Dont create duplicate dag file processors#11875
Dont create duplicate dag file processors#11875pingzh wants to merge 1 commit intoapache:masterfrom pingzh:ping.zhang-fix-duplicate-dag-processor
Conversation
Context: when a dag file is under processing and multiple callbacks are created either via zombies or executor events, the dag file is added to the _file_path_queue and the manager will launch a new process to process it, which it should not since the dag file is currently under processing. This will bypass the _parallelism eventually especially when it takes long time to process some dag files. We have seen ~200 dag processors on the scheduler even we set the _parallelism as 60. More dag file processors make CPU spike and in turn it makes the dag file processing even slower. In the end, the scheduler is taken down.
| manager._file_path_queue = [f1, f2] | ||
| files_paths_to_exclude_in_this_loop = {f1} | ||
|
|
||
| manager.start_new_processes(files_paths_to_exclude_in_this_loop) |
There was a problem hiding this comment.
This is too tightly coupled to the way this is implemented, rather than the goal.
Also the fact that you can't esaily test this probably means you need to re-think the a.pproach
There was a problem hiding this comment.
if the manager loop calls prepare_file_path_queue() in every loop, we don't need this change (passing files_paths_to_exclude_in_this_loop to the start_new_processes.
It is only called when if not self._file_path_queue. If we remove this, we will also need to to some dupe work in the prepare_file_path_queue
There was a problem hiding this comment.
i chose to have files_paths_to_exclude_in_this_loop inside the start_new_processes as i was thinking that is single place we do a pop(0) and start new process, so adding a check will guarantee it won't double process dag files.
|
Are you sure this is still a problem on mainline. Looking at start_new_processes: def start_new_processes(self):
"""Start more processors if we have enough slots and files to process"""
while self._parallelism - len(self._processors) > 0 and self._file_path_queue:
file_path = self._file_path_queue.pop(0)
callback_to_execute_for_file = self._callback_to_execute[file_path]
processor = self._processor_factory(
file_path,
callback_to_execute_for_file,
self._dag_ids,
self._pickle_dags)
del self._callback_to_execute[file_path]
Stats.incr('dag_processing.processes')
processor.start()
self.log.debug(
"Started a process (PID: %s) to generate tasks for %s",
processor.pid, file_path
)
self._processors[file_path] = processor
self.waitables[processor.waitable_handle] = processorI can't see at first glance how |
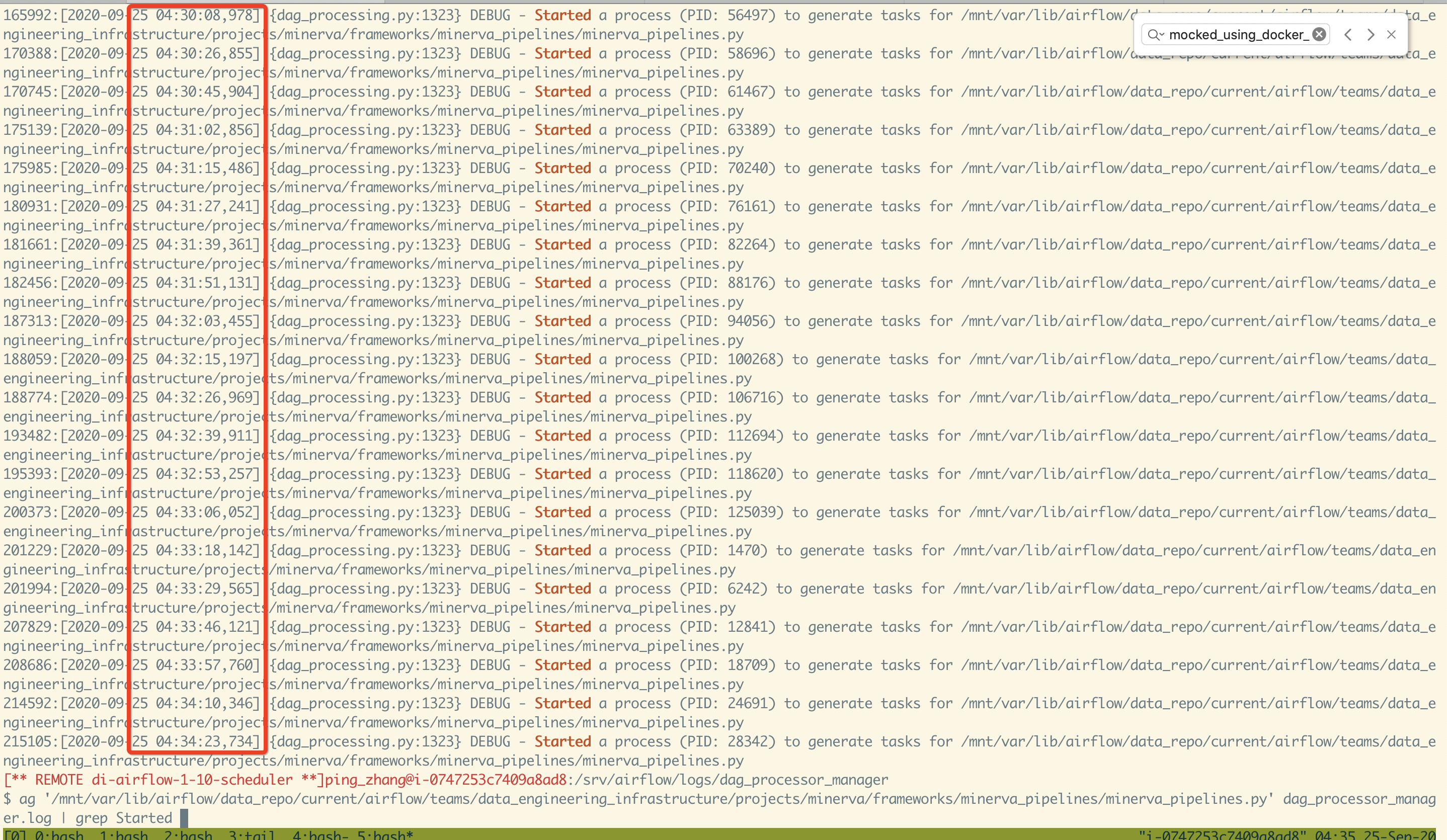
Yes, it still an issue, the main logic to launch new dag file processes does not change much between The issue does not happen often. This is the incident leading us to find this issue. As you can see, the same dag file is processing many times (the dag process for this dag file usually takes more than 15 min)
when the manager adds the callback to the As for the exceed of the |
Yes, this is "by design" -- if there's a callback we need to execute it "now" to run it. https://github.com/apache/airflow/blob/master/airflow/utils/dag_processing.py#L713-L718 Given we remove it form the list if it's already there, and the existing checks I'm not sure the two "issues" are related (1- jumping up the queue/ignoring cool down period, and 2- going beyond concurrency limits) |
However, the original design has a risk of letting a dag file with a long processing time to take over all dag processors and also introduce a race condition Race condition case:
|
|
I'm not yet convinced that this is a) actually a bug, or b) the right solution. Changing the milestone for now, and it can come in 2.0.x or 2.1 |
When a dag file is executed via Dag File Processors and multiple callbacks are created either via zombies or executor events, the dag file is added to the _file_path_queue and the manager will launch a new process to process it, which it should not since the dag file is currently under processing. This will bypass the _parallelism eventually especially when it takes long time to process some dag files. This address the same issue as apache#11875 but instead does not exlucde filepaths that are recently processed and that run at limit (which is only used in tests) when Callbacks are sent by the Agent. This is by design as execution of Callbacks is critical. This is done with a caveat to avoid duplicate processor -- i.e. if a processor exists, instead of removing the file path from the queue it is removed from the beginning of the queue to the end. This means that the processor with the filepath to run callback is still run before other filepaths are added. Tests are added to check the same. closes apache#13047
