[Spark-37347][SQL]Spark Thrift Server (STS) driver fullFC becourse of timeoutExecutor not shutdown correctly#34617
Closed
lk246 wants to merge 689 commits intoapache:masterfrom
Closed
[Spark-37347][SQL]Spark Thrift Server (STS) driver fullFC becourse of timeoutExecutor not shutdown correctly#34617lk246 wants to merge 689 commits intoapache:masterfrom
lk246 wants to merge 689 commits intoapache:masterfrom
Conversation
…them This PR proposes to cache Maven, SBT and Scala in all jobs that use them. For simplicity, we use the same key `build-` and just cache all SBT, Maven and Scala. The cache is not very large. To speed up the build. No, dev-only. It will be tested in this PR's GA jobs. Closes apache#32011 from HyukjinKwon/SPARK-34915. Authored-by: HyukjinKwon <gurwls223@apache.org> Signed-off-by: Gengliang Wang <ltnwgl@gmail.com> (cherry picked from commit 48ef9bd) Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request? This PR fixes the GA failure related to R linter which happens on some PRs (e.g. apache#32023, apache#32025). The reason seems `Rscript -e "devtools::install_github('jimhester/lintrv2.0.0')"` fails to download `lintrv2.0.0`. I don't know why but I confirmed we can download `v2.0.1`. ### Why are the changes needed? To keep GA healthy. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? GA itself. Closes apache#32028 from sarutak/hotfix-r. Authored-by: Kousuke Saruta <sarutak@oss.nttdata.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com> (cherry picked from commit f99a831) Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
…used as logical operators from the document ### What changes were proposed in this pull request? This PR removes the description that `||` and `&&` can be used as logical operators from the migration guide. ### Why are the changes needed? At the `Compatibility with Apache Hive` section in the migration guide, it describes that `||` and `&&` can be used as logical operators. But, in fact, they cannot be used as described. AFAIK, Hive also doesn't support `&&` and `||` as logical operators. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? I confirmed that `&&` and `||` cannot be used as logical operators with both Hive's interactive shell and `spark-sql`. I also built the modified document and confirmed that the modified document doesn't break layout. Closes apache#32023 from sarutak/modify-hive-compatibility-doc. Authored-by: Kousuke Saruta <sarutak@oss.nttdata.com> Signed-off-by: Sean Owen <srowen@gmail.com> (cherry picked from commit 8724f2b) Signed-off-by: Sean Owen <srowen@gmail.com>
### What changes were proposed in this pull request? This is to fix the minor typo in unit test of BasicWriteTaskStatsTrackerSuite (https://github.com/apache/spark/blob/master/sql/core/src/test/scala/org/apache/spark/sql/execution/datasources/BasicWriteTaskStatsTrackerSuite.scala#L152 ), where it should be a new file name, e.g. `f-3-3`, because the unit test expects 3 files in statistics (https://github.com/apache/spark/blob/master/sql/core/src/test/scala/org/apache/spark/sql/execution/datasources/BasicWriteTaskStatsTrackerSuite.scala#L160 ). ### Why are the changes needed? Fix minor bug. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Changed unit test `"Three files, last one empty"` itself. Closes apache#32034 from c21/tracker-fix. Authored-by: Cheng Su <chengsu@fb.com> Signed-off-by: HyukjinKwon <gurwls223@apache.org> (cherry picked from commit 280a2f3) Signed-off-by: HyukjinKwon <gurwls223@apache.org>
…akages
This PR aims to add `ownerReference` to the executor ConfigMap to fix leakage.
SPARK-30985 maintains the executor config map explicitly inside Spark. However, this config map can be leaked when Spark drivers die accidentally or are killed by K8s. We need to add `ownerReference` to make K8s do the garbage collection these automatically.
The number of ConfigMap is one of the resource quota. So, the leaked configMaps currently cause Spark jobs submission failures.
No.
Pass the CIs and check manually.
K8s IT is tested manually.
```
KubernetesSuite:
- Run SparkPi with no resources
- Run SparkPi with a very long application name.
- Use SparkLauncher.NO_RESOURCE
- Run SparkPi with a master URL without a scheme.
- Run SparkPi with an argument.
- Run SparkPi with custom labels, annotations, and environment variables.
- All pods have the same service account by default
- Run extraJVMOptions check on driver
- Run SparkRemoteFileTest using a remote data file
- Verify logging configuration is picked from the provided SPARK_CONF_DIR/log4j.properties
- Run SparkPi with env and mount secrets.
- Run PySpark on simple pi.py example
- Run PySpark to test a pyfiles example
- Run PySpark with memory customization
- Run in client mode.
- Start pod creation from template
- PVs with local storage
- Launcher client dependencies
- SPARK-33615: Launcher client archives
- SPARK-33748: Launcher python client respecting PYSPARK_PYTHON
- SPARK-33748: Launcher python client respecting spark.pyspark.python and spark.pyspark.driver.python
- Launcher python client dependencies using a zip file
- Test basic decommissioning
- Test basic decommissioning with shuffle cleanup
- Test decommissioning with dynamic allocation & shuffle cleanups
- Test decommissioning timeouts
- Run SparkR on simple dataframe.R example
Run completed in 19 minutes, 2 seconds.
Total number of tests run: 27
Suites: completed 2, aborted 0
Tests: succeeded 27, failed 0, canceled 0, ignored 0, pending 0
All tests passed.
```
**BEFORE**
```
$ k get cm spark-exec-450b417895b3b2c7-conf-map -oyaml | grep ownerReferences
```
**AFTER**
```
$ k get cm spark-exec-bb37a27895b1c26c-conf-map -oyaml | grep ownerReferences
f:ownerReferences:
```
Closes apache#32042 from dongjoon-hyun/SPARK-34948.
