote: Hugging Face Model IDs or full repository URLs.
- Local: Absolute paths or
- Inference Configuration
- Context Window (
--context,-c): Set specific token limits. - Batch Size (
--batch,-b): Defaults to 1. - KV Cache Settings:
- Precision (
--kv-dtype,-q): Data type for the cache (e.g., BF16). - Quantization (
--kv-quant): Compression method for the KV cache.
- Precision (
- Context Window (
- Model Sources
-
Hugging Face Token Management
- Add (
--set-new-token): Save and automatically sort new access tokens. - Select (
--set-token): Set an existing token as the active one by ID. - List (
--token-list): Displays arichtable with IDs, Active status, and previews.
- Add (
-
Token Cleanup
- Single (
--del-token): Delete a specific token by index. - Purge (
--del-all-tokens): Remove all stored tokens from the system.
- Single (
Using a Qwen2.5-7B (BF16) at 131,072 context as a benchmark:
| Metric | hf-mem | Accelerate | LLM-X (Ours) | Status |
|---|---|---|---|---|
| Weights (BF16) | 14.19 GiB | 13.17 GiB | 14.19 GiB | Consistent |
| KV Cache (131k) | 0.00 GiB | 0.00 GiB | 14.00 GiB | Ignored |
| Engine Overhead | 0.00 GiB | 0.00 GiB | 2.12 GiB | Ignored |
| Total VRAM Required | 14.19 GiB | 13.17 GiB | 30.31 GiB | Reality |
| Error Rate | 113.6% | 130.1% | 1.8% |
LLM-X achieves an accuracy rate of ≈ 98.2%, closely matching the empirical metrics of torch.cuda.memory_allocated(), which tracks actual tensors allocated in memory. This also results in an error rate of only ≈ 1.8% in supported models.