When a dag file is executed via Dag File Processors and multiple callbacks are created either via zombies or executor events, the dag file is added to the _file_path_queue and the manager will launch a new process to process it, which it should not since the dag file is currently under processing. This will bypass the _parallelism eventually especially when it takes a long time to process some dag files and since self._processors is just a dict with file path as the key. So multiple processors with the same key count as one and hence parallelism is bypassed. This address the same issue as apache#11875 but instead does not exclude file paths that are recently processed and that run at the limit (which is only used in tests) when Callbacks are sent by the Agent. This is by design as the execution of Callbacks is critical. This is done with a caveat to avoid duplicate processor -- i.e. if a processor exists, the file path is removed from the queue. This means that the processor with the file path to run callback will be still run when the file path is added again in the next loop Tests are added to check the same. closes apache#13047 closes apache#11875 (cherry picked from commit 32f5953)
When a dag file is executed via Dag File Processors and multiple callbacks are created either via zombies or executor events, the dag file is added to the _file_path_queue and the manager will launch a new process to process it, which it should not since the dag file is currently under processing. This will bypass the _parallelism eventually especially when it takes a long time to process some dag files and since self._processors is just a dict with file path as the key. So multiple processors with the same key count as one and hence parallelism is bypassed. This address the same issue as #11875 but instead does not exclude file paths that are recently processed and that run at the limit (which is only used in tests) when Callbacks are sent by the Agent. This is by design as the execution of Callbacks is critical. This is done with a caveat to avoid duplicate processor -- i.e. if a processor exists, the file path is removed from the queue. This means that the processor with the file path to run callback will be still run when the file path is added again in the next loop Tests are added to check the same. closes #13047 closes #11875 (cherry picked from commit 32f5953)
When a dag file is executed via Dag File Processors and multiple callbacks are created either via zombies or executor events, the dag file is added to the _file_path_queue and the manager will launch a new process to process it, which it should not since the dag file is currently under processing. This will bypass the _parallelism eventually especially when it takes a long time to process some dag files and since self._processors is just a dict with file path as the key. So multiple processors with the same key count as one and hence parallelism is bypassed. This address the same issue as apache/airflow#11875 but instead does not exclude file paths that are recently processed and that run at the limit (which is only used in tests) when Callbacks are sent by the Agent. This is by design as the execution of Callbacks is critical. This is done with a caveat to avoid duplicate processor -- i.e. if a processor exists, the file path is removed from the queue. This means that the processor with the file path to run callback will be still run when the file path is added again in the next loop Tests are added to check the same. closes apache/airflow#13047 closes apache/airflow#11875 (cherry picked from commit 32f59534cbdb8188e4c8f49d7dfbb4b915eaeb4d) GitOrigin-RevId: b446d145e1e5042e453ba91e34ae97573f320f09