Authored-by: Dongjoon Hyun <dhyun@apple.com>
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
(cherry picked from commit a42dc93)
Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
…rialize broadcasted map statuses ### What changes were proposed in this pull request? This patch catches `IOException`, which is possibly thrown due to unable to deserialize map statuses (e.g., broadcasted value is destroyed), when deserilizing map statuses. Once `IOException` is caught, `MetadataFetchFailedException` is thrown to let Spark handle it. ### Why are the changes needed? One customer encountered application error. From the log, it is caused by accessing non-existing broadcasted value. The broadcasted value is map statuses. E.g., ``` [info] Cause: java.io.IOException: org.apache.spark.SparkException: Failed to get broadcast_0_piece0 of broadcast_0 [info] at org.apache.spark.util.Utils$.tryOrIOException(Utils.scala:1410) [info] at org.apache.spark.broadcast.TorrentBroadcast.readBroadcastBlock(TorrentBroadcast.scala:226) [info] at org.apache.spark.broadcast.TorrentBroadcast.getValue(TorrentBroadcast.scala:103) [info] at org.apache.spark.broadcast.Broadcast.value(Broadcast.scala:70) [info] at org.apache.spark.MapOutputTracker$.$anonfun$deserializeMapStatuses$3(MapOutputTracker.scala:967) [info] at org.apache.spark.internal.Logging.logInfo(Logging.scala:57) [info] at org.apache.spark.internal.Logging.logInfo$(Logging.scala:56) [info] at org.apache.spark.MapOutputTracker$.logInfo(MapOutputTracker.scala:887) [info] at org.apache.spark.MapOutputTracker$.deserializeMapStatuses(MapOutputTracker.scala:967) ``` There is a race-condition. After map statuses are broadcasted and the executors obtain serialized broadcasted map statuses. If any fetch failure happens after, Spark scheduler invalidates cached map statuses and destroy broadcasted value of the map statuses. Then any executor trying to deserialize serialized broadcasted map statuses and access broadcasted value, `IOException` will be thrown. Currently we don't catch it in `MapOutputTrackerWorker` and above exception will fail the application. Normally we should throw a fetch failure exception for such case. Spark scheduler will handle this. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Unit test. Closes apache#32033 from viirya/fix-broadcast-master. Authored-by: Liang-Chi Hsieh <viirya@gmail.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com> (cherry picked from commit 571acc8) Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
…to recover the Sphinx build in GitHub Actions This PR proposes to set the system encoding as UTF-8. For some reasons, it looks like GitHub Actions machines changed theirs to ASCII by default. This leads to default encoding/decoding to use ASCII in Python, e.g.) `"a".encode()`, and looks like Sphinx depends on that. To recover GItHub Actions build. No, dev-only. Tested in apache#32046 Closes apache#32047 from HyukjinKwon/SPARK-34951. Authored-by: HyukjinKwon <gurwls223@apache.org> Signed-off-by: HyukjinKwon <gurwls223@apache.org> (cherry picked from commit 82ad2f9) Signed-off-by: HyukjinKwon <gurwls223@apache.org>
…shutting down ### What changes were proposed in this pull request? This PR prevents reregistering BlockManager when a Executor is shutting down. It is achieved by checking `executorShutdown` before calling `env.blockManager.reregister()`. ### Why are the changes needed? This change is required since Spark reports executors as active, even they are removed. I was testing Dynamic Allocation on K8s with about 300 executors. While doing so, when the executors were torn down due to `spark.dynamicAllocation.executorIdleTimeout`, I noticed all the executor pods being removed from K8s, however, under the "Executors" tab in SparkUI, I could see some executors listed as alive. [spark.sparkContext.statusTracker.getExecutorInfos.length](https://github.com/apache/spark/blob/65da9287bc5112564836a555cd2967fc6b05856f/core/src/main/scala/org/apache/spark/SparkStatusTracker.scala#L105) also returned a value greater than 1. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Added a new test. ## Logs Following are the logs of the executor(Id:303) which re-registers `BlockManager` ``` 21/04/02 21:33:28 INFO CoarseGrainedExecutorBackend: Got assigned task 1076 21/04/02 21:33:28 INFO Executor: Running task 4.0 in stage 3.0 (TID 1076) 21/04/02 21:33:28 INFO MapOutputTrackerWorker: Updating epoch to 302 and clearing cache 21/04/02 21:33:28 INFO TorrentBroadcast: Started reading broadcast variable 3 21/04/02 21:33:28 INFO TransportClientFactory: Successfully created connection to /100.100.195.227:33703 after 76 ms (62 ms spent in bootstraps) 21/04/02 21:33:28 INFO MemoryStore: Block broadcast_3_piece0 stored as bytes in memory (estimated size 2.4 KB, free 168.0 MB) 21/04/02 21:33:28 INFO TorrentBroadcast: Reading broadcast variable 3 took 168 ms 21/04/02 21:33:28 INFO MemoryStore: Block broadcast_3 stored as values in memory (estimated size 3.9 KB, free 168.0 MB) 21/04/02 21:33:29 INFO MapOutputTrackerWorker: Don't have map outputs for shuffle 1, fetching them 21/04/02 21:33:29 INFO MapOutputTrackerWorker: Doing the fetch; tracker endpoint = NettyRpcEndpointRef(spark://MapOutputTrackerda-lite-test-4-7a57e478947d206d-driver-svc.dex-app-n5ttnbmg.svc:7078) 21/04/02 21:33:29 INFO MapOutputTrackerWorker: Got the output locations 21/04/02 21:33:29 INFO ShuffleBlockFetcherIterator: Getting 2 non-empty blocks including 1 local blocks and 1 remote blocks 21/04/02 21:33:30 INFO TransportClientFactory: Successfully created connection to /100.100.80.103:40971 after 660 ms (528 ms spent in bootstraps) 21/04/02 21:33:30 INFO ShuffleBlockFetcherIterator: Started 1 remote fetches in 1042 ms 21/04/02 21:33:31 INFO Executor: Finished task 4.0 in stage 3.0 (TID 1076). 1276 bytes result sent to driver . . . 21/04/02 21:34:16 INFO CoarseGrainedExecutorBackend: Driver commanded a shutdown 21/04/02 21:34:16 INFO Executor: Told to re-register on heartbeat 21/04/02 21:34:16 INFO BlockManager: BlockManager BlockManagerId(303, 100.100.122.34, 41265, None) re-registering with master 21/04/02 21:34:16 INFO BlockManagerMaster: Registering BlockManager BlockManagerId(303, 100.100.122.34, 41265, None) 21/04/02 21:34:16 INFO BlockManagerMaster: Registered BlockManager BlockManagerId(303, 100.100.122.34, 41265, None) 21/04/02 21:34:16 INFO BlockManager: Reporting 0 blocks to the master. 21/04/02 21:34:16 INFO MemoryStore: MemoryStore cleared 21/04/02 21:34:16 INFO BlockManager: BlockManager stopped 21/04/02 21:34:16 INFO FileDataSink: Closing sink with output file = /tmp/safari-events/.des_analysis/safari-events/hdp_spark_monitoring_random-container-037caf27-6c77-433f-820f-03cd9c7d9b6e-spark-8a492407d60b401bbf4309a14ea02ca2_events.tsv 21/04/02 21:34:16 INFO HonestProfilerBasedThreadSnapshotProvider: Stopping agent 21/04/02 21:34:16 INFO HonestProfilerHandler: Stopping honest profiler agent 21/04/02 21:34:17 INFO ShutdownHookManager: Shutdown hook called 21/04/02 21:34:17 INFO ShutdownHookManager: Deleting directory /var/data/spark-d886588c-2a7e-491d-bbcb-4f58b3e31001/spark-4aa337a0-60c0-45da-9562-8c50eaff3cea ``` Closes apache#32043 from sumeetgajjar/SPARK-34949. Authored-by: Sumeet Gajjar <sumeetgajjar93@gmail.com> Signed-off-by: Mridul Muralidharan <mridul<at>gmail.com> (cherry picked from commit a9ca197) Signed-off-by: Mridul Muralidharan <mridulatgmail.com>
