Give scans control over cache via scan dispatchers #1383#1440
Give scans control over cache via scan dispatchers #1383#1440keith-turner merged 2 commits intoapache:masterfrom
Conversation
This commit enables per scan control over cache usages. This was done via extending the scope of ScanDispatchers to include cache control. The built in SimpleScanDispatcher was improved to support mapping scanner execution hints of the form scan_type=X to cache usage directives for a scan. Accumulo caches open files. Before this change the cache was bound to the file when it was opened. Now a cache can be bound to an already open file. The internal interface CacheProvider was created to facilitate this.
|
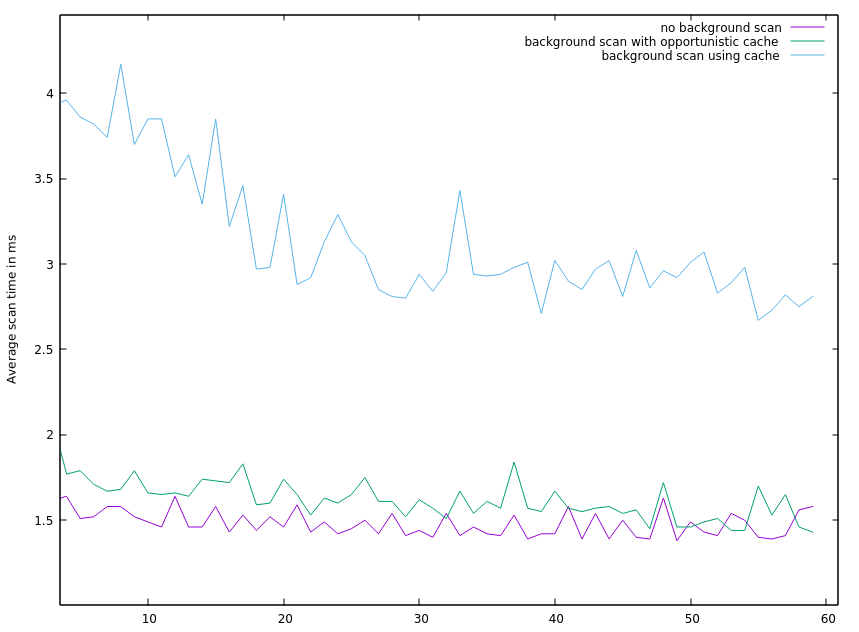
I ran a performance test on a small EC2 cluster to give this a try. I had the following setup.
For the threads doing random lookup on a subset of the table, their data just fit in the data cache. The full table did not fit into the cache. For this test scenario all of the data was local for each tserver and it fit in the OS cache, so a cache miss was not terribly slow. Also HDFS was optimized for local data. Cache misses were noticeable from a latency perspective, which is all I cared about. I ran three test all setup with the following Accumulo shell commands. This makes all the scans that set the execution hint For one test run I set the following to make scans that set the execution hint For another test run I set the following to make scans that set the execution hint For the last test run, I just did not run background scans. I only ran the scans doing random lookups. Below are the average time for the scans doing random lookups for the three test runs. If I ran in a situation where cache misses had higher latency, I suspect the plot would differ more dramatically. I wish I had run a 4th test where the random lookup threads did not use cache. In all three test the random lookup threads always used cache.
|
This commit enables per scan control over cache usages. This was done
via extending the scope of ScanDispatchers to include cache control.
The built in SimpleScanDispatcher was improved to support mapping
scanner execution hints of the form scan_type=X to
cache usage directives for a scan.
Accumulo caches open files. Before this change the cache was bound to
the file when it was opened. Now a cache can be bound to an already
open file. The internal interface CacheProvider was created to
facilitate this.