When a dag file is executed via Dag File Processors and multiple callbacks are created either via zombies or executor events, the dag file is added to the _file_path_queue and the manager will launch a new process to process it, which it should not since the dag file is currently under processing. This will bypass the _parallelism eventually especially when it takes a long time to process some dag files and since self._processors is just a dict with file path as the key. So multiple processors with the same key count as one and hence parallelism is bypassed. This address the same issue as apache/airflow#11875 but instead does not exclude file paths that are recently processed and that run at the limit (which is only used in tests) when Callbacks are sent by the Agent. This is by design as the execution of Callbacks is critical. This is done with a caveat to avoid duplicate processor -- i.e. if a processor exists, the file path is removed from the queue. This means that the processor with the file path to run callback will be still run when the file path is added again in the next loop Tests are added to check the same. closes apache/airflow#13047 closes apache/airflow#11875 GitOrigin-RevId: 32f59534cbdb8188e4c8f49d7dfbb4b915eaeb4d
When a dag file is executed via Dag File Processors and multiple callbacks are created either via zombies or executor events, the dag file is added to the _file_path_queue and the manager will launch a new process to process it, which it should not since the dag file is currently under processing. This will bypass the _parallelism eventually especially when it takes a long time to process some dag files and since self._processors is just a dict with file path as the key. So multiple processors with the same key count as one and hence parallelism is bypassed. This address the same issue as apache/airflow#11875 but instead does not exclude file paths that are recently processed and that run at the limit (which is only used in tests) when Callbacks are sent by the Agent. This is by design as the execution of Callbacks is critical. This is done with a caveat to avoid duplicate processor -- i.e. if a processor exists, the file path is removed from the queue. This means that the processor with the file path to run callback will be still run when the file path is added again in the next loop Tests are added to check the same. closes apache/airflow#13047 closes apache/airflow#11875 GitOrigin-RevId: 32f59534cbdb8188e4c8f49d7dfbb4b915eaeb4d
When a dag file is executed via Dag File Processors and multiple callbacks are created either via zombies or executor events, the dag file is added to the _file_path_queue and the manager will launch a new process to process it, which it should not since the dag file is currently under processing. This will bypass the _parallelism eventually especially when it takes a long time to process some dag files and since self._processors is just a dict with file path as the key. So multiple processors with the same key count as one and hence parallelism is bypassed. This address the same issue as apache/airflow#11875 but instead does not exclude file paths that are recently processed and that run at the limit (which is only used in tests) when Callbacks are sent by the Agent. This is by design as the execution of Callbacks is critical. This is done with a caveat to avoid duplicate processor -- i.e. if a processor exists, the file path is removed from the queue. This means that the processor with the file path to run callback will be still run when the file path is added again in the next loop Tests are added to check the same. closes apache/airflow#13047 closes apache/airflow#11875 GitOrigin-RevId: 32f59534cbdb8188e4c8f49d7dfbb4b915eaeb4d
When a dag file is executed via Dag File Processors and multiple callbacks are created either via zombies or executor events, the dag file is added to the _file_path_queue and the manager will launch a new process to process it, which it should not since the dag file is currently under processing. This will bypass the _parallelism eventually especially when it takes a long time to process some dag files and since self._processors is just a dict with file path as the key. So multiple processors with the same key count as one and hence parallelism is bypassed. This address the same issue as apache/airflow#11875 but instead does not exclude file paths that are recently processed and that run at the limit (which is only used in tests) when Callbacks are sent by the Agent. This is by design as the execution of Callbacks is critical. This is done with a caveat to avoid duplicate processor -- i.e. if a processor exists, the file path is removed from the queue. This means that the processor with the file path to run callback will be still run when the file path is added again in the next loop Tests are added to check the same. closes apache/airflow#13047 closes apache/airflow#11875 GitOrigin-RevId: 32f59534cbdb8188e4c8f49d7dfbb4b915eaeb4d