Changes the metadata propagation framework. Previously, most `LogicalPlan`'s propagated their `children`'s `metadataOutput`. This did not make sense in cases where the `LogicalPlan` did not even propagate their `children`'s `output`. I set the metadata output for plans that do not propagate their `children`'s `output` to be `Nil`. Notably, `Project` and `View` no longer have metadata output. Previously, `SELECT m from (SELECT a from tb)` would output `m` if it were metadata. This did not make sense. Yes. Now, `SELECT m from (SELECT a from tb)` will encounter an `AnalysisException`. Added unit tests. I did not cover all cases, as they are fairly extensive. However, the new tests cover major cases (and an existing test already covers Join). Closes apache#32017 from karenfeng/spark-34923. Authored-by: Karen Feng <karen.feng@databricks.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com> (cherry picked from commit 3b634f6) Signed-off-by: Wenchen Fan <wenchen@databricks.com>
…t memory ### What changes were proposed in this pull request? This PR removes `.sbtopts` (added in apache#29286) that duplicately sets the default memory. The default memories are set: https://github.com/apache/spark/blob/3b634f66c3e4a942178a1e322ae65ce82779625d/build/sbt-launch-lib.bash#L119-L124 ### Why are the changes needed? This file disables the memory option from the `build/sbt` script: ```bash ./build/sbt -mem 6144 ``` ``` .../jdk-11.0.3.jdk/Contents/Home as default JAVA_HOME. Note, this will be overridden by -java-home if it is set. Error occurred during initialization of VM Initial heap size set to a larger value than the maximum heap size ``` because it adds these memory options at the last: ```bash /.../bin/java -Xms6144m -Xmx6144m -XX:ReservedCodeCacheSize=256m -Xmx4G -Xss4m -jar build/sbt-launch-1.5.0.jar ``` and Java respects the rightmost memory configurations. ### Does this PR introduce _any_ user-facing change? No, dev-only. ### How was this patch tested? Manually ran SBT. It will be tested in the CIs in this Pr. Closes apache#32062 from HyukjinKwon/SPARK-34965. Authored-by: HyukjinKwon <gurwls223@apache.org> Signed-off-by: Dongjoon Hyun <dhyun@apple.com> (cherry picked from commit 2eda1c6) Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
…put of explain() ### What changes were proposed in this pull request? The `explain()` method prints the arguments of tree nodes in logical/physical plans. The arguments could contain a map-type option that contains sensitive data. We should map-type options in the output of `explain()`. Otherwise, we will see sensitive data in explain output or Spark UI. 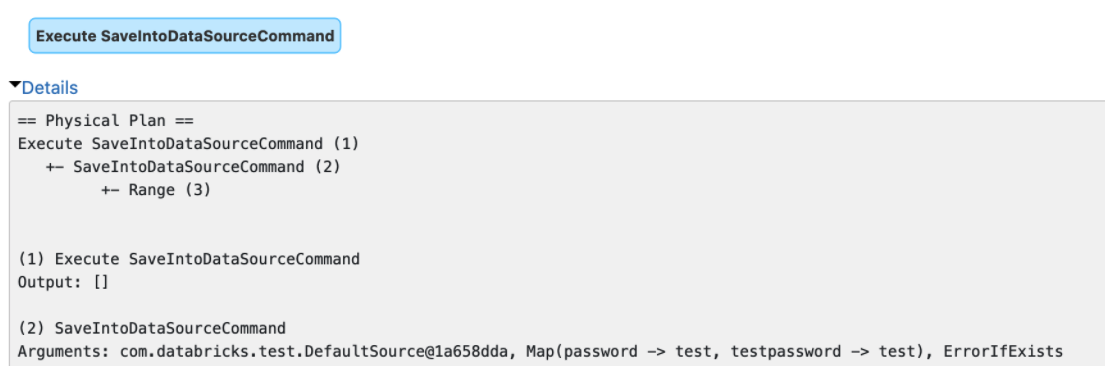 ### Why are the changes needed? Data security. ### Does this PR introduce _any_ user-facing change? Yes, redact the map-type options in the output of `explain()` ### How was this patch tested? Unit tests Closes apache#32079 from gengliangwang/PR_TOOL_PICK_PR_32066_BRANCH-3.1. Authored-by: Gengliang Wang <ltnwgl@gmail.com> Signed-off-by: Gengliang Wang <ltnwgl@gmail.com>
{kind=link}
…e CBO ### What changes were proposed in this pull request? Changed the cost comparison function of the CBO to use the ratios of row counts and sizes in bytes. ### Why are the changes needed? In apache#30965 we changed to CBO cost comparison function so it would be "symetric": `A.betterThan(B)` now implies, that `!B.betterThan(A)`. With that we caused a performance regressions in some queries - TPCDS q19 for example. The original cost comparison function used the ratios `relativeRows = A.rowCount / B.rowCount` and `relativeSize = A.size / B.size`. The changed function compared "absolute" cost values `costA = w*A.rowCount + (1-w)*A.size` and `costB = w*B.rowCount + (1-w)*B.size`. Given the input from wzhfy we decided to go back to the relative values, because otherwise one (size) may overwhelm the other (rowCount). But this time we avoid adding up the ratios. Originally `A.betterThan(B) => w*relativeRows + (1-w)*relativeSize < 1` was used. Besides being "non-symteric", this also can exhibit one overwhelming other. For `w=0.5` If `A` size (bytes) is at least 2x larger than `B`, then no matter how many times more rows does the `B` plan have, `B` will allways be considered to be better - `0.5*2 + 0.5*0.00000000000001 > 1`. When working with ratios, then it would be better to multiply them. The proposed cost comparison function is: `A.betterThan(B) => relativeRows^w * relativeSize^(1-w) < 1`. ### Does this PR introduce _any_ user-facing change? Comparison of the changed TPCDS v1.4 query execution times at sf=10: | absolute | multiplicative | | additive | -- | -- | -- | -- | -- | -- q12 | 145 | 137 | -5.52% | 141 | -2.76% q13 | 264 | 271 | 2.65% | 271 | 2.65% q17 | 4521 | 4243 | -6.15% | 4348 | -3.83% q18 | 758 | 466 | -38.52% | 480 | -36.68% q19 | 38503 | 2167 | -94.37% | 2176 | -94.35% q20 | 119 | 120 | 0.84% | 126 | 5.88% q24a | 16429 | 16838 | 2.49% | 17103 | 4.10% q24b | 16592 | 16999 | 2.45% | 17268 | 4.07% q25 | 3558 | 3556 | -0.06% | 3675 | 3.29% q33 | 362 | 361 | -0.28% | 380 | 4.97% q52 | 1020 | 1032 | 1.18% | 1052 | 3.14% q55 | 927 | 938 | 1.19% | 961 | 3.67% q72 | 24169 | 13377 | -44.65% | 24306 | 0.57% q81 | 1285 | 1185 | -7.78% | 1168 | -9.11% q91 | 324 | 336 | 3.70% | 337 | 4.01% q98 | 126 | 129 | 2.38% | 131 | 3.97% All times are in ms, the change is compared to the situation in the master branch (absolute). The proposed cost function (multiplicative) significantlly improves the performance on q18, q19 and q72. The original cost function (additive) has similar improvements at q18 and q19. All other chagnes are within the error bars and I would ignore them - perhaps q81 has also improved. ### How was this patch tested? PlanStabilitySuite Closes apache#32075 from tanelk/SPARK-34922_cbo_better_cost_function_3.1. Lead-authored-by: Tanel Kiis <tanel.kiis@gmail.com> Co-authored-by: tanel.kiis@gmail.com <tanel.kiis@gmail.com> Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
### What changes were proposed in this pull request? This PR backports apache#32091. This PR upgrades the version of Jetty to 9.4.39. ### Why are the changes needed? CVE-2021-28165 affects the version of Jetty that Spark uses and it seems to be a little bit serious. https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2021-28165 ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Existing tests. Closes apache#32095 from sarutak/SPARK-34988-branch-3.1. Authored-by: Kousuke Saruta <sarutak@oss.nttdata.com> Signed-off-by: Sean Owen <srowen@gmail.com>
… finished ### What changes were proposed in this pull request? Close SparkContext after the Main method has finished, to allow SparkApplication on K8S to complete ### Why are the changes needed? if I don't call the method sparkContext.stop() explicitly, then a Spark driver process doesn't terminate even after its Main method has been completed. This behaviour is different from spark on yarn, where the manual sparkContext stopping is not required. It looks like, the problem is in using non-daemon threads, which prevent the driver jvm process from terminating. So I have inserted code that closes sparkContext automatically. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Manually on the production AWS EKS environment in my company. Closes apache#32081 from kotlovs/close-spark-context-on-exit. Authored-by: skotlov <skotlov@joom.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com> (cherry picked from commit ab97db7) Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
…thod has finished" This reverts commit c625eb4.
…available behind front-end reverseProxy` in MasterSuite ### What changes were proposed in this pull request? Line 425 in `MasterSuite` is considered as unused expression by Intellij IDE, https://github.com/apache/spark/blob/bfba7fadd2e65c853971fb2983bdea1c52d1ed7f/core/src/test/scala/org/apache/spark/deploy/master/MasterSuite.scala#L421-L426 If we merge lines 424 and 425 into one as: ``` System.getProperty("spark.ui.proxyBase") should startWith (s"$reverseProxyUrl/proxy/worker-") ``` this assertion will fail: ``` - master/worker web ui available behind front-end reverseProxy *** FAILED *** The code passed to eventually never returned normally. Attempted 45 times over 5.091914027 seconds. Last failure message: "http://proxyhost:8080/path/to/spark" did not start with substring "http://proxyhost:8080/path/to/spark/proxy/worker-". (MasterSuite.scala:405) ``` `System.getProperty("spark.ui.proxyBase")` should be `reverseProxyUrl` because `Master#onStart` and `Worker#handleRegisterResponse` have not changed it. So the main purpose of this pr is to fix the condition of this assertion. ### Why are the changes needed? Bug fix. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? - Pass the Jenkins or GitHub Action - Manual test: 1. merge lines 424 and 425 in `MasterSuite` into one to eliminate the unused expression: ``` System.getProperty("spark.ui.proxyBase") should startWith (s"$reverseProxyUrl/proxy/worker-") ``` 2. execute `mvn clean test -pl core -Dtest=none -DwildcardSuites=org.apache.spark.deploy.master.MasterSuite` **Before** ``` - master/worker web ui available behind front-end reverseProxy *** FAILED *** The code passed to eventually never returned normally. Attempted 45 times over 5.091914027 seconds. Last failure message: "http://proxyhost:8080/path/to/spark" did not start with substring "http://proxyhost:8080/path/to/spark/proxy/worker-". (MasterSuite.scala:405) Run completed in 1 minute, 14 seconds. Total number of tests run: 32 Suites: completed 2, aborted 0 Tests: succeeded 31, failed 1, canceled 0, ignored 0, pending 0 *** 1 TEST FAILED *** ``` **After** ``` Run completed in 1 minute, 11 seconds. Total number of tests run: 32 Suites: completed 2, aborted 0 Tests: succeeded 32, failed 0, canceled 0, ignored 0, pending 0 All tests passed. ``` Closes apache#32105 from LuciferYang/SPARK-35004. Authored-by: yangjie01 <yangjie01@baidu.com> Signed-off-by: Gengliang Wang <ltnwgl@gmail.com> (cherry picked from commit c067588) Signed-off-by: Gengliang Wang <ltnwgl@gmail.com>
…nsitive struct field from array of struct
### What changes were proposed in this pull request?
This patch proposes a fix of nested column pruning for extracting case-insensitive struct field from array of struct.
### Why are the changes needed?
Under case-insensitive mode, nested column pruning rule cannot correctly push down extractor of a struct field of an array of struct, e.g.,
```scala
val query = spark.table("contacts").select("friends.First", "friends.MiDDle")
```
Error stack:
```
[info] java.lang.IllegalArgumentException: Field "First" does not exist.
[info] Available fields:
[info] at org.apache.spark.sql.types.StructType$$anonfun$apply$1.apply(StructType.scala:274)
[info] at org.apache.spark.sql.types.StructType$$anonfun$apply$1.apply(StructType.scala:274)
[info] at scala.collection.MapLike$class.getOrElse(MapLike.scala:128)
[info] at scala.collection.AbstractMap.getOrElse(Map.scala:59)
[info] at org.apache.spark.sql.types.StructType.apply(StructType.scala:273)
[info] at org.apache.spark.sql.execution.ProjectionOverSchema$$anonfun$getProjection$3.apply(ProjectionOverSchema.scala:44)
[info] at org.apache.spark.sql.execution.ProjectionOverSchema$$anonfun$getProjection$3.apply(ProjectionOverSchema.scala:41)
```
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Unit test
Closes apache#32059 from viirya/fix-array-nested-pruning.
Authored-by: Liang-Chi Hsieh <viirya@gmail.com>
Signed-off-by: Liang-Chi Hsieh <viirya@gmail.com>
(cherry picked from commit 364d1ea)
Signed-off-by: Liang-Chi Hsieh <viirya@gmail.com>
### What changes were proposed in this pull request? This patch fixes wrong Python code sample for doc. ### Why are the changes needed? Sample code is wrong. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Doc only. Closes apache#32119 from Hisssy/ss-doc-typo-1. Authored-by: hissy <aozora@live.cn> Signed-off-by: Max Gekk <max.gekk@gmail.com> (cherry picked from commit 214a46a) Signed-off-by: Max Gekk <max.gekk@gmail.com>
### What changes were proposed in this pull request? This PR adds the typehint of pyspark.__version__, which was mentioned in [SPARK-34630](https://issues.apache.org/jira/browse/SPARK-34630). ### Why are the changes needed? There were some short discussion happened in apache#31823 (comment) . After further deep investigation on [1][2], we can see the `pyspark.__version__` is added by [setup.py](https://github.com/apache/spark/blob/c06758834e6192b1888b4a885c612a151588b390/python/setup.py#L201), it makes `__version__` embedded into pyspark module, that means the `__init__.pyi` is the right place to add the typehint for `__version__`. So, this patch adds the type hint `__version__` in pyspark/__init__.pyi. [1] [PEP-396 Module Version Numbers](https://www.python.org/dev/peps/pep-0396/) [2] https://packaging.python.org/guides/single-sourcing-package-version/ ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? 1. Disable the ignore_error on https://github.com/apache/spark/blob/ee7bf7d9628384548d09ac20e30992dd705c20f4/python/mypy.ini#L132 2. Run mypy: - Before fix ```shell (venv) ➜ spark git:(SPARK-34629) ✗ mypy --config-file python/mypy.ini python/pyspark | grep version python/pyspark/pandas/spark/accessors.py:884: error: Module has no attribute "__version__" ``` - After fix ```shell (venv) ➜ spark git:(SPARK-34629) ✗ mypy --config-file python/mypy.ini python/pyspark | grep version ``` no output Closes apache#32110 from Yikun/SPARK-34629. Authored-by: Yikun Jiang <yikunkero@gmail.com> Signed-off-by: HyukjinKwon <gurwls223@apache.org> (cherry picked from commit 4c1ccda) Signed-off-by: HyukjinKwon <gurwls223@apache.org>
…spect partition value is null ### What changes were proposed in this pull request? When we insert data into a partition table partition with empty DataFrame. We will call `PartitioningUtils.getPathFragment()` then to update this partition's metadata too. When we insert to a partition when partition value is `null`, it will throw exception like ``` [info] java.lang.NullPointerException: [info] at scala.collection.immutable.StringOps$.length$extension(StringOps.scala:51) [info] at scala.collection.immutable.StringOps.length(StringOps.scala:51) [info] at scala.collection.IndexedSeqOptimized.foreach(IndexedSeqOptimized.scala:35) [info] at scala.collection.IndexedSeqOptimized.foreach$(IndexedSeqOptimized.scala:33) [info] at scala.collection.immutable.StringOps.foreach(StringOps.scala:33) [info] at org.apache.spark.sql.catalyst.catalog.ExternalCatalogUtils$.escapePathName(ExternalCatalogUtils.scala:69) [info] at org.apache.spark.sql.catalyst.catalog.ExternalCatalogUtils$.getPartitionValueString(ExternalCatalogUtils.scala:126) [info] at org.apache.spark.sql.execution.datasources.PartitioningUtils$.