When a dag file is executed via Dag File Processors and multiple callbacks are created either via zombies or executor events, the dag file is added to the _file_path_queue and the manager will launch a new process to process it, which it should not since the dag file is currently under processing. This will bypass the _parallelism eventually especially when it takes a long time to process some dag files and since self._processors is just a dict with file path as the key. So multiple processors with the same key count as one and hence parallelism is bypassed. This address the same issue as apache/airflow#11875 but instead does not exclude file paths that are recently processed and that run at the limit (which is only used in tests) when Callbacks are sent by the Agent. This is by design as the execution of Callbacks is critical. This is done with a caveat to avoid duplicate processor -- i.e. if a processor exists, the file path is removed from the queue. This means that the processor with the file path to run callback will be still run when the file path is added again in the next loop Tests are added to check the same. closes apache/airflow#13047 closes apache/airflow#11875 GitOrigin-RevId: 32f59534cbdb8188e4c8f49d7dfbb4b915eaeb4d
When a dag file is executed via Dag File Processors and multiple callbacks are created either via zombies or executor events, the dag file is added to the _file_path_queue and the manager will launch a new process to process it, which it should not since the dag file is currently under processing. This will bypass the _parallelism eventually especially when it takes a long time to process some dag files and since self._processors is just a dict with file path as the key. So multiple processors with the same key count as one and hence parallelism is bypassed. This address the same issue as apache/airflow#11875 but instead does not exclude file paths that are recently processed and that run at the limit (which is only used in tests) when Callbacks are sent by the Agent. This is by design as the execution of Callbacks is critical. This is done with a caveat to avoid duplicate processor -- i.e. if a processor exists, the file path is removed from the queue. This means that the processor with the file path to run callback will be still run when the file path is added again in the next loop Tests are added to check the same. closes apache/airflow#13047 closes apache/airflow#11875 (cherry picked from commit 32f59534cbdb8188e4c8f49d7dfbb4b915eaeb4d) GitOrigin-RevId: b446d145e1e5042e453ba91e34ae97573f320f09
When a dag file is executed via Dag File Processors and multiple callbacks are created either via zombies or executor events, the dag file is added to the _file_path_queue and the manager will launch a new process to process it, which it should not since the dag file is currently under processing. This will bypass the _parallelism eventually especially when it takes a long time to process some dag files and since self._processors is just a dict with file path as the key. So multiple processors with the same key count as one and hence parallelism is bypassed. This address the same issue as apache/airflow#11875 but instead does not exclude file paths that are recently processed and that run at the limit (which is only used in tests) when Callbacks are sent by the Agent. This is by design as the execution of Callbacks is critical. This is done with a caveat to avoid duplicate processor -- i.e. if a processor exists, the file path is removed from the queue. This means that the processor with the file path to run callback will be still run when the file path is added again in the next loop Tests are added to check the same. closes apache/airflow#13047 closes apache/airflow#11875 GitOrigin-RevId: 32f59534cbdb8188e4c8f49d7dfbb4b915eaeb4d