$anonfun$getPathFragment$1(PartitioningUtils.scala:354) [info] at scala.collection.TraversableLike.$anonfun$map$1(TraversableLike.scala:238) [info] at scala.collection.Iterator.foreach(Iterator.scala:941) [info] at scala.collection.Iterator.foreach$(Iterator.scala:941) [info] at scala.collection.AbstractIterator.foreach(Iterator.scala:1429) [info] at scala.collection.IterableLike.foreach(IterableLike.scala:74) [info] at scala.collection.IterableLike.foreach$(IterableLike.scala:73) ``` `PartitioningUtils.getPathFragment()` should support `null` value too ### Why are the changes needed? Fix bug ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Added UT Closes apache#32127 from AngersZhuuuu/SPARK-34926-3.1. Authored-by: Angerszhuuuu <angers.zhu@gmail.com> Signed-off-by: Max Gekk <max.gekk@gmail.com>
### What changes were proposed in this pull request? Fix type hints mismatches in pyspark.sql.* ### Why are the changes needed? There were some mismatches in pyspark.sql.* ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? dev/lint-python passed. Closes apache#32122 from Yikun/SPARK-35019. Authored-by: Yikun Jiang <yikunkero@gmail.com> Signed-off-by: HyukjinKwon <gurwls223@apache.org> (cherry picked from commit b43f7e6) Signed-off-by: HyukjinKwon <gurwls223@apache.org>
This pr moves the added test from `SQLQuerySuite` to `ParquetQuerySuite`. 1. It can be tested by `ParquetV1QuerySuite` and `ParquetV2QuerySuite`. 2. Reduce the testing time of `SQLQuerySuite`(SQLQuerySuite ~ 3 min 17 sec, ParquetV1QuerySuite ~ 27 sec). No. Unit test. Closes apache#32090 from wangyum/SPARK-34212. Authored-by: Yuming Wang <yumwang@ebay.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com>
…able expressions ### What changes were proposed in this pull request? Fix PhysicalAggregation to not transform a foldable expression. ### Why are the changes needed? It can potentially break certain queries like the added unit test shows. ### Does this PR introduce _any_ user-facing change? Yes, it fixes undesirable errors caused by a returned TypeCheckFailure from places like RegExpReplace.checkInputDataTypes. Closes apache#32113 from sigmod/foldable. Authored-by: Yingyi Bu <yingyi.bu@databricks.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com> (cherry picked from commit 9cd25b4) Signed-off-by: Wenchen Fan <wenchen@databricks.com>
…univocity ### What changes were proposed in this pull request? This PR makes the input buffer configurable (as an internal option). This is mainly to work around uniVocity/univocity-parsers#449. ### Why are the changes needed? To work around uniVocity/univocity-parsers#449. ### Does this PR introduce _any_ user-facing change? No, it's only internal option. ### How was this patch tested? Manually tested by modifying the unittest added in apache#31858 as below: ```diff diff --git a/sql/core/src/test/scala/org/apache/spark/sql/execution/datasources/csv/CSVSuite.scala b/sql/core/src/test/scala/org/apache/spark/sql/execution/datasources/csv/CSVSuite.scala index fd25a79..b58f0bd3661 100644 --- a/sql/core/src/test/scala/org/apache/spark/sql/execution/datasources/csv/CSVSuite.scala +++ b/sql/core/src/test/scala/org/apache/spark/sql/execution/datasources/csv/CSVSuite.scala -2460,6 +2460,7 abstract class CSVSuite Seq(line).toDF.write.text(path.getAbsolutePath) assert(spark.read.format("csv") .option("delimiter", "|") + .option("inputBufferSize", "128") .option("ignoreTrailingWhiteSpace", "true").load(path.getAbsolutePath).count() == 1) } } ``` Closes apache#32145 from HyukjinKwon/SPARK-35045. Lead-authored-by: Hyukjin Kwon <gurwls223@apache.org> Co-authored-by: HyukjinKwon <gurwls223@apache.org> Signed-off-by: Max Gekk <max.gekk@gmail.com> (cherry picked from commit 1f56215) Signed-off-by: Max Gekk <max.gekk@gmail.com>
…son lineSep param ### What changes were proposed in this pull request? Add a new line to the `lineSep` parameter so that the doc renders correctly. ### Why are the changes needed? > <img width="608" alt="image" src="https://user-images.githubusercontent.com/8269566/114631408-5c608900-9c71-11eb-8ded-ae1e21ae48b2.png"> The first line of the description is part of the signature and is **bolded**. ### Does this PR introduce _any_ user-facing change? Yes, it changes how the docs for `pyspark.sql.DataFrameWriter.json` are rendered. ### How was this patch tested? I didn't test it; I don't have the doc rendering tool chain on my machine, but the change is obvious. Closes apache#32153 from AlexMooney/patch-1. Authored-by: Alex Mooney <alexmooney@fastmail.com> Signed-off-by: HyukjinKwon <gurwls223@apache.org> (cherry picked from commit faa928c) Signed-off-by: HyukjinKwon <gurwls223@apache.org>
{kind=link}
…iniYARNCluster This PR fixes two tests below: https://github.com/apache/spark/runs/2320161984 ``` [info] YarnShuffleIntegrationSuite: [info] org.apache.spark.deploy.yarn.YarnShuffleIntegrationSuite *** ABORTED *** (228 milliseconds) [info] org.apache.hadoop.yarn.exceptions.YarnRuntimeException: org.apache.hadoop.yarn.webapp.WebAppException: Error starting http server [info] at org.apache.hadoop.yarn.server.MiniYARNCluster.startResourceManager(MiniYARNCluster.java:373) [info] at org.apache.hadoop.yarn.server.MiniYARNCluster.access$300(MiniYARNCluster.java:128) [info] at org.apache.hadoop.yarn.server.MiniYARNCluster$ResourceManagerWrapper.serviceStart(MiniYARNCluster.java:503) [info] at org.apache.hadoop.service.AbstractService.start(AbstractService.java:194) [info] at org.apache.hadoop.service.CompositeService.serviceStart(CompositeService.java:121) [info] at org.apache.hadoop.yarn.server.MiniYARNCluster.serviceStart(MiniYARNCluster.java:322) [info] at org.apache.hadoop.service.AbstractService.start(AbstractService.java:194) [info] at org.apache.spark.deploy.yarn.BaseYarnClusterSuite.beforeAll(BaseYarnClusterSuite.scala:95) ... [info] Cause: java.net.BindException: Port in use: fv-az186-831:0 [info] at org.apache.hadoop.http.HttpServer2.constructBindException(HttpServer2.java:1231) [info] at org.apache.hadoop.http.HttpServer2.bindForSinglePort(HttpServer2.java:1253) [info] at org.apache.hadoop.http.HttpServer2.openListeners(HttpServer2.java:1316) [info] at org.apache.hadoop.http.HttpServer2.start(HttpServer2.java:1167) [info] at org.apache.hadoop.yarn.webapp.WebApps$Builder.start(WebApps.java:449) [info] at org.apache.hadoop.yarn.server.resourcemanager.ResourceManager.startWepApp(ResourceManager.java:1247) [info] at org.apache.hadoop.yarn.server.resourcemanager.ResourceManager.serviceStart(ResourceManager.java:1356) [info] at org.apache.hadoop.service.AbstractService.start(AbstractService.java:194) [info] at org.apache.hadoop.yarn.server.MiniYARNCluster.startResourceManager(MiniYARNCluster.java:365) [info] at org.apache.hadoop.yarn.server.MiniYARNCluster.access$300(MiniYARNCluster.java:128) [info] at org.apache.hadoop.yarn.server.MiniYARNCluster$ResourceManagerWrapper.serviceStart(MiniYARNCluster.java:503) [info] at org.apache.hadoop.service.AbstractService.start(AbstractService.java:194) [info] at org.apache.hadoop.service.CompositeService.serviceStart(CompositeService.java:121) [info] at org.apache.hadoop.yarn.server.MiniYARNCluster.serviceStart(MiniYARNCluster.java:322) [info] at org.apache.hadoop.service.AbstractService.start(AbstractService.java:194) [info] at org.apache.spark.deploy.yarn.BaseYarnClusterSuite.beforeAll(BaseYarnClusterSuite.scala:95) [info] at org.scalatest.BeforeAndAfterAll.liftedTree1$1(BeforeAndAfterAll.scala:212) [info] at org.scalatest.BeforeAndAfterAll.run(BeforeAndAfterAll.scala:210) [info] at org.scalatest.BeforeAndAfterAll.run$(BeforeAndAfterAll.scala:208) [info] at org.apache.spark.SparkFunSuite.run(SparkFunSuite.scala:61) ... ``` https://github.com/apache/spark/runs/2323342094 ``` [info] Test org.apache.spark.network.shuffle.ExternalShuffleSecuritySuite.testBadSecret started [error] Test org.apache.spark.network.shuffle.ExternalShuffleSecuritySuite.testBadSecret failed: java.lang.AssertionError: Connecting to /10.1.0.161:39895 timed out (120000 ms), took 120.081 sec [error] at org.apache.spark.network.shuffle.ExternalShuffleSecuritySuite.testBadSecret(ExternalShuffleSecuritySuite.java:85) [error] ... [info] Test org.apache.spark.network.shuffle.ExternalShuffleSecuritySuite.testBadAppId started [error] Test org.apache.spark.network.shuffle.ExternalShuffleSecuritySuite.testBadAppId failed: java.lang.AssertionError: Connecting to /10.1.0.198:44633 timed out (120000 ms), took 120.08 sec [error] at org.apache.spark.network.shuffle.ExternalShuffleSecuritySuite.testBadAppId(ExternalShuffleSecuritySuite.java:76) [error] ... [info] Test org.apache.spark.network.shuffle.ExternalShuffleSecuritySuite.testValid started [error] Test org.apache.spark.network.shuffle.ExternalShuffleSecuritySuite.testValid failed: java.io.IOException: Connecting to /10.1.0.119:43575 timed out (120000 ms), took 120.089 sec [error] at org.apache.spark.network.client.TransportClientFactory.createClient(TransportClientFactory.java:285) [error] at org.apache.spark.network.client.TransportClientFactory.createClient(TransportClientFactory.java:218) [error] at org.apache.spark.network.client.TransportClientFactory.createClient(TransportClientFactory.java:230) [error] at org.apache.spark.network.shuffle.ExternalBlockStoreClient.registerWithShuffleServer(ExternalBlockStoreClient.java:211) [error] at org.apache.spark.network.shuffle.ExternalShuffleSecuritySuite.validate(ExternalShuffleSecuritySuite.java:108) [error] at org.apache.spark.network.shuffle.ExternalShuffleSecuritySuite.testValid(ExternalShuffleSecuritySuite.java:68) [error] ... [info] Test org.apache.spark.network.shuffle.ExternalShuffleSecuritySuite.testEncryption started [error] Test org.apache.spark.network.shuffle.ExternalShuffleSecuritySuite.testEncryption failed: java.io.IOException: Connecting to /10.1.0.248:35271 timed out (120000 ms), took 120.014 sec [error] at org.apache.spark.network.client.TransportClientFactory.createClient(TransportClientFactory.java:285) [error] at org.apache.spark.network.client.TransportClientFactory.createClient(TransportClientFactory.java:218) [error] at org.apache.spark.network.client.TransportClientFactory.createClient(TransportClientFactory.java:230) [error] at org.apache.spark.network.shuffle.ExternalBlockStoreClient.registerWithShuffleServer(ExternalBlockStoreClient.java:211) [error] at org.apache.spark.network.shuffle.ExternalShuffleSecuritySuite.validate(ExternalShuffleSecuritySuite.java:108) [error] at org.apache.spark.network.shuffle.ExternalShuffleSecuritySuite.testEncryption(ExternalShu ``` For Yarn cluster suites, its difficult to fix. This PR makes it skipped if it fails to bind. For shuffle related suites, it uses local host To make the tests stable No, dev-only. Its tested in GitHub Actions: https://github.com/HyukjinKwon/spark/runs/2340210765 Closes apache#32126 from HyukjinKwon/SPARK-35002-followup. Authored-by: HyukjinKwon <gurwls223@apache.org> Signed-off-by: Yuming Wang <yumwang@ebay.com> (cherry picked from commit a153efa) Signed-off-by: HyukjinKwon <gurwls223@apache.org>
… Github Action This PR tries to fix the `java.net.BindException` when testing with Github Action: ``` [info] org.apache.spark.sql.kafka010.producer.InternalKafkaProducerPoolSuite *** ABORTED *** (282 milliseconds) [info] java.net.BindException: Cannot assign requested address: Service 'sparkDriver' failed after 100 retries (on a random free port)! Consider explicitly setting the appropriate binding address for the service 'sparkDriver' (for example spark.driver.bindAddress for SparkDriver) to the correct binding address. [info] at sun.nio.ch.Net.bind0(Native Method) [info] at sun.nio.ch.Net.bind(Net.java:461) [info] at sun.nio.ch.Net.bind(Net.java:453) ``` https://github.com/apache/spark/pull/32090/checks?check_run_id=2295418529 Fix test framework. No. Test by Github Action. Closes apache#32096 from wangyum/SPARK_LOCAL_IP=localhost. Authored-by: Yuming Wang <yumwang@ebay.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com> (cherry picked from commit 9663c40) Signed-off-by: HyukjinKwon <gurwls223@apache.org>