When a dag file is executed via Dag File Processors and multiple callbacks are created either via zombies or executor events, the dag file is added to the _file_path_queue and the manager will launch a new process to process it, which it should not since the dag file is currently under processing. This will bypass the _parallelism eventually especially when it takes a long time to process some dag files and since self._processors is just a dict with file path as the key. So multiple processors with the same key count as one and hence parallelism is bypassed. This address the same issue as apache/airflow#11875 but instead does not exclude file paths that are recently processed and that run at the limit (which is only used in tests) when Callbacks are sent by the Agent. This is by design as the execution of Callbacks is critical. This is done with a caveat to avoid duplicate processor -- i.e. if a processor exists, the file path is removed from the queue. This means that the processor with the file path to run callback will be still run when the file path is added again in the next loop Tests are added to check the same. closes apache/airflow#13047 closes apache/airflow#11875 GitOrigin-RevId: 32f59534cbdb8188e4c8f49d7dfbb4b915eaeb4d
When a dag file is executed via Dag File Processors and multiple callbacks are created either via zombies or executor events, the dag file is added to the _file_path_queue and the manager will launch a new process to process it, which it should not since the dag file is currently under processing. This will bypass the _parallelism eventually especially when it takes a long time to process some dag files and since self._processors is just a dict with file path as the key. So multiple processors with the same key count as one and hence parallelism is bypassed. This address the same issue as apache/airflow#11875 but instead does not exclude file paths that are recently processed and that run at the limit (which is only used in tests) when Callbacks are sent by the Agent. This is by design as the execution of Callbacks is critical. This is done with a caveat to avoid duplicate processor -- i.e. if a processor exists, the file path is removed from the queue. This means that the processor with the file path to run callback will be still run when the file path is added again in the next loop Tests are added to check the same. closes apache/airflow#13047 closes apache/airflow#11875 GitOrigin-RevId: 32f59534cbdb8188e4c8f49d7dfbb4b915eaeb4d
When a dag file is executed via Dag File Processors and multiple callbacks are created either via zombies or executor events, the dag file is added to the _file_path_queue and the manager will launch a new process to process it, which it should not since the dag file is currently under processing. This will bypass the _parallelism eventually especially when it takes a long time to process some dag files and since self._processors is just a dict with file path as the key. So multiple processors with the same key count as one and hence parallelism is bypassed. This address the same issue as apache/airflow#11875 but instead does not exclude file paths that are recently processed and that run at the limit (which is only used in tests) when Callbacks are sent by the Agent. This is by design as the execution of Callbacks is critical. This is done with a caveat to avoid duplicate processor -- i.e. if a processor exists, the file path is removed from the queue. This means that the processor with the file path to run callback will be still run when the file path is added again in the next loop Tests are added to check the same. closes apache/airflow#13047 closes apache/airflow#11875 GitOrigin-RevId: 32f59534cbdb8188e4c8f49d7dfbb4b915eaeb4d