… SPARK_LOCAL_IP in GA builds This PR replaces 127.0.0.1 to `localhost`. - apache#32096 (comment) - apache#32096 (comment) No, dev-only. I didn't test it because it's CI specific issue. I will test it in Github Actions build in this PR. Closes apache#32102 from HyukjinKwon/SPARK-35002. Authored-by: HyukjinKwon <gurwls223@apache.org> Signed-off-by: Yuming Wang <yumwang@ebay.com> (cherry picked from commit a3d1e00) Signed-off-by: HyukjinKwon <gurwls223@apache.org>
…ResponseHandler ### What changes were proposed in this pull request? There is a potential Netty memory leak in TransportResponseHandler. ### Why are the changes needed? Fix a potential Netty memory leak in TransportResponseHandler. ### Does this PR introduce _any_ user-facing change? NO ### How was this patch tested? NO Closes apache#31942 from weixiuli/SPARK-34834. Authored-by: weixiuli <weixiuli@jd.com> Signed-off-by: Sean Owen <srowen@gmail.com> (cherry picked from commit bf9f3b8) Signed-off-by: Sean Owen <srowen@gmail.com>
…ll__ ### What changes were proposed in this pull request? This patch add `__version__` into pyspark.__init__.__all__ to make the `__version__` as exported explicitly, see more in apache#32110 (comment) ### Why are the changes needed? 1. make the `__version__` as exported explicitly 2. cleanup `noqa: F401` on `__version` ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Python related CI passed Closes apache#32125 from Yikun/SPARK-34629-Follow. Authored-by: Yikun Jiang <yikunkero@gmail.com> Signed-off-by: zero323 <mszymkiewicz@gmail.com> (cherry picked from commit 31555f7) Signed-off-by: zero323 <mszymkiewicz@gmail.com>
…edImperativeAggregate
Currently,
```
val namedObservation = Observation("named")
val df = spark.range(100)
val observed_df = df.observe(
namedObservation, percentile_approx($"id", lit(0.5), lit(100)).as("percentile_approx_val"))
observed_df.collect()
namedObservation.get
```
throws exception as follows:
```
15:16:27.994 ERROR org.apache.spark.util.Utils: Exception encountered
java.io.NotSerializableException: org.apache.spark.sql.catalyst.expressions.aggregate.ApproximatePercentile$PercentileDigest
at java.io.ObjectOutputStream.writeObject0(ObjectOutputStream.java:1184)
at java.io.ObjectOutputStream.defaultWriteFields(ObjectOutputStream.java:1548)
at java.io.ObjectOutputStream.writeSerialData(ObjectOutputStream.java:1509)
at java.io.ObjectOutputStream.writeOrdinaryObject(ObjectOutputStream.java:1432)
at java.io.ObjectOutputStream.writeObject0(ObjectOutputStream.java:1178)
at java.io.ObjectOutputStream.writeArray(ObjectOutputStream.java:1378)
at java.io.ObjectOutputStream.writeObject0(ObjectOutputStream.java:1174)
at java.io.ObjectOutputStream.defaultWriteFields(ObjectOutputStream.java:1548)
at java.io.ObjectOutputStream.writeSerialData(ObjectOutputStream.java:1509)
at java.io.ObjectOutputStream.writeOrdinaryObject(ObjectOutputStream.java:1432)
at java.io.ObjectOutputStream.writeObject0(ObjectOutputStream.java:1178)
at java.io.ObjectOutputStream.defaultWriteFields(ObjectOutputStream.java:1548)
at java.io.ObjectOutputStream.writeSerialData(ObjectOutputStream.java:1509)
at java.io.ObjectOutputStream.writeOrdinaryObject(ObjectOutputStream.java:1432)
at java.io.ObjectOutputStream.writeObject0(ObjectOutputStream.java:1178)
at java.io.ObjectOutputStream.writeObject(ObjectOutputStream.java:348)
at org.apache.spark.scheduler.DirectTaskResult.$anonfun$writeExternal$2(TaskResult.scala:55)
at org.apache.spark.scheduler.DirectTaskResult.$anonfun$writeExternal$2$adapted(TaskResult.scala:55)
at scala.collection.Iterator.foreach(Iterator.scala:943)
at scala.collection.Iterator.foreach$(Iterator.scala:943)
at scala.collection.AbstractIterator.foreach(Iterator.scala:1431)
at scala.collection.IterableLike.foreach(IterableLike.scala:74)
at scala.collection.IterableLike.foreach$(IterableLike.scala:73)
at scala.collection.AbstractIterable.foreach(Iterable.scala:56)
at org.apache.spark.scheduler.DirectTaskResult.$anonfun$writeExternal$1(TaskResult.scala:55)
at scala.runtime.java8.JFunction0$mcV$sp.apply(JFunction0$mcV$sp.java:23)
at org.apache.spark.util.Utils$.tryOrIOException(Utils.scala:1434)
at org.apache.spark.scheduler.DirectTaskResult.writeExternal(TaskResult.scala:51)
at java.io.ObjectOutputStream.writeExternalData(ObjectOutputStream.java:1459)
at java.io.ObjectOutputStream.writeOrdinaryObject(ObjectOutputStream.java:1430)
at java.io.ObjectOutputStream.writeObject0(ObjectOutputStream.java:1178)
at java.io.ObjectOutputStream.writeObject(ObjectOutputStream.java:348)
at org.apache.spark.serializer.JavaSerializationStream.writeObject(JavaSerializer.scala:44)
at org.apache.spark.serializer.JavaSerializerInstance.serialize(JavaSerializer.scala:101)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:616)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
```
This PR will fix the issue. After the change,
`assert(namedObservation.get === Map("percentile_approx_val" -> 49))`
`java.io.NotSerializableException` will not happen.
Fix `NotSerializableException` when observe with `TypedImperativeAggregate`.
No. This PR change the implement of `AggregatingAccumulator` who uses serialize and deserialize of `TypedImperativeAggregate` now.
New tests.
Closes apache#34474 from beliefer/SPARK-37203.
Authored-by: Jiaan Geng <beliefer@163.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
(cherry picked from commit 3f3201a)
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
For case
```
withTempDir { dir =>
withSQLConf(HiveUtils.CONVERT_METASTORE_PARQUET.key -> "false") {
withTable("test_precision") {
val df = sql("SELECT 'dummy' AS name, 1000000000000000000010.7000000000000010 AS value")
df.write.mode("Overwrite").parquet(dir.getAbsolutePath)
sql(
s"""
|CREATE EXTERNAL TABLE test_precision(name STRING, value DECIMAL(18,6))
|STORED AS PARQUET LOCATION '${dir.getAbsolutePath}'
|""".stripMargin)
checkAnswer(sql("SELECT * FROM test_precision"), Row("dummy", null))
}
}
}
```
We write a data with schema
It's caused by you create a df with
```
root
|-- name: string (nullable = false)
|-- value: decimal(38,16) (nullable = false)
```
but create table schema
```
root
|-- name: string (nullable = false)
|-- value: decimal(18,6) (nullable = false)
```
This will cause enforcePrecisionScale return `null`
```
public HiveDecimal getPrimitiveJavaObject(Object o) {
return o == null ? null : this.enforcePrecisionScale(((HiveDecimalWritable)o).getHiveDecimal());
}
```
Then throw NPE when call `toCatalystDecimal `
We should judge if the return value is `null` to avoid throw NPE
Fix bug
No
Added UT
Closes apache#34519 from AngersZhuuuu/SPARK-37196.