When a dag file is executed via Dag File Processors and multiple callbacks are created either via zombies or executor events, the dag file is added to the _file_path_queue and the manager will launch a new process to process it, which it should not since the dag file is currently under processing. This will bypass the _parallelism eventually especially when it takes a long time to process some dag files and since self._processors is just a dict with file path as the key. So multiple processors with the same key count as one and hence parallelism is bypassed. This address the same issue as apache/airflow#11875 but instead does not exclude file paths that are recently processed and that run at the limit (which is only used in tests) when Callbacks are sent by the Agent. This is by design as the execution of Callbacks is critical. This is done with a caveat to avoid duplicate processor -- i.e. if a processor exists, the file path is removed from the queue. This means that the processor with the file path to run callback will be still run when the file path is added again in the next loop Tests are added to check the same. closes apache/airflow#13047 closes apache/airflow#11875 GitOrigin-RevId: 32f59534cbdb8188e4c8f49d7dfbb4b915eaeb4d
When a dag file is executed via Dag File Processors and multiple callbacks are created either via zombies or executor events, the dag file is added to the _file_path_queue and the manager will launch a new process to process it, which it should not since the dag file is currently under processing. This will bypass the _parallelism eventually especially when it takes a long time to process some dag files and since self._processors is just a dict with file path as the key. So multiple processors with the same key count as one and hence parallelism is bypassed. This address the same issue as apache/airflow#11875 but instead does not exclude file paths that are recently processed and that run at the limit (which is only used in tests) when Callbacks are sent by the Agent. This is by design as the execution of Callbacks is critical. This is done with a caveat to avoid duplicate processor -- i.e. if a processor exists, the file path is removed from the queue. This means that the processor with the file path to run callback will be still run when the file path is added again in the next loop Tests are added to check the same. closes apache/airflow#13047 closes apache/airflow#11875 GitOrigin-RevId: 32f59534cbdb8188e4c8f49d7dfbb4b915eaeb4d
When a dag file is executed via Dag File Processors and multiple callbacks are created either via zombies or executor events, the dag file is added to the _file_path_queue and the manager will launch a new process to process it, which it should not since the dag file is currently under processing. This will bypass the _parallelism eventually especially when it takes a long time to process some dag files and since self._processors is just a dict with file path as the key. So multiple processors with the same key count as one and hence parallelism is bypassed. This address the same issue as apache/airflow#11875 but instead does not exclude file paths that are recently processed and that run at the limit (which is only used in tests) when Callbacks are sent by the Agent. This is by design as the execution of Callbacks is critical. This is done with a caveat to avoid duplicate processor -- i.e. if a processor exists, the file path is removed from the queue. This means that the processor with the file path to run callback will be still run when the file path is added again in the next loop Tests are added to check the same. closes apache/airflow#13047 closes apache/airflow#11875 GitOrigin-RevId: 32f59534cbdb8188e4c8f49d7dfbb4b915eaeb4d
When a dag file is executed via Dag File Processors and multiple callbacks are created either via zombies or executor events, the dag file is added to the _file_path_queue and the manager will launch a new process to process it, which it should not since the dag file is currently under processing. This will bypass the _parallelism eventually especially when it takes a long time to process some dag files and since self._processors is just a dict with file path as the key. So multiple processors with the same key count as one and hence parallelism is bypassed. This address the same issue as apache/airflow#11875 but instead does not exclude file paths that are recently processed and that run at the limit (which is only used in tests) when Callbacks are sent by the Agent. This is by design as the execution of Callbacks is critical. This is done with a caveat to avoid duplicate processor -- i.e. if a processor exists, the file path is removed from the queue. This means that the processor with the file path to run callback will be still run when the file path is added again in the next loop Tests are added to check the same. closes apache/airflow#13047 closes apache/airflow#11875 GitOrigin-RevId: 32f59534cbdb8188e4c8f49d7dfbb4b915eaeb4d