Authored-by: Angerszhuuuu <angers.zhu@gmail.com>
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
(cherry picked from commit a4f8ffb)
Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
…environment ### What changes were proposed in this pull request? This PR aims to ignore `test_memory_limit` on non-Linux environment. ### Why are the changes needed? Like the documentation apache#23664, it fails on non-Linux environment like the following MacOS example. **BEFORE** ``` $ build/sbt -Phadoop-cloud -Phadoop-3.2 test:package $ python/run-tests --modules pyspark-core ... ====================================================================== FAIL: test_memory_limit (pyspark.tests.test_worker.WorkerMemoryTest) ---------------------------------------------------------------------- Traceback (most recent call last): File "/Users/dongjoon/APACHE/spark-merge/python/pyspark/tests/test_worker.py", line 212, in test_memory_limit self.assertEqual(soft_limit, 2 * 1024 * 1024 * 1024) AssertionError: 9223372036854775807 != 2147483648 ---------------------------------------------------------------------- ``` **AFTER** ``` ... Tests passed in 104 seconds Skipped tests in pyspark.tests.test_serializers with /Users/dongjoon/.pyenv/versions/3.8.12/bin/python3: test_serialize (pyspark.tests.test_serializers.SciPyTests) ... skipped 'SciPy not installed' Skipped tests in pyspark.tests.test_worker with /Users/dongjoon/.pyenv/versions/3.8.12/bin/python3: test_memory_limit (pyspark.tests.test_worker.WorkerMemoryTest) ... skipped "Memory limit feature in Python worker is dependent on Python's 'resource' module on Linux; however, not found or not on Linux." ``` ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Manual. Closes apache#34527 from dongjoon-hyun/SPARK-37252. Authored-by: Dongjoon Hyun <dongjoon@apache.org> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> (cherry picked from commit 2c7f201) Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
…tb_frame.f_lineno` is None ### What changes were proposed in this pull request? This PR aims to handle the corner case when `tb_frame.f_lineno` is `None` in `try_simplify_traceback` which was added by apache#30309 at Apache Spark 3.1.0. ### Why are the changes needed? This will handle the following corner case. ```python Traceback (most recent call last): File "/Users/dongjoon/APACHE/spark-merge/python/lib/pyspark.zip/pyspark/worker.py", line 630, in main tb = try_simplify_traceback(sys.exc_info()[-1]) File "/Users/dongjoon/APACHE/spark-merge/python/lib/pyspark.zip/pyspark/util.py", line 217, in try_simplify_traceback new_tb = types.TracebackType( TypeError: 'NoneType' object cannot be interpreted as an integer ``` Python GitHub Repo also has the test case for this corner case. - https://github.com/python/cpython/blob/main/Lib/test/test_exceptions.py#L2373 ```python None if frame.f_lineno is None else ``` ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? N/A Closes apache#34530 from dongjoon-hyun/SPARK-37253. Authored-by: Dongjoon Hyun <dongjoon@apache.org> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> (cherry picked from commit 8ae88d0) Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
### What changes were proposed in this pull request?
This PR changes since annotation to support `float` arguments:
```python
def since(version: Union[str, float]) -> Callable[[T], T]: ...
```
### Why are the changes needed?
`since` is used with both `str` and `float` both in Spark and related libraries and this change has been already done for Spark >= 3.3 (SPARK-36906),
Note that this technically fixes a bug in the downstream projects that run mypy checks against `pyspark.since`. When they use it, for example, with `pyspark.since(3.2)`, mypy checks fails; however, this case is legitimate. After this change, the mypy check can pass in thier CIs.
### Does this PR introduce _any_ user-facing change?
```python
since(3.2)
def f():
...
```
is going to type check if downstream projects run mypy to validate the types.
Otherwise, it does not affect anything invasive or user-facing behavior change.
### How was this patch tested?
Existing tests and manual testing.
Closes apache#34555 from zero323/SPARK-37288.
Authored-by: zero323 <mszymkiewicz@gmail.com>
Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
(cherry picked from commit bdde693)
Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
…st in DepsTestsSuite finishes ### What changes were proposed in this pull request? This PR fixes an issue that `py_container_checks.zip` still remains in `resource-managers/kubernetes/integration-tests/tests/` even after the test `Launcher python client dependencies using a zip file` in `DepsTestsSuite` finishes. ### Why are the changes needed? To keep the repository clean. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Confirmed that the zip file will be removed after the test finishes with the following command using MiniKube. ``` PVC_TESTS_HOST_PATH=/path PVC_TESTS_VM_PATH=/path build/mvn -Dspark.kubernetes.test.namespace=default -Pkubernetes -Pkubernetes-integration-tests -pl resource-managers/kubernetes/integration-tests integration-test ``` Closes apache#34588 from sarutak/remove-zip-k8s. Authored-by: Kousuke Saruta <sarutak@oss.nttdata.com> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> (cherry picked from commit d8cee85) Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
### What changes were proposed in this pull request? This PR aims to make `run_scala_tests` respect test module order ### Why are the changes needed? Currently the execution order is random. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Manually through the following and check if the catalyst module runs first. ``` $ SKIP_MIMA=1 SKIP_UNIDOC=1 ./dev/run-tests --parallelism 1 --modules "catalyst,hive-thriftserver" ``` Closes apache#34590 from williamhyun/order. Authored-by: William Hyun <william@apache.org> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> (cherry picked from commit c2221a8) Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
### What changes were proposed in this pull request? This PR aims to ping `docutils` to `0.17.x` to recover branch-3.1 GitHub Action linter job. ### Why are the changes needed? `docutils` 0.18 is released October 26 and causes Python linter failure in branch-3.1. - https://pypi.org/project/docutils/#history - https://github.com/apache/spark/commits/branch-3.1 ``` Exception occurred: File "/__t/Python/3.6.15/x64/lib/python3.6/site-packages/docutils/writers/html5_polyglot/__init__.py", line 445, in section_title_tags if (ids and self.settings.section_self_link AttributeError: 'Values' object has no attribute 'section_self_link' The full traceback has been saved in /tmp/sphinx-err-y2ttd83t.log, if you want to report the issue to the developers. Please also report this if it was a user error, so that a better error message can be provided next time. A bug report can be filed in the tracker at <https://github.com/sphinx-doc/sphinx/issues>. Thanks! make: *** [Makefile:20: html] Error 2 Error: Process completed with exit code 2. ``` ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Pass the linter job on this PR. Closes apache#34591 from dongjoon-hyun/SPARK-37323. Authored-by: Dongjoon Hyun <dongjoon@apache.org> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
|
Can one of the admins verify this patch? |
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
20 participants
Add this suggestion to a batch that can be applied as a single commit.This suggestion is invalid because no changes were made to the code.Suggestions cannot be applied while the pull request is closed.Suggestions cannot be applied while viewing a subset of changes.Only one suggestion per line can be applied in a batch.Add this suggestion to a batch that can be applied as a single commit.Applying suggestions on deleted lines is not supported.You must change the existing code in this line in order to create a valid suggestion.Outdated suggestions cannot be applied.This suggestion has been applied or marked resolved.Suggestions cannot be applied from pending reviews.Suggestions cannot be applied on multi-line comments.Suggestions cannot be applied while the pull request is queued to merge.Suggestion cannot be applied right now. Please check back later.
What changes were proposed in this pull request?
Add timeoutExecutor shutdown method in SparkExecuteStatementOperation and shut down when statement finished or error.
Why are the changes needed?
When spark.sql.thriftServer.queryTimeout or java.sql.Statement.setQueryTimeout is setted >0 , SparkExecuteStatementOperation add timeoutExecutor to kill time-consumed query in SPARK-26533. But timeoutExecutor is not shutdown correctly when statement is finished, it can only be shutdown when timeout. When we set timeout to a long time for example 1 hour, the long-running STS driver will FullGC and the application is not available for a long time.
Does this PR introduce any user-facing change?
NO
How was this patch tested?