When a dag file is executed via Dag File Processors and multiple callbacks are created either via zombies or executor events, the dag file is added to the _file_path_queue and the manager will launch a new process to process it, which it should not since the dag file is currently under processing. This will bypass the _parallelism eventually especially when it takes a long time to process some dag files and since self._processors is just a dict with file path as the key. So multiple processors with the same key count as one and hence parallelism is bypassed. This address the same issue as apache/airflow#11875 but instead does not exclude file paths that are recently processed and that run at the limit (which is only used in tests) when Callbacks are sent by the Agent. This is by design as the execution of Callbacks is critical. This is done with a caveat to avoid duplicate processor -- i.e. if a processor exists, the file path is removed from the queue. This means that the processor with the file path to run callback will be still run when the file path is added again in the next loop Tests are added to check the same. closes apache/airflow#13047 closes apache/airflow#11875 GitOrigin-RevId: 32f59534cbdb8188e4c8f49d7dfbb4b915eaeb4d
When a dag file is executed via Dag File Processors and multiple callbacks are created either via zombies or executor events, the dag file is added to the _file_path_queue and the manager will launch a new process to process it, which it should not since the dag file is currently under processing. This will bypass the _parallelism eventually especially when it takes a long time to process some dag files and since self._processors is just a dict with file path as the key. So multiple processors with the same key count as one and hence parallelism is bypassed. This address the same issue as apache/airflow#11875 but instead does not exclude file paths that are recently processed and that run at the limit (which is only used in tests) when Callbacks are sent by the Agent. This is by design as the execution of Callbacks is critical. This is done with a caveat to avoid duplicate processor -- i.e. if a processor exists, the file path is removed from the queue. This means that the processor with the file path to run callback will be still run when the file path is added again in the next loop Tests are added to check the same. closes apache/airflow#13047 closes apache/airflow#11875 GitOrigin-RevId: 32f59534cbdb8188e4c8f49d7dfbb4b915eaeb4d
When a dag file is executed via Dag File Processors and multiple callbacks are created either via zombies or executor events, the dag file is added to the _file_path_queue and the manager will launch a new process to process it, which it should not since the dag file is currently under processing. This will bypass the _parallelism eventually especially when it takes a long time to process some dag files and since self._processors is just a dict with file path as the key. So multiple processors with the same key count as one and hence parallelism is bypassed. This address the same issue as apache/airflow#11875 but instead does not exclude file paths that are recently processed and that run at the limit (which is only used in tests) when Callbacks are sent by the Agent. This is by design as the execution of Callbacks is critical. This is done with a caveat to avoid duplicate processor -- i.e. if a processor exists, the file path is removed from the queue. This means that the processor with the file path to run callback will be still run when the file path is added again in the next loop Tests are added to check the same. closes apache/airflow#13047 closes apache/airflow#11875 GitOrigin-RevId: 32f59534cbdb8188e4c8f49d7dfbb4b915eaeb4d
When a dag file is executed via Dag File Processors and multiple callbacks are created either via zombies or executor events, the dag file is added to the _file_path_queue and the manager will launch a new process to process it, which it should not since the dag file is currently under processing. This will bypass the _parallelism eventually especially when it takes a long time to process some dag files and since self._processors is just a dict with file path as the key. So multiple processors with the same key count as one and hence parallelism is bypassed. This address the same issue as apache/airflow#11875 but instead does not exclude file paths that are recently processed and that run at the limit (which is only used in tests) when Callbacks are sent by the Agent. This is by design as the execution of Callbacks is critical. This is done with a caveat to avoid duplicate processor -- i.e. if a processor exists, the file path is removed from the queue. This means that the processor with the file path to run callback will be still run when the file path is added again in the next loop Tests are added to check the same. closes apache/airflow#13047 closes apache/airflow#11875 GitOrigin-RevId: 32f59534cbdb8188e4c8f49d7dfbb4b915eaeb4d
When a dag file is executed via Dag File Processors and multiple callbacks are created either via zombies or executor events, the dag file is added to the _file_path_queue and the manager will launch a new process to process it, which it should not since the dag file is currently under processing. This will bypass the _parallelism eventually especially when it takes a long time to process some dag files and since self._processors is just a dict with file path as the key. So multiple processors with the same key count as one and hence parallelism is bypassed. This address the same issue as apache/airflow#11875 but instead does not exclude file paths that are recently processed and that run at the limit (which is only used in tests) when Callbacks are sent by the Agent. This is by design as the execution of Callbacks is critical. This is done with a caveat to avoid duplicate processor -- i.e. if a processor exists, the file path is removed from the queue. This means that the processor with the file path to run callback will be still run when the file path is added again in the next loop Tests are added to check the same. closes apache/airflow#13047 closes apache/airflow#11875 GitOrigin-RevId: 32f59534cbdb8188e4c8f49d7dfbb4b915eaeb4d
When a dag file is executed via Dag File Processors and multiple callbacks are created either via zombies or executor events, the dag file is added to the _file_path_queue and the manager will launch a new process to process it, which it should not since the dag file is currently under processing. This will bypass the _parallelism eventually especially when it takes a long time to process some dag files and since self._processors is just a dict with file path as the key. So multiple processors with the same key count as one and hence parallelism is bypassed. This address the same issue as apache/airflow#11875 but instead does not exclude file paths that are recently processed and that run at the limit (which is only used in tests) when Callbacks are sent by the Agent. This is by design as the execution of Callbacks is critical. This is done with a caveat to avoid duplicate processor -- i.e. if a processor exists, the file path is removed from the queue. This means that the processor with the file path to run callback will be still run when the file path is added again in the next loop Tests are added to check the same. closes apache/airflow#13047 closes apache/airflow#11875 GitOrigin-RevId: 32f59534cbdb8188e4c8f49d7dfbb4b915eaeb4d
Context: when a dag file is under processing and multiple callbacks are
created either via zombies or executor events, the dag file is added to
the _file_path_queue and the manager will launch a new process to
process it, which it should not since the dag file is currently under
processing. This will bypass the _parallelism eventually especially when
it takes long time to process some dag files. We have seen ~200 dag
processors on the scheduler even we set the _parallelism as 60. More dag
file processors make CPU spike and in turn it makes the dag file
processing even slower. In the end, the scheduler is taken down.
^ Add meaningful description above
Read the Pull Request Guidelines for more information.
In case of fundamental code change, Airflow Improvement Proposal (AIP) is needed.
In case of a new dependency, check compliance with the ASF 3rd Party License Policy.
In case of backwards incompatible changes please leave a note in UPDATING.md.